




 本文介绍了如何使用Python的Counter类来构建词汇表。在处理文本数据时,无论是连续的文本还是二维列表形式的词汇,Counter都能有效地统计元素频率。通过most_common()方法,可以获取最常出现的词汇。此外,还讨论了如何在词汇表中添加'unk'和'pad'特殊标记,并确保它们的特定索引。
本文介绍了如何使用Python的Counter类来构建词汇表。在处理文本数据时,无论是连续的文本还是二维列表形式的词汇,Counter都能有效地统计元素频率。通过most_common()方法,可以获取最常出现的词汇。此外,还讨论了如何在词汇表中添加'unk'和'pad'特殊标记,并确保它们的特定索引。
这里只记录两种情况:
1
数据集是一段连续的文本,所有词汇放在一个list中(一维的)
text:

此时Counter(text),text可以是一个list,统计该list中所有元素出现的次数并返回一个dict

结合most_common()方法,就可构建词汇表:print(Counter(text).most_common(5))
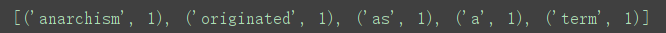
(5)表示选取频率最高的5个元素,返回由(key,value)元组组成的list
再由二元组列表组成dict:print(dict(Counter(text).most_common(5)))

2
当所有的词汇不是放在一个一维的list中,而是一个二维list:

我们可以通过二层循环访问到其中的每一个元素,然后要把这些元素的值累计计数
先通过Counter()构建一个空字典(Couner对象):
sentences = [['BOS', '任', '何', '人', '都', '可', '以', '做', '到', '。', 'EOS'],  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









