




 本文详细介绍使用Python库如pdfplumber和fitz进行PDF文件的处理,包括表格信息的提取,并分享了提高PDF阅读清晰度的方法。通过代码示例展示了如何将PDF中的表格转换为Excel格式。
本文详细介绍使用Python库如pdfplumber和fitz进行PDF文件的处理,包括表格信息的提取,并分享了提高PDF阅读清晰度的方法。通过代码示例展示了如何将PDF中的表格转换为Excel格式。
20220109
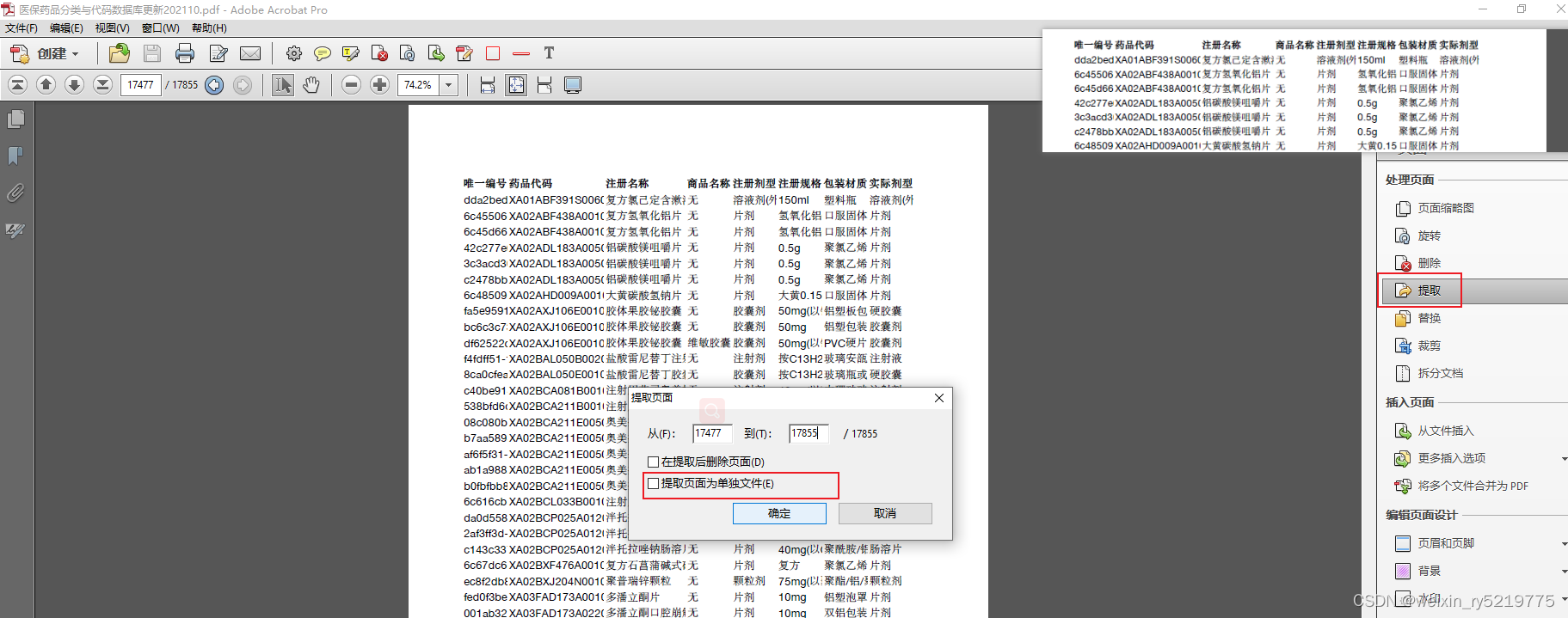
pdf拆分
不要点提取页面为单独文件 这样会提取出完整的一个文件
而如果选了的话会全部拆分成一页一页
20220107
# code=utf-8
import os
import time
import sys
import fitz
import pdfplumber
from openpyxl import Workbook
from tqdm import tqdm
PATH = r'D:\project_pycharm\medicine_standard_lib/'
def analysis_table(pdf_file):
# 打开表格
workbook = Workbook()
sheet = workbook.active
# 打开pdf
with pdfplumber.open(pdf_file) as pdf:
# 遍历每页pdf
for page in tqdm(pdf.pages):
# 提取表格信息
table = page.extract_table()
# print(table)
# 格式化表格数据
for row in table:
# print(row)
sheet.append(row)
workbook.save(filename="医保药品分类与代码数据库更新202110.pdf.xlsx")
analysis_table(PATH+'医保药品分类与代码数据库更新202110.pdf')
抽取表格
https://blog.youkuaiyun.com/wxplol/article/details/109304946
基于pymupdf的PDF的文本、图片和表格信息提取
https://mp.weixin.qq.com/s/59UiYl1AJh-kWQOCeeIMHA
各种pdf解析库
https://www.jianshu.com/p/d38f2a582aa8
Python实现PDF内容抽取PyMuPDF
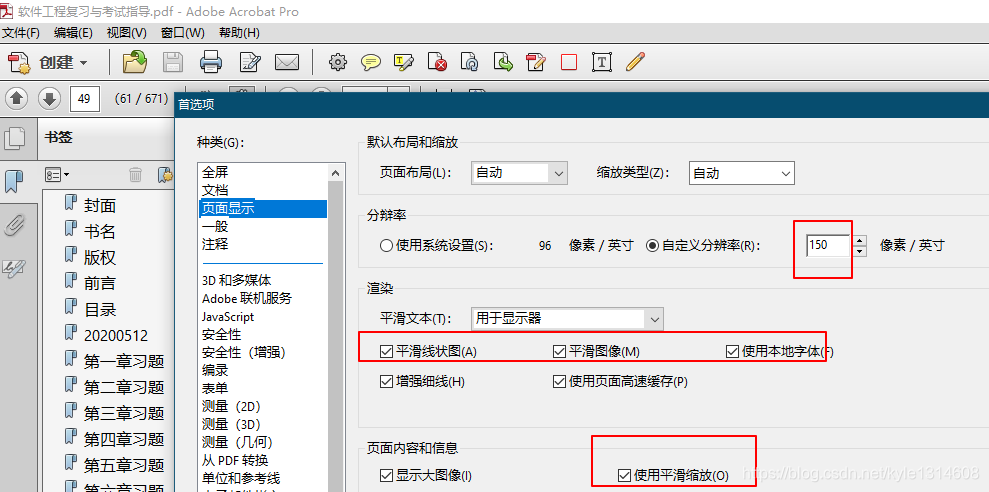
平滑的地方都选上
自定义分辨率
或者用2345 pdf阅读器 很清晰
可以调节显示器的 clear vision 来调节对比度 增加显示效果
模糊的pdf文档会变的清晰
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
</div>
<!--一个博主专栏付费入口-->
<!--一个博主专栏付费入口结束-->
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-4a3473df85.css">
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-4a3473df85.css">
<div class="htmledit_views" id="content_views">
<p><strong>AdobeAcrobat是一款不错的pdf编辑阅读器,大家常用来阅读文献资料,但是在安装完成使用时候,常常出现页面字体不清晰的情况,需要做一下调整:</strong></p>
(1)打开AdobeAcrobat属性中的兼容性设置界面(右击桌面AdobeAcrobat的图标,选择属性,点击兼容性)
(2)对兼容性做如下设置,调整成为程序自动使用高DPI

(3)打开AdobeAcrobat,选择编辑——首选项——页面设置,将分辨率调整成为使用系统设置,渲染部分的平滑文本选择用于显示器,其他的默认打钩。页面布局和缩放类型可以自己调整了看,这里选择自动。

(4)重启AdobeAcrobat即可



















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









