




 本文介绍了解释器模式,通过Spring的EL表达式、Elasticsearch的RoleMapperExpression和ShardingSphere的SQL解析等案例阐述其作用。解释器模式用于实现简单语言的解释,适用于SQL解析、DSL解析和自定义规则场景。该模式允许方便地扩展文法,但复杂的文法维护较为困难。
本文介绍了解释器模式,通过Spring的EL表达式、Elasticsearch的RoleMapperExpression和ShardingSphere的SQL解析等案例阐述其作用。解释器模式用于实现简单语言的解释,适用于SQL解析、DSL解析和自定义规则场景。该模式允许方便地扩展文法,但复杂的文法维护较为困难。
目录
Elasticsearch的RoleMapperExpression表达式解析
what什么是解释器模式
Gof定义:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
HeadFirst定义:当你需要实现一个简单的语言时,就使用解释器模式定义语法的类,并用一个解释器解释句子。每个语法规则都用一个类代表。
几乎所有涉及到SQL相关的,涉及到DSL相关的,都少不了Expression模式,只是规则的差异,语法的涵义不同,比如Elasticsearch对DSL的解析,ShardingSphere和mybatis – MyBatis 3 对SQL的解析。
why为什么需要解释器模式
说实话,这应该我用的最少的一个设计模式了,只有在自己制定语法规则的时候才用的上,印象中工作中只有两次,一次是蚂蚁的报表报送模式,里面涉及到复杂的取数分拣规则,因此自定义了一套语法,使用标准的解释器模式是解释。另外就是自定义了一个兼容Explorer、Elasticsearch、Odps语法的DSL,这也用到了解释器模式。
这里应用GOF设计模式的解释:
如果一种特定类型的问题发生的频率足够高, 那么可能就值得将该问题的各个实例表述为 一个简单语言中的句子。这样就可以构建一个解释器, 该解释器通过解释这些句子来解决该问 题。 例如,搜索匹配一个模式的字符串是一个常见问题。正则表达式是描述字符串模式的一 种标准语言。与其为每一个的模式都构造一个特定的算法,不如使用一种通用的搜索算法来 解释执行一个正则表达式,该正则表达式定义了待匹配字符串的集合。 解释器模式描述了如何为简单的语言定义一个文法, 如何在该语言中表示一个句子, 以及如何解释这些句子。解释器设计模式描述了如何为正则表达式定义一个文法, 如何表示一个特定的正则表达式, 以及如何解释这个正则表达式。
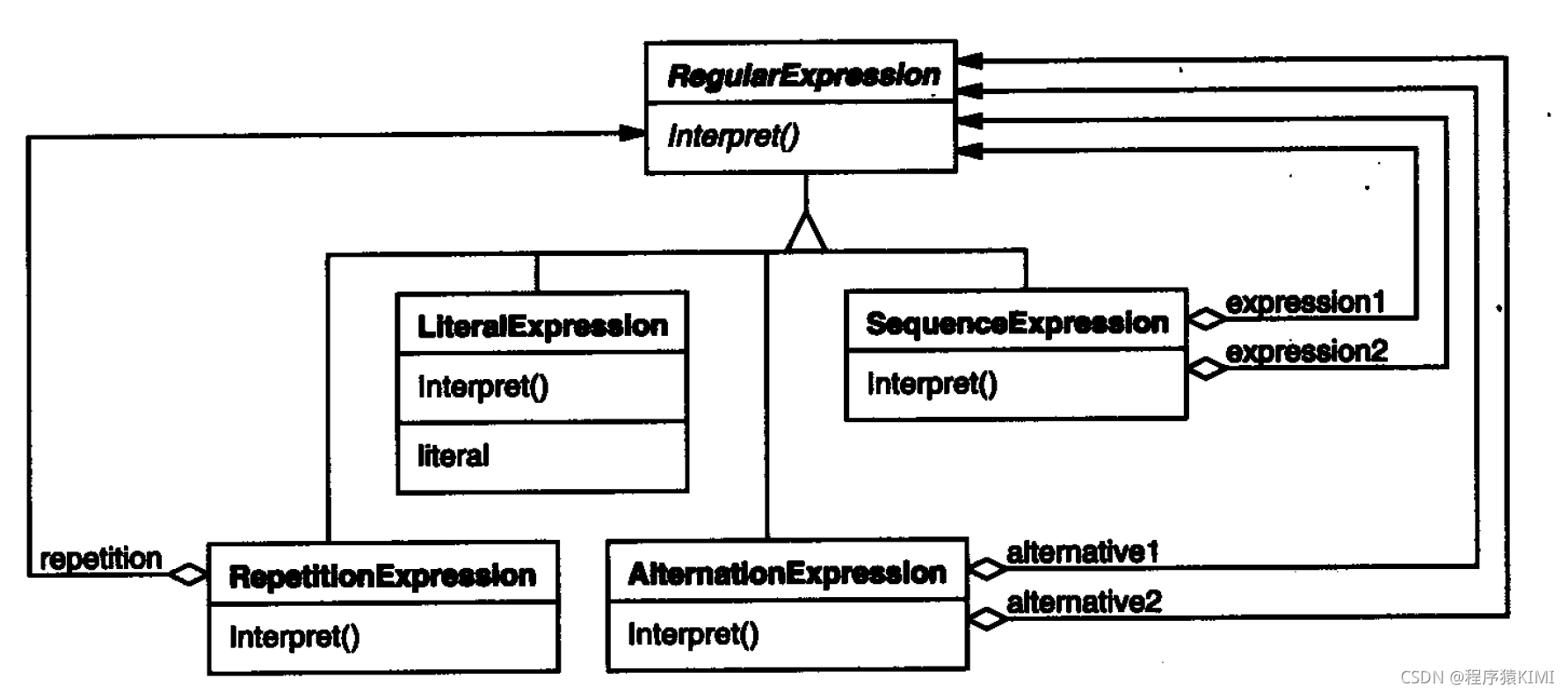
解释器模式使用类来表示每一条文法规则。在规则右边的符号是这些类的实例变量。上面的 文法用五个类表示: 一个抽象类RegularExpression和它四个子类LiteralExpression、AlternationExpression、SequenceExpression和RepetitionExpression后三个类定义的变量代表子表达式。
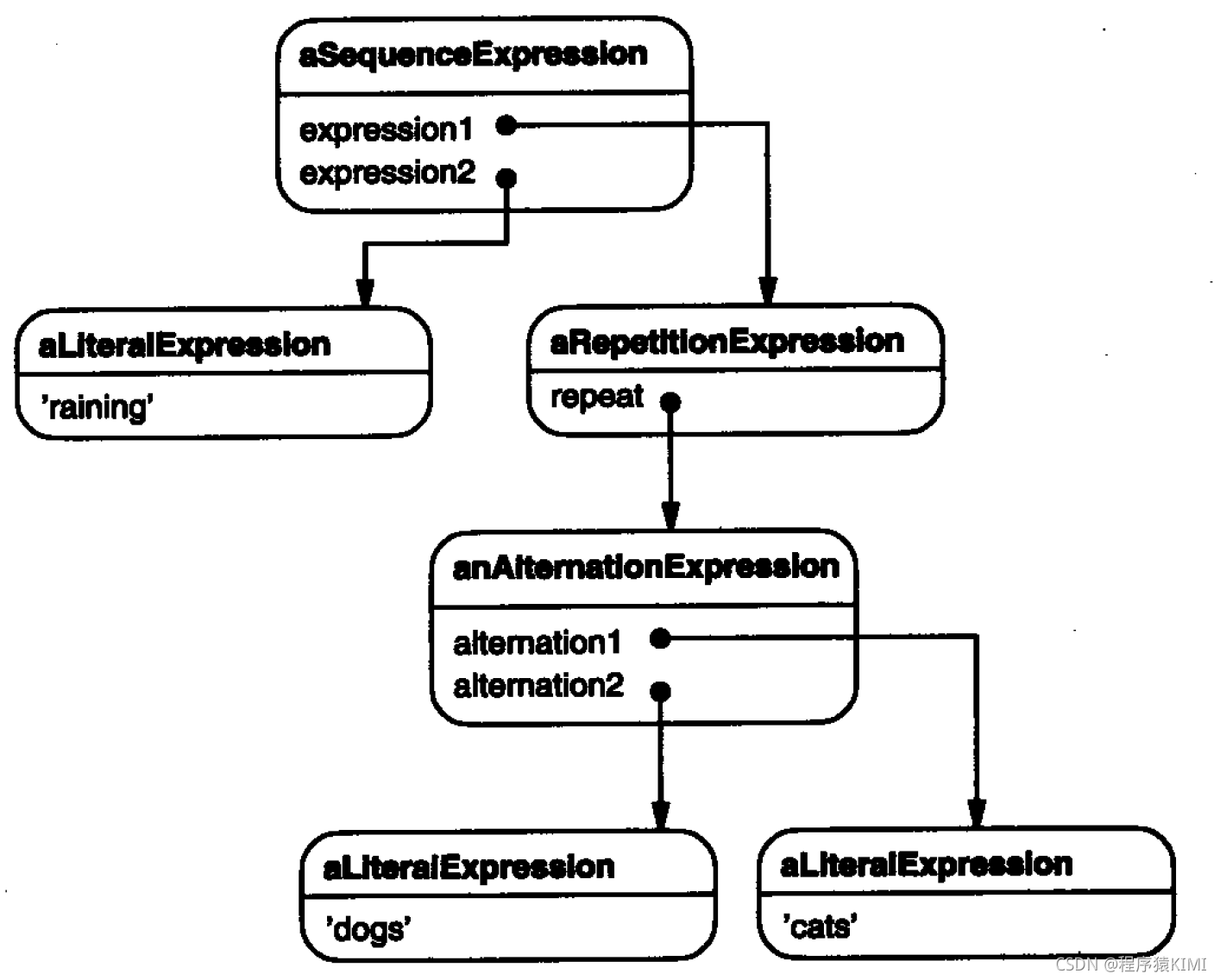
每个用这个文法定义的正则表达式都被表示为一个由这些类的实例构成的抽象语法树。例如, 抽象语法树:

how如何实现解释器模式
解释器模式包含以下主要角色。
- 抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
- 非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
- 环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。

开源框架经典案例
Spring中EL表达式
Spring有一套自己的EL表达式,SpringEL,SpEL是一种强大,简洁的装配Bean的方式,他可以通过运行期间执行的表达式将值装配到我们的属性或构造函数当中,更可以调用JDK中提供的静态常量,获取外部Properties文件中的的配置。可以支持在运行时查询和操作对象但提供了更多扩展功能,如方法调用,字符串模板功能.Spring el表达式支持以下功能:
- 字面值表达式
- boolean和关系操作符
- 正则表达式
- 类表达式
- 访问属性,数组,集合
- 方法调用
- 关系运算
- 调用构造函数
- Bean引用
- 构建数组
- 内联列表
- 内联map
- 三元操作
- 变量
- 用户定义函数
- 集合选择
- 模板表达式
SpringEl表达式的入口,看一下是不是很有解释器的感觉,具体怎么解析的,因为篇幅太常,这里就不详细描述,可以详细看一下InternalSpelExpressionParser类。
public class SpelExpressionParser extends TemplateAwareExpressionParser {
private final SpelParserConfiguration configuration;
public SpelExpressionParser() {
this.configuration = new SpelParserConfiguration();
}
public SpelExpressionParser(SpelParserConfiguration configuration) {
Assert.notNull(configuration, "SpelParserConfiguration must not be null");
this.configuration = configuration;
}
public SpelExpression parseRaw(String expressionString) throws ParseException {
return this.doParseExpression(expressionString, (ParserContext)null);
}
EL表达式的解析入口
protected SpelExpression doParseExpression(String expressionString, ParserContext context) throws ParseException {
return (new InternalSpelExpressionParser(this.configuration)).doParseExpression(expressionString, context);
}
}
InternalSpelExpressionParser的核心处理逻辑
private SpelNodeImpl eatExpression() {
得到表达式结构,类似一个树结构
SpelNodeImpl expr = this.eatLogicalOrExpression();
递归执行
if (this.moreTokens()) {
Token t = this.peekToken();
SpelNodeImpl ifTrueExprValue;
if (t.kind == TokenKind.ASSIGN) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 1));
}
this.nextToken();
ifTrueExprValue = this.eatLogicalOrExpression();
return new Assign(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, ifTrueExprValue});
}
if (t.kind == TokenKind.ELVIS) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 2));
}
this.nextToken();
SpelNodeImpl valueIfNull = this.eatExpression();
if (valueIfNull == null) {
valueIfNull = new NullLiteral(this.toPos(t.startPos + 1, t.endPos + 1));
}
return new Elvis(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, (SpelNodeImpl)valueIfNull});
}
if (t.kind == TokenKind.QMARK) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 1));
}
this.nextToken();
ifTrueExprValue = this.eatExpression();
this.eatToken(TokenKind.COLON);
SpelNodeImpl ifFalseExprValue = this.eatExpression();
return new Ternary(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, ifTrueExprValue, ifFalseExprValue});
}
}
return (SpelNodeImpl)expr;
}Elasticsearch的RoleMapperExpression表达式解析
Elasticsearch针对Role的解析定义了一个RoleMapperExpression,这个类很简单,根据自定义的语法规则,判断Role请求对象是否满足条件,如Field字段是否满足,是否有username属性等等。
看下它的测试用例就能发现这个解析器的作用。
public class RoleMapperExpressionParserTests extends ESTestCase {
public void testParseSimpleFieldExpression() throws Exception {
String json = "{ \"field\": { \"username\" : [\"*@shield.gov\"] } }";
FieldRoleMapperExpression field = checkExpressionType(parse(json), FieldRoleMapperExpression.class);
判断是否有username字段
assertThat(field.getField(), equalTo("username"));
assertThat(field.getValues(), iterableWithSize(1));
assertThat(field.getValues().get(0), equalTo("*@shield.gov"));
assertThat(toJson(field), equalTo(json.replaceAll("\\s", "")));
}RoleMapperExpressionParse的解析逻辑,首先针对请求当作一个对象看到,然后递归解析调用。
private RoleMapperExpression parseRulesObject(final String objectName, final XContentParser parser)
throws IOException {
// find the start of the DSL object
final XContentParser.Token token;
找到DSL的开头,然后获取当前token,如果当前存在,就深度便利下一个token
if (parser.currentToken() == null) {
token = parser.nextToken();
} else {
token = parser.currentToken();
}
if (token != XContentParser.Token.START_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. expected [{}] to be an object but found [{}] instead",
objectName, token);
}
final String fieldName = fieldName(objectName, parser);
调用语法解析类
final RoleMapperExpression expr = parseExpression(parser, fieldName, objectName);
if (parser.nextToken() != XContentParser.Token.END_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. object [{}] contains multiple fields", objectName);
}
return expr;
} 这里有各种类型的解析模式,仅仅列举下字段解析逻辑
private RoleMapperExpression parseExpression(XContentParser parser, String field, String objectName)
throws IOException {
if (CompositeType.ANY.getParseField().match(field, parser.getDeprecationHandler())) {
final AnyRoleMapperExpression.Builder builder = AnyRoleMapperExpression.builder();
parseExpressionArray(CompositeType.ANY.getParseField(), parser).forEach(builder::addExpression);
return builder.build();
} else if (CompositeType.ALL.getParseField().match(field, parser.getDeprecationHandler())) {
final AllRoleMapperExpression.Builder builder = AllRoleMapperExpression.builder();
parseExpressionArray(CompositeType.ALL.getParseField(), parser).forEach(builder::addExpression);
return builder.build();
} else if (FIELD.match(field, parser.getDeprecationHandler())) {
return parseFieldExpression(parser);
} else if (CompositeType.EXCEPT.getParseField().match(field, parser.getDeprecationHandler())) {
return parseExceptExpression(parser);
} else {
throw new ElasticsearchParseException("failed to parse rules expression. field [{}] is not recognised in object [{}]", field,
objectName);
}
}
// 字段解析的逻辑
private RoleMapperExpression parseFieldExpression(XContentParser parser) throws IOException {
checkStartObject(parser);
final String fieldName = fieldName(FIELD.getPreferredName(), parser);
final List<Object> values;
if (parser.nextToken() == XContentParser.Token.START_ARRAY) {
values = parseArray(FIELD, parser, this::parseFieldValue);
} else {
values = Collections.singletonList(parseFieldValue(parser));
}
if (parser.nextToken() != XContentParser.Token.END_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. object [{}] contains multiple fields",
FIELD.getPreferredName());
}
return FieldRoleMapperExpression.ofKeyValues(fieldName, values.toArray());
}ShardingSphere对SQL的语法解析
ShardingSphere对Sql的parse逻辑,是调用SQLParser的parse()方法,这个方法返回的是ASTNode结构体,几乎所有的SQL解析都是最终转换为一个ASTNode。
MySQLParser继承自antlr自动生成的语法解析器MySQLStatementParser,在parse方法中调用MySQLStatementParser的execute方法得到antlr返回的ExecuteContext,然后基于此创建ParseASTNode对象返回。
这里MySQLStatementParser是自动里面的,所以idea源码中是看不到。
/**
* SQL parser for MySQL.
*/
public final class MySQLParser extends MySQLStatementParser implements SQLParser {// MySQLStatementParser是antlr根据.g4文件生成的语法解析器
public MySQLParser(final TokenStream input) {
super(input);
}
@Override
public ASTNode parse() {
return new ParseASTNode(execute());
}// 根据antlr返回的ExecuteContext创建ParseASTNode对象加餐:ShardingSphere中ASTNode版本演进
ShardingSphere也是经过几个版本的演进,才有了现在的这个ASTNode解析逻辑,参考了从源码看ShardingSphere设计的描述。
抽象语法树 (Abstract Syntax Tree),简称 AST,它是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
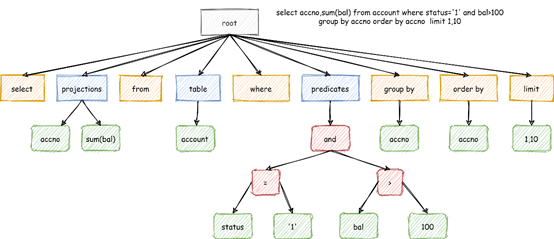
ShardingSphere的解析引擎经过了三个版本的演化:
第一代SQL解析器:
sharding-jdbc在1.4.x 之前的版本使用的alibaba的druid(https://github.com/alibaba/druid),,druid) druid包含了一个手写的SQL解析器,优点是速度快,缺点是扩展不是很方便,只能通过修改源码。第二代 SQL 解析器
从 1.5.x 版本开始,ShardingSphere 重新实现了一个简化版 SQL 解析引擎。因为ShardingSphere 并不需要像druid那样将 SQL 转为完整的AST,所以采用对 SQL 半理解的方式,仅提炼数据分片需要关注的上下文,在满足需要的前提下,SQL 解析的性能和兼容性得到了进一步的提高。第三代 SQL 解析器
则从 3.0.x 版本开始,ShardingSphere统一将SQL解析器换成了基于antlr4实现,目的是为了更方便、更完整的支持SQL,例如对于复杂的表达式、递归、子查询等语句,因为后期ShardingSphere的定位已不仅仅是数据分片功能。
antlr4通过.g4文件定义解析词法和语法规则,ShardingSphere中将词法和语法文件进行了分离定义,例如mysql对应的g4文件,词法规则文件包括Alphabet.g4、Comments.g4、Keyword.g4、Literals.g4、MySQLKeyword.g4、Symbol.g4,语法规则文件有:BaseRule.g4、DALStatement.g4、DCLStatement.g4、DDLStatement.g4、DMLStatement.g4、RLStatement.g4、TCLStatement.g4,每个文件分别定义了一类关键字或者SQL类型规则。
使用场景
- 当需要实现一个简单的语言时,就使用解释器。
- SQL语法分析、DSL解析、自定义规则,都可以使用解释器。
优缺点对比
优点
- 每一个语法规则表示一个类,易于改变和扩展文法因为该模式使用类来表示文法规则, 可使用继承来改变或扩展该文法。
- 已有的表达式可被增量式地改变,而新的表达式可定义为旧表达式的变体。
- 易于实现文法定义抽象语法树中各个节点的类的实现大体类似。这些类易于直接编写,通常它们也可用一个编译器或语法分析程序生成器自动生成。
- 增加了新的解释表达式的方式解释器模式使得实现新表达式“计算”变得容易。例如, 你可以在表达式类上定义一个新的操作以支持优美打印或表达式的类型检查。
缺点
- 复杂的文法难以维护,解释器模式为文法中的每一条规则至少定义了一个类(使用BNF定义的文法规则需要更多的类)。因此包含许多规则的文法可能难以管理和维护。可应用其他的设 计模式来缓解这一问题。但当文法非常复杂时, 其他的技术如语法分析程序或编译器生成器更为 合适。

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









