



 本文深入探讨了正则表达式的使用技巧,通过具体实例讲解了如何利用正则表达式进行字符串匹配,包括分组匹配、贪婪与非贪婪模式,以及Java代码实现。
本文深入探讨了正则表达式的使用技巧,通过具体实例讲解了如何利用正则表达式进行字符串匹配,包括分组匹配、贪婪与非贪婪模式,以及Java代码实现。
import re
aa=’+4’
#匹配尖括号里面的内容
reExp= re.compile(’<(.*?)>+’)
b = reExp.findall(aa)
b = reExp.sub(’’,aa)
print(b)
import re
line = “Cats are smarter than dogs”
matchObj = re.match( r’(.) are (.?) .*’, line, re.M|re.I)
if matchObj:
print( matchObj.group())
print(matchObj.group(1))
print(matchObj.group(2))
else:
print(“No match!!”)
#match 一个分组只匹配一个分组 写一个分组就只匹配一个分组 而且是依顺序的
#而findall会匹配所有的,并以列表形式给出结果
解析:
首先,这是一个字符串,前面的一个 r 表示字符串为非转义的原始字符串,让编译器忽略反斜杠,也就是忽略转义字符。但是这个字符串里没有反斜杠,所以这个 r 可有可无。
(.) 第一个匹配分组,. 代表匹配除换行符之外的所有字符。
(.?) 第二个匹配分组,.? 后面多个问号,代表非贪婪模式,也就是说只匹配符合条件的最少字符(
贪婪模式不匹配所有 换行符的时候就结束了)
后面的一个 .* 没有括号包围,所以不是分组,匹配效果和第一个一样,但是不计入匹配结果中
————————————————
版权声明:本文为优快云博主「kyle1314608」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/kyle1314608/article/details/100595174
正则表达式:\(PE等级,(.*?)\)\(颜色,(.*?)\)\(生产标准\(国准\),(.*?)\)\(标准尺寸比,(.*?)\)
\( 和 \) 是转义括号,匹配原文中本来的小括号
(.*?) 是每一个分组匹配的内容
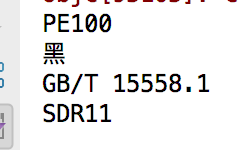
匹配结果:
第一组:PE100
第二组:黑
第三组:GB/T 15558.1
第四组:SDR11
Java代码测试例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
java.util.regex.Matcher;
import
java.util.regex.Pattern;
public
class
Test {
public
static
void
main(String[] args) {
String text =
"(PE等级,PE100)(颜色,黑)(生产标准(国准),GB/T 15558.1)(标准尺寸比,SDR11)"
;
Pattern pattern = Pattern.compile(
"\\(PE等级,(.*?)\\)\\(颜色,(.*?)\\)\\(生产标准\\(国准\\),(.*?)\\)\\(标准尺寸比,(.*?)\\)"
);
Matcher matcher = pattern.matcher(text);
if
(matcher.find()) {
System.out.println(matcher.group(
1
));
//PE等级
System.out.println(matcher.group(
2
));
//颜色
System.out.println(matcher.group(
3
));
//生产标准
System.out.println(matcher.group(
4
));
//标准尺寸比
}
}
}
|


















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









