



 本文深入探讨正则表达式的各种特性,包括转义字符、分组、预搜索、递归匹配等高级用法,以及如何利用这些特性进行精确的文本匹配。
本文深入探讨正则表达式的各种特性,包括转义字符、分组、预搜索、递归匹配等高级用法,以及如何利用这些特性进行精确的文本匹配。
20220717

第一个斜杠表示转义,第二个斜杠表示把转义转成本义
20220110
a = '你好/啊'
b = re.sub(r'/','*',a)
反斜杠替换
20210610
https://mp.weixin.qq.com/s/amaYB0Z_r8wbbjHHk3vshg
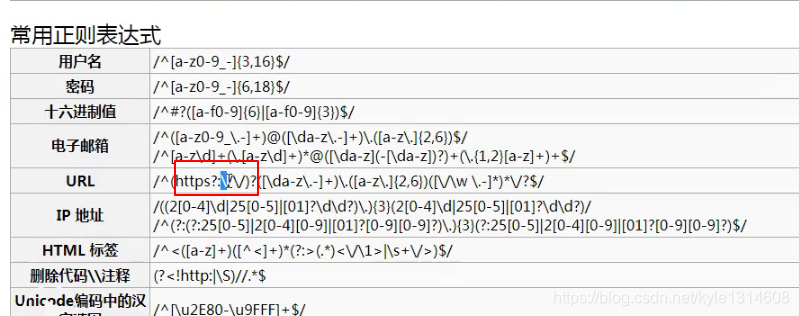
最强整理!常用正则表达式速查手册
20210323
"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?“只匹配单个"o”,而"o+“匹配所有"o”。
正则日常电脑搜索
.{0,5}人工智能.{0,5}笔记
df[‘体重’] = df[‘体重’].apply(lambda x: re.sub(r’[^\d.]‘,’', x))
sub 和replace 功能类似
匹配小数点 不需要加斜杠?
重点:分清哪些是固定一定要的,哪些是不需要捕获的
并且分类匹配 分类从最高层开始想
把经常连在一起的分成一类 比如 那个小区 幢 单元 号
省市区县等 分成两类
import re
a=‘www.baidu.com/num’
b=re.findall(‘www.baidu.com/.*’,a)
b
转义是反斜杠!!!
在r 的正则式中\本来是特殊意义的,再加一个反斜杠就是把
其变成本身的反斜杠意义了
转义是反斜杠!!! \ “/“”这个是斜杠
findall 匹配什么就输出什么而不是序号
匹配到的结果列表=re.findall(r’正则字符串’,要匹配的字符串,re.I|re.S)
re.I,表示忽略大小写
re.S,表示忽略回行,所有字符包括回行字符
s1=re.findall(r’(?=String|Float|Integer)(?P\w+)\s+(?P.?)\s?=\s*?(?P.?)\s?;',str,re.I|re.S)
分组: type name value 可以自由命名
正则表达式在整个表达式是连续的!!!!!!!!!!
转义字符 \Q…\E
使用 \Q 开始,\E 结束,可使中间的标点符号失去特殊意义,将中间的字符作为普通字符。
使用 \U 开始,\E 结束,除了具有 \Q…\E 相同的功能外,还将中间的小写字母转换成大写。在大小写敏感模式下,只能与大写文本匹配。
使用 \L 开始,\E 结束,除了具有 \Q…\E 相同的功能外,还将中间的大写字母转换成小写。在大小写敏感模式下,只能与小写文本匹配。
说明
\Q…\E 适合用于:表达式中需要比较长的普通文本,而其中包含了特殊符号。
举例
表达式
说明
\Q(a+b)*3\E
可匹配文本 “(a+b)*3”。
(a+b)*3
如果不使用 \Q…\E 进行转义,则对每个特殊符号进行转义。
自定义字符集合 [ ]
用中括号 [ ] 包含多个字符,可以匹配所包含的字符中的任意一个。同样,每次只能匹配其中一个。
用中括号 [^ ] 包含多个字符,构成否定格式,可以匹配所包含的字符之外的任意一个字符。
说明
正则表达式中的特殊符号,如果被包含于中括号中,则失去特殊意义,但 \ [ ] : ^ - 除外。
标准字符集合,除小数点(.)外,如果被包含于中括号中,自定义字符集合将包含该集合。
比如:[\d.-+],将可以匹配数字,小数点和 + - 符号。(小数点和 + 号失去特殊意义)
用减号相连的 2 个普通字符,自定义字符集合将包含该范围。
比如:[\dA-Fa-f],将可以匹配 0 - 9, A - F, a - f。
自定义字符集合可以包含 POSIX 字符集合。
不管正则表达式匹配模式是否是 IGNORECASE,字符集合在匹配时,都是要区分大小写的。更多详情,参见正则表达式匹配模式。
匹配次数限定符
使被修饰的表达式可多次重复匹配的修饰符。
说明
可使被修饰的表达式重复固定次数,也可以限定一定的重复匹配的次数范围。
在限定符之后的表达式能够匹配成功的情况下,不定次数的限定符总是尽可能的多匹配。如果之后的表达式匹配失败,限定符可适当“让出”能够匹配的字符,以使整个表达式匹配成功。这种模式就叫“贪婪模式”。
限定符
说明
{n}
表达式固定重复n次,比如:“\w{2}” 相当于 “\w\w”
{m, n}
表达式尽可能重复n次,至少重复m次:"ba{1,3}"可以匹配 “ba"或"baa"或"baaa”
{m, }
表达式尽可能的多匹配,至少重复m次:"\w\d{2,}"可以匹配 “a12”,“x456”…
?
表达式尽可能匹配1次,也可以不匹配,相当于 {0, 1}
表达式尽可能的多匹配,至少匹配1次,相当于 {1, }
表达式尽可能的多匹配,最少可以不匹配,相当于 {0, }
“勉强模式”限定符:
在限定符之后添加问号(?),则使限定符成为“勉强模式”。勉强模式的限定符,总是尽可能少的匹配。如果之后的表达式匹配失败,勉强模式也可以尽可能少的再匹配一些,以使整个表达式匹配成功。
限定符
说明
{m, n}?
表达式尽量只匹配m次,最多重复n次。
{m, }?
表达式尽量只匹配m次,最多可以匹配任意次。
??
表达式尽量不匹配,最多匹配1次,相当于 {0, 1}?
+?
表达式尽量只匹配1次,最多可匹配任意次,相当于 {1, }?
*?
表达式尽量不匹配,最多可匹配任意次,相当于 {0, }?
“占有模式”限定符:
在限定符之后添加加号(+),则使限定符成为“占有模式”。占有模式的限定符,总是尽可能多的匹配。与“贪婪模式”不同的是,即使之后的表达式匹配失败,“占有模式”也不会“让出”自己能够匹配的字符。
限定符
说明
{m, n}+
表达式尽可能重复n次,至少重复m次。
{m, }+
表达式尽可能的多匹配,至少重复m次。
?+
表达式尽可能匹配1次,也可以不匹配,相当于 {0, 1}+
++
表达式尽可能的多匹配,至少匹配1次,相当于 {1, }+
*+
表达式尽可能的多匹配,最少可以不匹配,相当于 {0, }+
字符边界
本身不匹配任何字符,只对字符边界和字符间缝隙附加条件的表达式。
说明
有些正则表达式中的符号,可以对文本中当前所在位置作限制条件:
边界条件
说明
^
当前位置必须是文本开始位置
$
当前位置必须是文本结束位置
\b
当前位置的左右两侧,只能有一侧是字母数字或下划线
如果正则表达式的匹配模式为 MULTILINE 模式,^ 可匹配一行文本的行首,$ 可匹配一行文本的行末。更多详情,参见正则表达式匹配模式。
当 \b 被包含于字符集合中时,\b 代表退格符(ASCII码 = 8)。
分组 ( )
用括号 ( ) 将其他表达式包含,可以使被包含的表达式组成一个整体,在被修饰匹配次数时,可作为整体被修饰。
另外,用括号包含的表达式,所匹配到的内容将单独作记录,匹配过程中或结束后可以被获取。
说明
每一对括号会分配一个编号,使用 () 的捕获根据左括号的顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本。
命名分组 (?xxx)
与普通分组一样的功能,并且将匹配的子字符串捕获到一个组名称或编号名称中。
在获得匹配结果时,可通过分组名进行获取。
说明
命名捕获根据左括号的从左到右的顺序按顺序编号(与非命名捕获类似),但在对所有非命名捕获进行计数之后才开始对命名捕获进行编号。
DEELX 允许多个命名分组的名字相同,这时它们捕获到的内容会放在同一个分组编号下。在逻辑上,它们是同一个分组。
如果两个命名相同分组之间有包含关系,那么被包含的那个分组将不进行捕获。
反向引用 \nnn
对指定分组已捕获的字符串进行引用,要求文本中当前位置开始的字符串,必须和指定分组捕获到的字符串一致。
说明
DEELX 支持的反向引用格式:
反向引用
说明
\nnn
对指定编号的分组进行反向引用
\g
对指定名字的命名分组进行反向引用
\k
\k’name’
另外,如果被引用的捕获组(括号对)未进行捕获时,则该反向引用将匹配失败。
DEELX 最多将 3 位数字识别为反向引用,如果想在表达式中表示 \1 外加一个字符 2 ,那么应该写成 \0012。在 DEELX 中,不管是否有第 12 对括号,写成 \12 都表示对第 12 对括号的引用。
DEELX 不将 \nnn 格式识别为 8 进制数,参见简单的转义字符。
注释 (?#xxx)
格式 (?# xxx ) 可用来表示一段注释。
说明
注释可以位于表达式中任意地方,但不可以出现在转义字符(\)与被转移字符中间。比如:(?# xxx )w 是不可以的,这样写的效果实际上是第一个括号被转义成普通字符了。
在 (?# 之后,遇到第一个反括号将表示注释结束。因此,想把注释写成 (?# x()xx ) 或者 (?# x)xx ) 都是不可以的。注释中的反斜杠(\),不代表转义字符。
非捕获组 (?:xxx)
使用 (?: ) 包含其他表达式,可使被包含的表达式组成一个整体,在被修饰匹配次数时,可作为整体被修饰。
说明
与普通分组不同的是,非捕获组不记录所匹配的内容,比普通分组更节约内存资源。
通过格式 (?ismg-ismg:xxx) 可对匹配模式进行修改,修改后的模式只对当前非捕获组内部起作用。
预搜索(令宽度断言)
判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符。
说明
预搜索有向前和向后两种:
表达式
方向
说明
(?=xxx)
正向预搜索(向右)
正向预搜索,判断当前位置右侧是否能匹配指定表达式
(?!xxx)
正向预搜索否定,判断当前位置右侧是否不能够匹配指定表达式
(?<=xxx)
反向预搜索(向左)
反向预搜索,判断当前位置左侧是否能够匹配指定表达式
(?<!xxx)
反向预搜索否定,判断当前位置左侧是否不能够匹配指定表达式
在 DEELX 中,不管整个表达式是“普通模式”还是“从右向左”模式,正向预搜索内部的表达式,始终采用“普通模式(从左向右)”模式,反向预搜索内部的表达式,始终采用“从右向左”模式。
独立表达式 (?>pattern)
独立表达式所匹配的内容,与将它单独匹配时匹配的内容一致。不管之后的表达式是否匹配成功,独立表达式内部都不进行回退,都不会再次尝试匹配。
说明
相比之下,如果 pattern 不是位于独立表达式中,当后边的表达式匹配失败时,pattern 所包含的不定次数的表达式(?, +, {n,m}, ……)会尝试改变匹配次数,选择表达式(比如:a|b)也会尝试匹配另一个选项,再次进行匹配,以尽量使整个表达式能够匹配成功。
条件表达式
根据某个条件是否成立,来选择匹配 2 个可选表达式中的其中一个。
说明
可以用于条件表达式的条件有两种类型:
指定分组(group)是否进行了捕获。
文本中当前位置是否可以与指定表达式匹配。
条件表达式的格式及说明:
表达式
条件特点
条件说明
(?(1)yes|no)
条件为数字
分组1如果有捕获,则进行 yes 部分匹配,否则 no 部分
(?(?=a)aa|bbb)
条件为预搜索
如果当前位置右侧是 a,则进行匹配 aa,否则匹配 bbb
(?(xxx)aa|bbb)
不与分组命名吻合
如果不与任何分组命名吻合,则视为 (?=xxx) 相同
(?(name)yes|no)
与分组命名吻合
如果与某分组命名吻合,则视为判断该分组是否进行捕获
另外:
如果表达式为 RIGHTTOLEFT 模式,那么 (?(xxx)aa|bbb) 与 (?(?<=xxx)aa|bbb) 相同。
如果条件表达式只有一个选择项,那么这个选项是在条件成立时进行匹配。
如果条件表达式中,使用“|”进行分隔的选项多于2个,则只有第一个“|”被视为条件表达式选项分隔符。比如: (?(?=xxx)yes|no1|no2),条件成立时,匹配 yes 部分,否则匹配 “no1|no2”。
递归表达式 (?R)
对另一部分子表达式的引用,而不是对其匹配结果的引用。当被引用的表达式包含自身,则形成递归引用。
说明
相对于 “反向引用” 来说,反向引用是在匹配过程中,对匹配到的字符串内容进行引用,而 “递归匹配” 是对表达式进行引用。举例说明:
表达式
等效的表达式1
等效的表达式2
可以匹配
(\w)(?1)
(\w)(\w)
ab
(?1)(\w(?2))(\d)
(?1)(\w(\d))(\d)
(\w(\d))(\w(\d))(\d)
a1b23
如果被引用的表达式又包含自身,则形成了递归引用。举例说明:
表达式
等效1
等效2
可以匹配
(\w(?1)?)
(\w(\w(?1)?)?)
(\w+)
ghjk5……
(([^()]|(?R)))
(([()]|(([()]|(?R))))*)
(a * (c + 2))
DEELX 支持的递归表达式格式有:
格式
说明
(?R)
对整个表达式的递归引用。
(?R1),(?R2)
对指定分组的递归引用。
(?1),(?2)
(?R)
对指定命名分组的递归引用。
(?R’named’)


















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









