



检索增强生成(Retrieval Augmented Generation, RAG)是提升大型语言模型(LLM)应用效果的关键技术。根据您的要求,本文将RAG的深度解析分为四个部分:知识索引构建流程、运行时核心流程、向量数据库原理与相似度计算以及RAG效果评估与持续优化。
一、 RAG的基石:知识索引构建流程解析
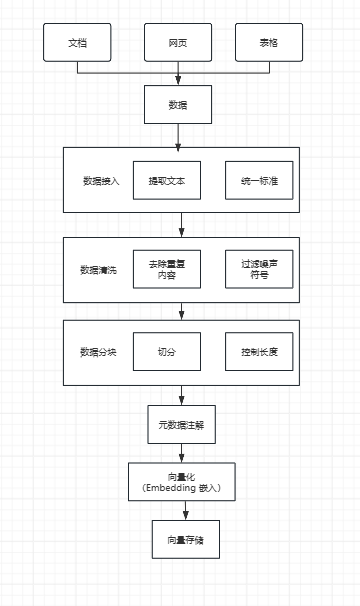
RAG系统的性能高度依赖于其知识库的质量。索引构建(Indexing)是RAG的基石,它将原始数据转化为可供高效检索的向量形式。以下流程图清晰地展示了这一过程:
|
流程阶段 |
关键步骤 |
对应碎片信息 |
|
1. 数据源与接入 |
文档、网页、表格 -> 数据 -> 提取文本 -> 统一标准 |
“数据接入与格式的统一” |
|
2. 数据清洗 |
去除重复内容、过滤噪声符号 |
“去除重复内容”、“过滤噪声符号” |
|
3. 数据分块 |
切分、控制长度 |
“RAG中的分块”、“常见的分块策略” |
|
4. 元数据注解 |
元数据注解 |
“元数据标注” |
|
5. 向量化与存储 |
向量化 (Embedding 嵌入) -> 向量存储 |
“RAG中的 Embedding 嵌入”、“向量数据库原理” |
1. 数据接入与标准化
RAG的第一步是处理多源异构数据,包括PDF、Word、网页、表格等。
•提取文本:利用工具(如PyPDF2、BeautifulSoup)从各种格式中提取纯文本内容。
•统一标准:对提取的文本进行格式标准化,例如统一编码(UTF-8)、去除乱码、统一大小写,确保数据一致性。
2. 数据清洗与预处理
数据清洗是保证检索质量的关键环节。
•去除重复内容:过滤文档中的页眉页脚、重复描述等,避免冗余信息。
•过滤噪声符号:去除标点、特殊字符、Markdown格式等噪声,保留核心文本。
•敏感信息处理:利用正则或库删除隐私数据(手机号、邮箱),避免泄露。
3. 文本分块(Chunking)
由于大语言模型的上下文窗口限制,长文本必须被拆分成若干个“知识块”。
•切分与长度控制:分块策略包括自然结构分块(按标题、段落)、固定大小分块、滑动窗口分块和递归分块等。目标是让每个块包含相对完整的语义单元,并控制长度(如300-500字)以适配LLM的上下文窗口。
4. 元数据注解(Metadata Annotation)
为每个知识块附加元数据,如文档标题、URL、作者、上传时间、章节位置等。
•作用:元数据可作为检索时的过滤条件,是实现自查询(Self-Query)等高级检索的基础。
5. 向量化与存储
这是索引构建的最后一步,将处理好的文本转化为数值形式。
•向量化(Embedding):使用嵌入模型(如BERT、BGE)将文本内容映射为高维空间中的密集向量。
•向量存储:将这些向量存入向量数据库(如Milvus、Faiss),利用高效的索引结构和近似最近邻(ANN)算法,为后续的快速检索做好准备。
二、 RAG的运行时核心流程:从查询到生成
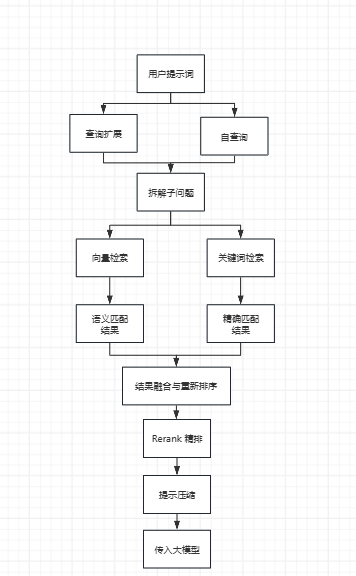
索引构建完成后,RAG系统进入运行时阶段,即检索增强生成(Retrieval Augmented Generation)的循环。以下流程图展示了用户查询到最终答案的完整路径:
|
流程阶段 |
关键步骤 |
对应碎片信息 |
|
1. 查询预处理 |
用户提示词 -> 查询扩展 / 自查询 -> 拆分子问题 |
“查询扩展”、“自查询” |
|
2. 初步检索 |
向量检索(语义匹配)/ 关键词检索(精确匹配) |
“混合检索” |
|
3. 结果优化 |
结果融合与重排序 -> Rerank使用 |
“混合检索”、“Rerank” |
|
4. 提示构建 |
提示压缩 -> 传入大模型 |
“提示压缩” |
1. 查询预处理与增强
在进行检索之前,系统会对用户原始查询进行增强和解析,以提高检索的准确性。
•查询扩展(Query Expansion):通过添加同义词、相关术语或隐含意图,让查询更精准、覆盖范围更广,解决词汇匹配问题。
•自查询(Self-Query):自动解析用户查询中的隐含条件(如时间、作者等元数据),生成结构化查询语句,解决元数据过滤问题。
•拆分子问题:对于复杂查询,将其分解为更小的、可独立检索的子问题。
2. 初步检索(混合检索)
系统并行或顺序执行多种检索方式,以确保检索结果的全面性。
•向量检索:基于语义相似度进行匹配,擅长理解文本含义。
•关键词检索:基于倒排索引、BM25等算法,擅长精确匹配专有名词。
•结果融合与重排序:将向量检索和关键词检索的结果通过权重融合或RRF等模型合并,形成一个初步的候选文档列表。
3. 结果优化(Rerank)
初步检索(粗排)的结果可能包含不相关文档。
•Rerank(重排序):利用更精确的Rerank模型对初步检索返回的候选文档列表进行再次排序(精排),选出匹配度最高的Top-K文档,极大地提高了最终送入LLM的上下文质量。
4. 提示构建与生成
•提示压缩(Prompt Compression):对Rerank后的Top-K文档进行精简处理,提取核心信息,过滤无关文本,确保最终的Prompt既完整保留关键信息,又符合LLM的上下文窗口限制,同时降低计算资源消耗。
•传入大模型:将用户查询和经过优化的上下文(Prompt)输入给大型语言模型,由LLM生成最终的答案。
三、 向量数据库原理与相似度计算
RAG系统的性能高度依赖于高效的向量检索。以下流程图展示了向量数据库中相似度计算的核心原理:
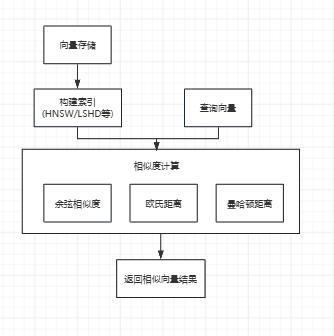
向量数据库的核心原理是通过将高维数据转换为多维向量,并基于相似性度量,利用高效的索引结构和近似最近邻(ANN)算法,快速检索与目标最相似的向量结果。
相似度计算方法:
•余弦相似度:衡量两个向量的“方向相似性”,不关心向量长度,常用于文本、推荐系统(关注语义方向)。
•欧几里得距离(欧氏距离):计算两个向量在空间中的“直线距离”,常用于图像、视频检索(关注空间差异)。
•曼哈顿距离:计算两个向量在各维度上的差值绝对值之和,适用于网格数据、稀疏数据。
四、 RAG效果评估与持续优化
RAG是一个持续优化的过程,需要从检索质量、生成质量和系统性能三个维度进行评估。
1. 检索质量评估
关注系统从知识库中找到相关信息的能力。
•客观指标:包括Precision@k(前k个结果的相关性比例)、MRR(首个相关结果的排名倒数均值)、NDCG(区分不同相关度的重要性)和Recall@k(覆盖所有相关文档的比例)。
•主观评测:通过人工审核检索结果是否满足业务需求。
2. 生成质量评估
关注LLM基于检索结果生成答案的质量。
•CR(Context Relevancy):答案是否基于检索内容(忠实度)。
•AR(Answer Relevancy):回答是否解决用户问题(相关性)。
•F(Faithfulness):评估生成的答案中是否存在幻觉。
•评测方法:可采用大模型打分或人工打分。
3. 系统性能评估
关注非功能性需求,确保系统在生产环境中的可用性。
•延迟:响应时间。
•吞吐量:单位时间处理请求量。
•错误率:生成错误答案的比例。
在实际应用中,建议采取分层测试(先测检索,再测生成,最后压测性能)和持续监控(实时跟踪用户满意度、业务指标)的策略,以实现RAG系统的持续优化。


















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









