



 本文分享了作者从依赖Google的预训练语言模型到自训ALBERT模型的心路历程,包括数据准备、模型训练及超参数调整等关键环节,特别强调了针对特定领域和任务优化的重要性。
本文分享了作者从依赖Google的预训练语言模型到自训ALBERT模型的心路历程,包括数据准备、模型训练及超参数调整等关键环节,特别强调了针对特定领域和任务优化的重要性。
起初,我和大部分人一样,使用的是像Google这样的大公司提供的Pre-training Language Model。用起来也确实方便,随便接个下游任务,都比自己使用Embedding lookup带来的模型效果要好。但是时间用长了,就会产生依赖。
依赖只是一方面,还有一个更大的问题,是我们需要思考的,他们提供的Pre-training LM确实很好吗?适合我们使用吗?
一方面,它的大小适合使用吗?在BERT预训练语言模型刚出来时,最小的模型都是Base版的,它的hidden_size为768,占用内存大小为400M。另一方面,它真的好吗?其实,它只是一个普通的通用语言模型,并没有什么特殊之处,也没有为语料做过一些特殊的预处理。下面有几个例子:
- 例1,模型大小的选择。一般情况下,任意接一个下游任务,最后得到的模型大小都有1G多。对一些大学生而言,特别是一些没有GPU资源的小伙伴而言,就像一块天鹅肉。
- 例2,特定领域。如果我的领域是医疗领域,那么Google提供的语言模型可能表现得并不会很优异。
- 例3,特定NLP任务。如果我的NLP任务是基于短句的,那么基于长句训练的语言模型表现也会差一点。
- 例4,数据集的选择。选取一份数据量更大、覆盖面更广、质量更优、预处理更好的数据集,会让语言模型在NLP任务中有更好的表现。
- 例5,MASK数量和训练总步数。我们看过RoBERTa这篇论文后,可以知道MASK更加随机,以及训练更长的步数,会给模型带来更好的效果。
下面,我会介绍下整个预训练过程中遇到的一些问题,以及如何克服这些问题。
一、数据准备
数据准备这一块的工作花费了较长的时间。
一方面,数据收集。考虑到最后训练得到的模型的通用性以及可持续性,所以收集的数据需要尽可能地覆盖更多的领域。另外,我的NLP任务中,很多是特定领域内的。所以,在收集了通用数据18.3G的前提下,额外补充了2.2G的特定领域数据。数据链接:https://zhuanlan.zhihu.com/p/163616279
另一方面,数据处理。数据处理主要有2个工作。第1个,需要将收集的数据处理成可直接读取并训练的格式。如下所示,我们需要将图1或者其它形式的数据都转为图2形式的数据。




第2个,需要将图2中的数据转为可供ALBERT使用的格式,如下图3所示:
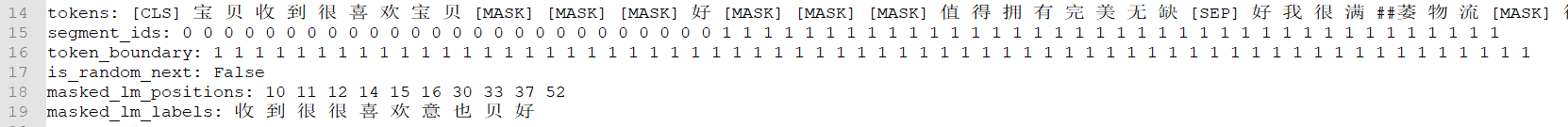
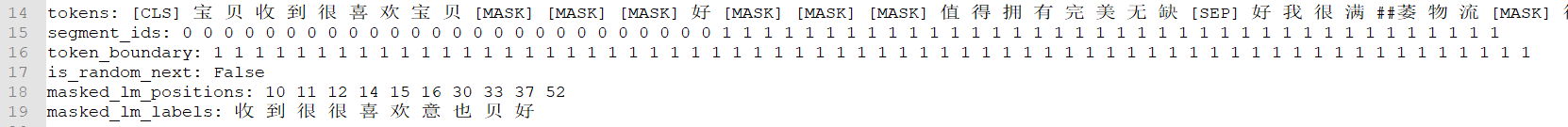
然后,将图3的数据转为tfrecord格式存储在本地。这里就会遇到一些问题,以及一些tricks。那么会有什么问题呢?首先,如果直接使用Google提供的预训练代码,一次性将所有的数据全部转化为图3的格式,然后存储在本地。这个过程中,首先一般电脑的显存肯定不够使用,因为20G的数据转为图3的格式后会变为1400G左右的大小,这个是在duplicate次数为10的情况下(10种不同的MASK)。代码所示:


显然,一般的电脑显存大小肯定没有1400G,甚至有些电脑的硬盘大小也没有1400G。那么,这个时候,就需要优化Google提供的预训练代码了。我的做法是,一方面将所有的数据拆分为很多个txt文件,其中每个文件包含1w个句子/文章;另一方面,生成tfrecord的方式是一遍读取文本一遍生成tfrecord,而不是一次性读取所有的文本。这个过程的代码如下:
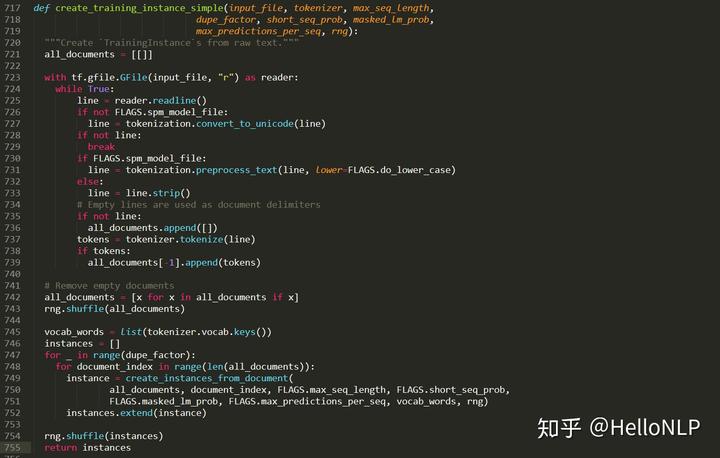
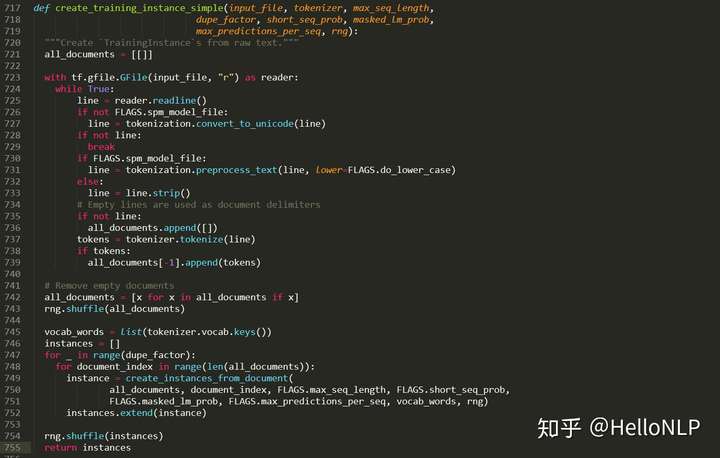
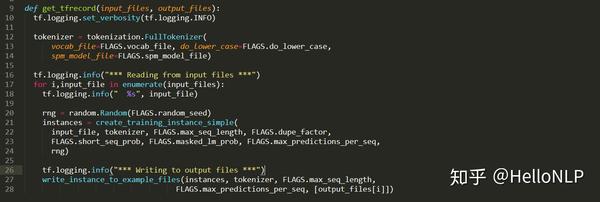
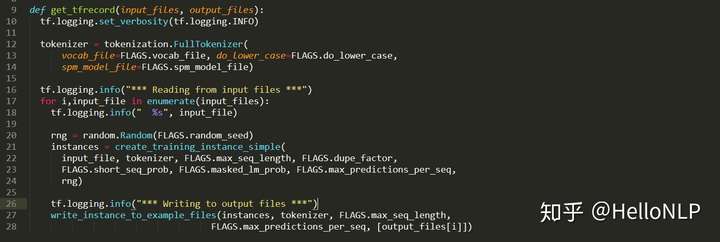
上面图4中的code解决的是将单个txt文本转化为tfrecord的方式,图5解决的是历遍每一个txt文件并保存到本地。除此之外,为了确保数据的随机性,在生成txt文件时,做了4次随机化全部文本数据,并将每一次随机生成的文本数据按照1w的大小切分并保存到本地。
之前读了RoBERTa这篇论文,发现了3个有用的tricks,分别是更多的随机MASK、更长的训练步数和更多的训练数据。
现在,我们介绍下数据的演变过程,主要有以下6个步骤:
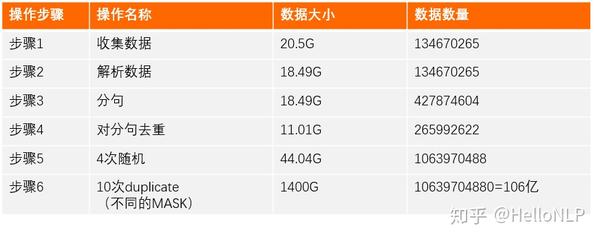
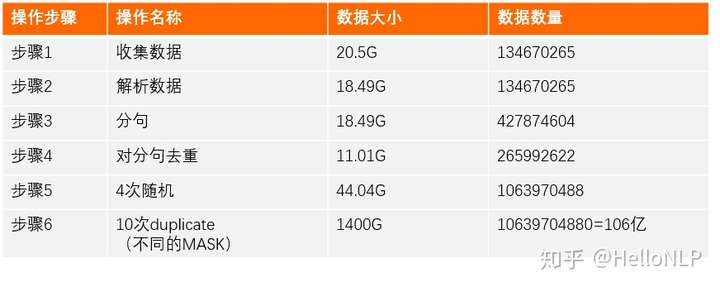
我们可以看到,最后有106亿个样本。相比Google的125000*4096=5亿样本,以及brightmart的20个样本,我们训练的样本量要大很多,主要是原因是我们做了分句处理和添加了新的数据。在整个数据演变的过程中,步骤6花费了较长的时间,在10个进程的情况下,花了一个星期才完成。
如果也有想做预训练的小伙伴,首先要准备一个大的硬盘,至少能够存储2T的数据。
二、模型训练
1、框架选择
对比了好几个预训练模型,发现还是ALBERT最好。同时引入了RoBERTa的几个tricks(更多的随机MASK、更长的训练步数和更多的训练数据)。
2、超参数
训练的样本量越大,意味着训练的时间也会越久。由于GPU资源有限,只有2卡1080Ti,所以我首先会进行一个hidden_size为384、sequence_length为64、batch_size为768的预训练,然后会依次训练hidden_size分别为512、768的预训练。
3、训练时间
那现在评估一下训练时间。以最小的hidden_size=768为例,训练的步数最少需要1063970488/768=1385w步。按照目前机器的训练速度,大概需要90天才能训练完成。当然,也不一定要完全训练完所有的数据,在训练了一半的steps之后,基本上可以使用了。到时候,8月中旬时,我会向大家开放这个预训练语言模型。那时,对NLP任务为短句(NER,短句文本分类等)的小伙伴,我相信会对你们的模型效果有一个较大的提升;以及对电商领域的NLP任务的模型效果也会有一个提升。
模型训练是一个漫长的过程,谁让我们没有money呢,不过等待也是幸福的时刻。不过,如果能有32卡、64卡或者更多,那简直就爽歪歪了,此处全靠想象。。。
总而言之,至少我们做到了,在没有那些寡头的帮助下,我们也能创造一片新的天地!
三、字典修改
在开源的ALBERT项目目录下,已经有了一个通用的字典vocab.txt。但是,对于有些小伙伴来说,可能并不够用,例如我想添加一些英文单词以及一些不常用的汉字。另外,在字典中添加新的token时,不仅仅要添加整个新的token,同时也需要添加这个token作为句子首个字时的token。例如,如果我要添加一个法语单词"vie",那么,需要同时添加"##vie",这里的两个"#"指示的是句子/文章的第一个字。我们可以看下代码的解释:


四、开源预训练模型
Waiting!
另外,我已经在小规模的数据上做了一次预训练,所有模型(文本分类,多标签文本分类)的效果都提升了0.5%-1%之间。



















 127
127




 到【灌水乐园】发言
到【灌水乐园】发言







