



ON 、WHERE、HAVING都能通过限制条件筛选数据,但他们的使用及其不同。下面我们来分析三者之间的区别。
一、ON 和WHERE
所有的查询都会产生一个中间临时报表,查询结果就是从返回临时报表中得到。 ON和WHERE后面所跟限制条件的区别,主要与限制条件起作用的时机有关: ON根据限制条件对数据库记录进行过滤,然后生产临时表; WHERE在临时表生产之后,根据限制条件从临时表中筛选结果。
因为以上原因,ON和WHERE的区别主要有下: 1) 返回结果: 在左外(右外)连接中,ON会返回左表(右表)中的所有记录; 而WHERE中,此时相当于inner join,只会返回满足条件的记录(因为是从临时表中筛选,会过滤掉不满足条件的)。 例: 假设有两张表tab1,tab2,如下图: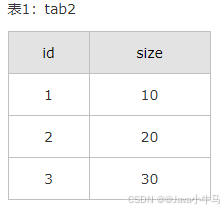
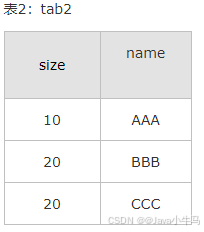
两条SQL:
1、select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’;
2、select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’);
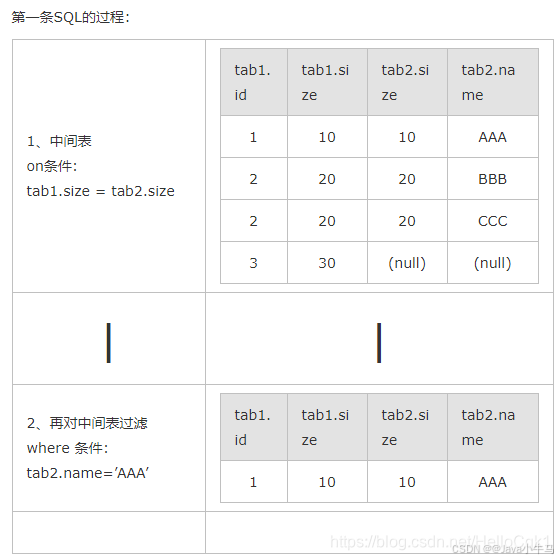
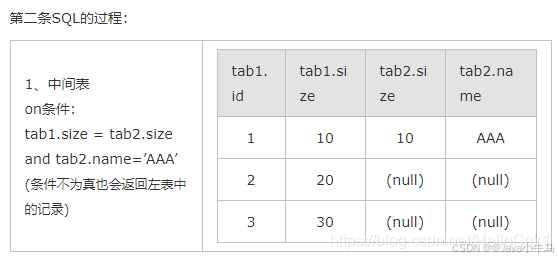
2) 速度: ON限制条件发生时间较早,临时表的数据集要小,因此ON的性能要优于WHERE。
二. HAVING和WHERE
HAVING和WHERE的区别也是与限制条件起作用时机有关。 HAVING是在聚集函数计算结果出来之后筛选结果,查询结果只返回符合条件的分组,HAVING不能单独出现,只能出现在GROUP BY子句中; WHERE是在计算之前筛选结果,如果聚集函数使用WHERE,那么聚集函数只计算满足WHERE子句限制条件的数据。
例如: SELECT COUNT(id) FROM db_equip WHERE tb_equip_type = ‘2’; Count计算的结果是首先筛选设备类型为2的的设备,然后统计设备类型为2类型的数量。
在使用和功能上,HAVING和WHERE有以下区别:
1)HAVING不能单独出现,只能出现在GROUP BY子句之中;WHERE即可以和SELECT等其他子句搭配使用,也可以和GROUP BY子句搭配使用,WHERE的优先级要高于聚合函数高于HAVING。
2)因为WHERE在聚集函数之前筛选数据,HAVING在计算之后筛选分组,因此WHERE的查询速度要比HAVING的查询速度快。
三、 总结
on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后。有时候如果这先后顺序不影响中间结果的话,那最终结果是相同的。但因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的。 根据上面的分析,可以知道where也应该比having快点的,因为它过滤数据后才进行sum,所以having是最慢的。
但也不是说having没用,因为有时在步骤3还没出来都不知道那个记录才符合要求时,就要用having了。 在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢。 如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里


















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









