




文章目录
一、介绍
每当想在闲暇时间看看电影或追剧,总是面临各个平台要求付费订阅或强制注册的问题。 而且往往还充斥着大量广告,有时还需要安装特定的播放器或插件,整个观影体验非常糟糕。 最近发现GitHub上一个名为 LibreTV 的开源项目,它是一个纯前端的在线视频搜索与观看平台,无需注册账号,不用下载安装任何软件。 通过聚合多个可靠有效的视频源,提供简洁的搜索和播放功能,让观影体验变得前所未有的轻松!
二、界面效果
三、主要功能
LibreTV 拥有一系列实用的功能,满足日常观影需求:
• 多源视频搜索:聚合多个视频源,一次搜索即可找到想看的电影或电视剧
• 响应式设计:完美支持电脑、平板和手机,随时随地都能观看
• 自动提取播放链接:无需手动寻找播放源,系统自动提取最佳链接
• 自定义 API 接口:支持添加自己喜欢的视频源,扩展性极强
• 本地存储搜索历史:方便快速回顾之前搜索过的内容
• 纯静态部署:轻量级设计,加载速度快
• 广告过滤功能:提供更干净的观影体验
• 自定义视频播放器:支持 HLS 流媒体格式,播放流畅
四、资源接口
LibreTV 默认支持以下几种视频源接口:
黑木耳影视 (heimuer)
非凡影视 (ffzy)
天涯资源 (tyyszy)ck资源(ckzy)
360资源(zy360)
新华为(cjhw)
豆瓣资源(dbzy)
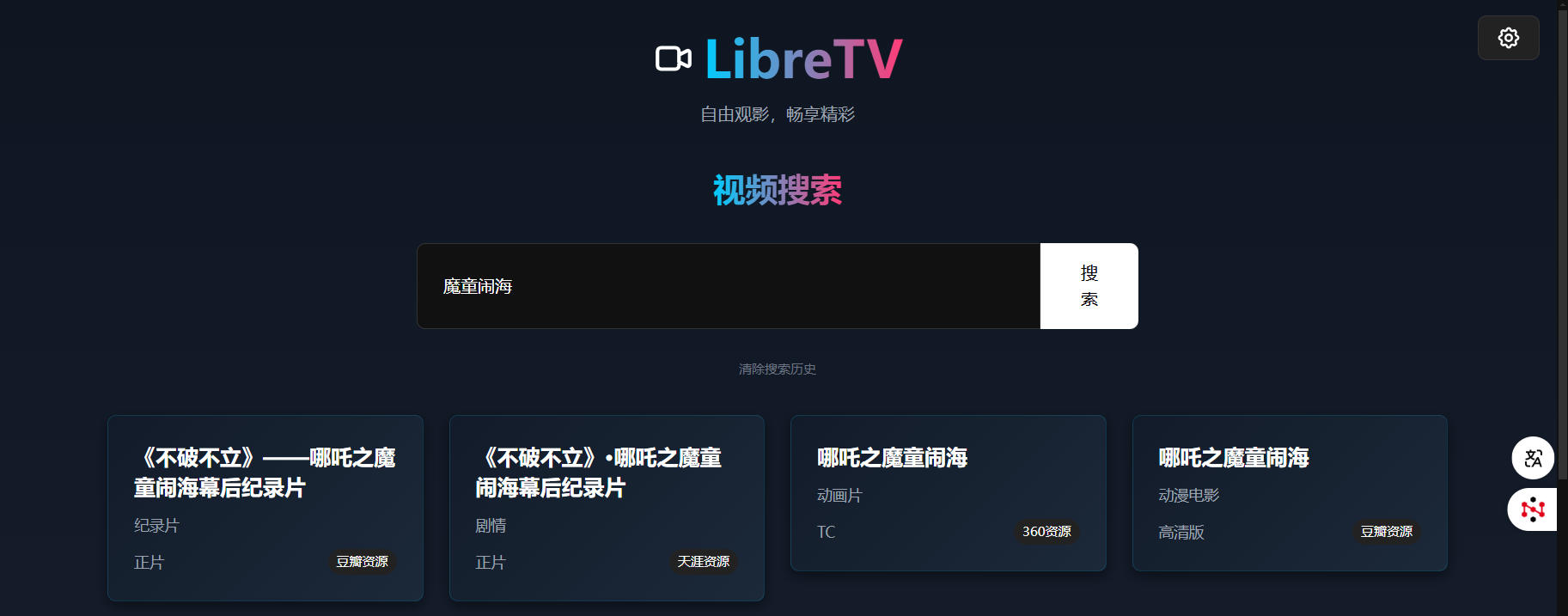
最新的哪吒——魔童闹海也有资源哦!
五、项目结构
LibreTV/
├── css/
│ └── styles.css // 自定义样式
├── js/
│ ├── app.js // 主应用逻辑
│ ├── api.js // API请求处理
│ ├── config.js // 全局配置
│ └── ui.js // UI交互处理
├── player.html // 自定义视频播放器
├── index.html // 主页面
├── robots.txt // 搜索引擎爬虫配置
└── sitemap.xml // 站点地图
六、Docker部署
Github仓库地址:https://github.com/bestZwei/LibreTV
使用 Docker 部署:
docker pull bestzwei/libretv:latest docker run -d --name libretv -p 8899:80 bestzwei/libretv:latest部署完成后,访问 http://localhost:8899 即可使用
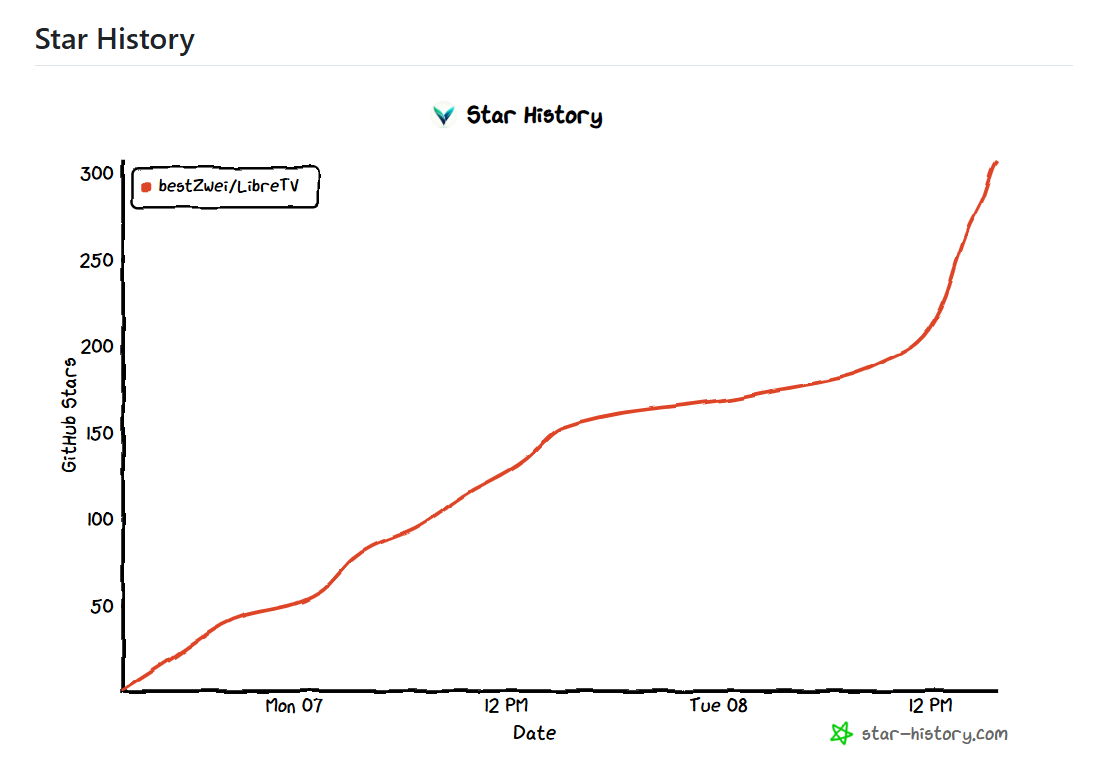
七、项目热度
八、结语
通过 LibreTV,我们可以摆脱平台的各种限制,在一个干净无广告的环境中找到并观看喜欢的内容。 无论是追剧、看电影还是重温经典节目,这个工具都能提供更高效、更便捷的观影体验。 一键部署,即开即用,让视频搜索与观看变得如此简单!


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











