



一、Redis 知识点全景概览
要真正掌握 Redis,不能只零散记忆命令或知识点,而需从单点出发,梳理清楚知识点间的关联,构建完整知识网络。下面就从 Redis 的核心优势切入,带大家由点及面认识 Redis 各知识点的联系。
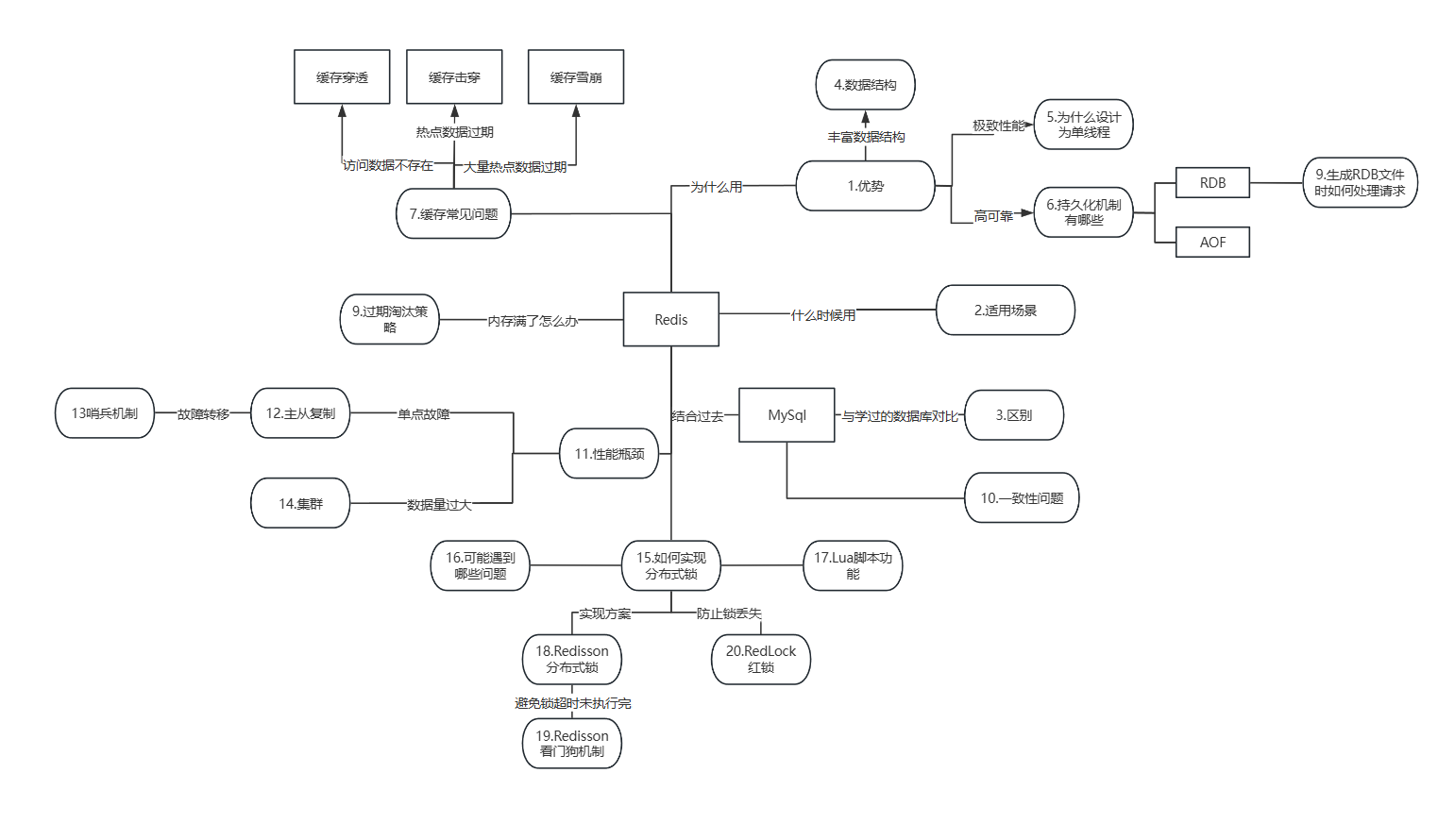
二、Redis 核心优势:为什么选择 Redis?
Redis 能在众多缓存 / 数据库中脱颖而出,源于其三大核心优势:
1. 极致性能
- 单线程设计:Redis 采用单线程模型处理客户端请求(持久化、异步复制等操作由后台线程处理)。单线程避免了线程切换和锁竞争的开销,结合内存存储,使得 Redis 能达到每秒数万次读写的高性能。
- IO 多路复用:通过 epoll/select 等机制,单线程可同时处理多个客户端连接的网络 IO,进一步提升吞吐量。
2. 丰富数据结构
Redis 提供了远超普通键值对的8 种核心数据结构:
- 字符串(String):存储文本、数字,支持自增 / 自减、位图(Bitmap)等操作。
- 列表(List):双向链表结构,支持栈(LIFO)、队列(FIFO)操作,可做消息队列。
- 集合(Set):无序不重复集合,支持交集、并集、差集等聚合操作。
- 有序集合(Sorted Set):基于跳表实现,元素带分数(score),支持按分数范围查询、排名等。
- 哈希(Hash):存储键值对集合,适合存对象(如用户信息)。
- 位图(Bitmap):按位存储,用于统计(如日活用户)。
- HyperLogLog:基数统计(近似去重计数)。
- 地理空间(Geo):存储地理位置信息,支持距离计算、范围查询。
3. 高可靠性
通过持久化机制和复制机制保证数据不丢失、服务高可用:
- 持久化:RDB 快照 + AOF 日志,确保内存数据能持久化到磁盘。
- 复制:主从复制实现读写分离、故障转移,提升系统可靠性。
三、Redis 适用场景:什么时候该用 Redis?
Redis 不是银弹,这些场景最能发挥它的价值:
- 缓存层:缓解数据库压力,存储热点数据(如商品详情、用户会话)。
- 计数器:利用 String 自增特性,实现文章阅读数、点赞数、限流计数等。
- 消息队列:通过 List 的
lpush/brpop或 Pub/Sub 实现简单消息队列。 - 分布式锁:解决分布式系统中资源竞争问题(如秒杀、订单防重)。
- 实时统计:借助 Set、Sorted Set、HyperLogLog 实现 UV 统计、排行榜、去重计数等。
- 地理位置服务:通过 Geo 结构实现附近的人、打车距离计算等功能。
四、Redis vs MySQL
1.核心区别在哪里?
| 特性 | Redis | MySQL |
|---|---|---|
| 存储介质 | 内存(支持持久化到磁盘) | 磁盘 |
| 数据结构 | 丰富(String、List、Set 等 8 种) | 基于表的关系型结构 |
| 性能 | 极高(万级 QPS) | 较低(千级 QPS,依赖索引优化) |
| 事务支持 | 简单事务(不支持回滚) | 完整事务(ACID 特性) |
| 适用场景 | 缓存、高并发计数、实时统计等 | 持久化业务数据、复杂关系查询 |
2.Redis 与 MySQL 一致性问题
在缓存与数据库双写场景下,容易出现数据一致性问题,常见解决方案:
- 延时双删:写数据库后,删除缓存 → 休眠一段时间(如 500ms)→ 再次删除缓存(防止读写并发导致的脏数据)。
- 读时双检:读缓存时,若缓存命中则返回;若未命中,先查数据库,再将数据写入缓存(需加锁避免并发写脏数据)。
- Canal 订阅 binlog:通过 Canal 监听 MySQL binlog,异步更新 Redis 缓存,保证最终一致性。
五、Redis 数据结构:每种结构的典型用法
1. String
- 用法:存储用户 token、商品价格、验证码等;结合
incr/decr做计数器。 - 底层:简单动态字符串(SDS),支持预分配空间减少扩容开销。
2. List
- 用法:做消息队列(
lpush + brpop)、存储用户操作历史(如浏览记录)。 - 底层:双向链表 + 压缩列表(小数据量时)。
3. Set
- 用法:存储用户标签(如 “喜欢科幻的用户”)、实现抽奖功能(
srandmember)。 - 底层:哈希表 + 整数集合(小整数且无重复时)。
4. Sorted Set
- 用法:实现排行榜(如 “销量 Top10 商品”)、延迟任务(结合 score 为时间戳)。
- 底层:跳表 + 哈希表,跳表保证有序性,哈希表保证查询效率。
5. Hash
- 用法:存储对象(如用户信息:
user:{id} → {name: "xxx", age: 18})。 - 底层:哈希表 + 压缩列表(小数据量时)。
六、Redis 持久化机制:RDB vs AOF
Redis 提供两种持久化方式,保障内存数据能落地到磁盘:
1. RDB(快照持久化)
- 原理:在指定时间间隔内,将内存中的全量数据快照写入 RDB 文件(如
dump.rdb)。 - 触发方式:
- 手动触发:
save(阻塞)或bgsave(非阻塞,fork 子进程执行)。 - 自动触发:配置
save <秒> <修改次数>(如save 300 10表示 300 秒内修改 10 次则触发)。
- 手动触发:
- 生成 RDB 时如何处理请求:
bgsave时,父进程继续处理客户端请求,子进程负责写 RDB 文件,互不影响。 - 优点:文件体积小,恢复速度快。
- 缺点:快照间隔内的数据可能丢失(如突然宕机)。
2. AOF( append-only file,追加式日志)
- 原理:将所有写操作命令以文本形式追加到 AOF 文件,恢复时重新执行这些命令。
- 触发方式:
- 实时同步(
appendfsync always):每次写操作都同步到磁盘,性能差但安全性高。 - 每秒同步(
appendfsync everysec):每秒同步一次,是默认且推荐的配置。 - 操作系统控制(
appendfsync no):由操作系统决定何时同步,性能好但安全性低。
- 实时同步(
- 优点:数据丢失少(最多丢失 1 秒数据),日志可读性强。
- 缺点:AOF 文件体积大,恢复速度比 RDB 慢。
3. 混合持久化(Redis 4.0+)
结合 RDB 和 AOF 的优点:AOF 文件中前半部分是 RDB 格式的全量数据,后半部分是增量的 AOF 命令。恢复时先加载 RDB 部分,再执行增量 AOF 命令,兼顾了恢复速度和数据安全性。
七、Redis 缓存常见问题:穿透、击穿、雪崩
1. 缓存穿透
- 问题:大量请求访问缓存和数据库都不存在的数据,导致请求直接打在数据库上,可能压垮数据库。
- 解决方案:
- 布隆过滤器:提前过滤不存在的键。
- 缓存空值:即使数据库无数据,也在缓存中存一个空值(设置短过期时间)。
2. 缓存击穿
- 问题:某个热点 key 过期瞬间,大量请求同时访问该 key,直接打在数据库上。
- 解决方案:
- 热点 key 永不过期:业务层面保证热点数据长期有效。
- 互斥锁:第一个请求构建缓存时,其他请求等待(如用 Redis 分布式锁)。
3. 缓存雪崩
- 问题:大量 key 在同一时间过期,或 Redis 集群宕机,导致请求大量涌入数据库。
- 解决方案:
- 过期时间打散:为 key 设置随机过期时间,避免集中过期。
- 多级缓存:结合本地缓存(如 Guava Cache)和 Redis 缓存,降低单缓存层压力。
- 集群高可用:通过主从、哨兵或集群模式保证 Redis 服务不宕机。
八、Redis 内存满了怎么办?过期淘汰策略
当 Redis 内存达到 maxmemory 限制时,会触发过期淘汰策略删除部分 key,释放内存:
- volatile-lru:在设置了过期时间的 key中,淘汰最近最少使用的 key。
- volatile-ttl:在设置了过期时间的 key 中,淘汰剩余过期时间最短的 key。
- volatile-random:在设置了过期时间的 key 中,随机淘汰。
- volatile-lfu:在设置了过期时间的 key 中,淘汰最近最少频率使用的 key(Redis 4.0+ 支持)。
- allkeys-lru:在所有 key中,淘汰最近最少使用的 key。
- allkeys-random:在所有 key 中,随机淘汰。
- allkeys-lfu:在所有 key 中,淘汰最近最少频率使用的 key(Redis 4.0+ 支持)。
- noeviction:默认策略,不淘汰任何 key,写操作会报错。
九、Redis 性能瓶颈与解决方案
1. 单点故障(主从复制 + 哨兵机制)
- 问题:单台 Redis 宕机导致服务不可用。
- 解决方案:
- 主从复制:一台主节点(写),多台从节点(读),实现读写分离和数据备份。
- 哨兵(Sentinel):监控主从节点状态,当主节点宕机时自动将从节点提升为主节点,实现故障转移。
2. 数据量过大(集群)
- 问题:单台 Redis 内存 / 性能无法支撑海量数据。
- 解决方案:Redis 集群(Cluster),通过 ** 哈希槽(16384 个)** 将数据分片到多台节点,支持横向扩容。
十、Redis 分布式锁:如何实现与常见问题
1. 基础分布式锁实现(Redis 命令)
Redis 支持通过 Lua 脚本执行原子性操作,优点:
- 减少网络往返:将多个命令打包成脚本执行,降低网络开销。
- 原子性保证:脚本执行过程中不会被其他命令打断。
典型用法:实现复杂的业务逻辑(如库存扣减 + 订单创建)、分布式锁的原子性释放等。
利用 Redis 的 setnx(set if not exists)命令实现:
lua
# 加锁:key 为锁标识,value 为随机值(用于释放时校验),ex 为过期时间
set lock:order {randomValue} nx ex 10
# 释放锁:通过 Lua 脚本保证原子性(先校验 value,再删除)
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
2. 常见问题与解决方案
(1)锁丢失问题
- 场景:锁过期了,但业务还没执行完,导致其他线程获取到锁。
- 解决方案:
- Redisson 看门狗机制:自动延长锁的过期时间,只要业务还在执行,锁就不会过期。
- 业务逻辑优化:缩短持有锁的时间,或预估业务执行时间,合理设置锁过期时间。
(2)RedLock 红锁(多节点分布式锁)
- 原理:在多个独立的 Redis 节点(如 5 个)上同时加锁,超过半数节点加锁成功则认为锁获取成功,保证分布式环境下的锁可靠性。
- 适用场景:对锁安全性要求极高的场景(如金融交易)。
(3)Redisson 分布式锁
- 优势:封装了复杂的分布式锁逻辑,支持自动续期(看门狗)、可重入、公平锁等特性,使用简单。

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









