




 本文介绍了XML的基础语法,包括DTD约束、Schema约束和引用约束,并通过XPath实例展示了如何在解析器中应用这些知识。重点讲解了DTD元素声明、属性声明、Schema的命名空间和约束元素,以及XPath的使用技巧。
本文介绍了XML的基础语法,包括DTD约束、Schema约束和引用约束,并通过XPath实例展示了如何在解析器中应用这些知识。重点讲解了DTD元素声明、属性声明、Schema的命名空间和约束元素,以及XPath的使用技巧。
目录
一、xml的基础语法。

(1)DTD约束文档:
在DTD(文档类型定义)中规定的XML元素必须按特定顺序放置才能被视为合法,这些顺序可以通过在DTD中定义元素的内容模型来指定。
<!DOCTYPE students [
<!ELEMENT students (student*) >//*声明出现零次或多次的元素
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
]>
声明一个元素
在 DTD 中,XML 元素通过元素声明来进行声明。元素声明使用下面的语法:
<!ELEMENT element-name category>或<!ELEMENT element-name (element-content)>
PCDATA 是会被解析器解析的文本。这些文本将被解析器检查实体以及标记。
CDATA 是不会被解析器解析的文本。在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。
dtd实体:
DTD 实例:
<!ENTITY writer "Donald Duck.">
<!ENTITY copyright "Copyright runoob.com">
XML 实例:
<author>&writer;©right;</author>
注意: 一个实体由三部分构成: 一个和号 (&), 一个实体名称, 以及一个分号 (;)。
声明属性 :在DTD 中,属性通过 ATTLIST 声明来进行声明。
属性声明使用下列语法:元素名 属性名 属性类型(如ID表示唯一) 属性值(#REQUIRED 属性值是必需的,
#IMPLIED 属性不是必需的,#FIXED value 属性值是固定的)
<!ATTLIST element-name attribute-name attribute-type attribute-value>
(2)Schema约束文档:
重要笔记:
xmlns:给命名空间起一个唯一名字或默认(不命名前缀,则默认使用)。
xsi:schemaLocation:命名空间 约束文件的路径(前面的命名空间必须和该约束文档里面定义的命名空间一样才行)。
targetNamespace:给该约束文档起一个命名空间。
注意:这两个命名空间不需要引入xsd约束文件。
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
//固定写法,因为要用该名称空间下的名称(如element、name、type等,xs是别名,不起别名就要用http://www.w3.org/2001/XMLSchema这个名称空间替换别名)
xmlns="http://www.itcast.cn/xml"
//给当前约束文档定义一个名称空间,自己定义
targetNamespace="http://www.itcast.cn/xml" elementFormDefault="qualified">
//targetNamespace指目标名称空间:使用该约束文档要用的,和该约束文档名称空间一致。
//elementFormDefault可以不用,不会有什么问题。
<xs:element name="students" type="studentsType"/>
<xs:complexType name="studentsType">
<xs:sequence>
<xs:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="studentType">
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="age" type="ageType"/>
<xs:element name="sex" type="sexType"/>
</xs:sequence>
<xs:attribute name="number" type="numberType" use="required"/>
</xs:complexType>
<xs:simpleType name="ageType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="0"/>
<xs:maxInclusive value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="sexType">
<xs:restriction base="xs:string">
<xs:enumeration value="male"/>
<xs:enumeration value="female"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="numberType">
<xs:restriction base="xs:string">
<xs:pattern value="heima_\d{4}"/>
</xs:restriction>
</xs:simpleType>
</xs:schema>
引用约束文档:
<a:students xmlns:xs="http://www.w3.org/2001/XMLSchema-instance"
xs:schemaLocation="http://www.itcast.cn/xml student.xsd
http://www.itcast.cn/xml student.xsd //第二个约束文档位置
"
//xs名称空间下的schemalacaton表示:名称空间http://www.itcast.cn/xml所在的约束文件位置或地址。
xmlns:a="http://www.itcast.cn/xml"
//引入约束文档的约束空间,前缀为a
xmlns="http://www.itcast.cn/xml"
//引入第二个约束文档,不同约束文档之间前缀不能相同,但是只有一个约束文档可以省略,或者有一个省略。
>
<!-- 显示 schema 中用到的元素和数据类型来自命名空间 "http://www.w3.org/2001/XMLSchema-instance"。
同时它还规定了来自命名空间 "http://www.w3.org/2001/XMLSchema" 的元素和数据类型应该使用前缀 xs:-->
//使用第一个名称空间的约束
<a:student number="heima_0001">
<a:name>zhangsna</a:name>
<a:age>22</a:age>
<a:sex>male</a:sex>
</a:student>
//使用第二个名称空间的约束,但是引入的两个约束文档是同一个,所以这里没意义(使用一种就够了)。
<student number="heima_0000">
<name>a</name>
<age>2</age>
<sex>female</sex>
</student>
</a:students>二、解析器。
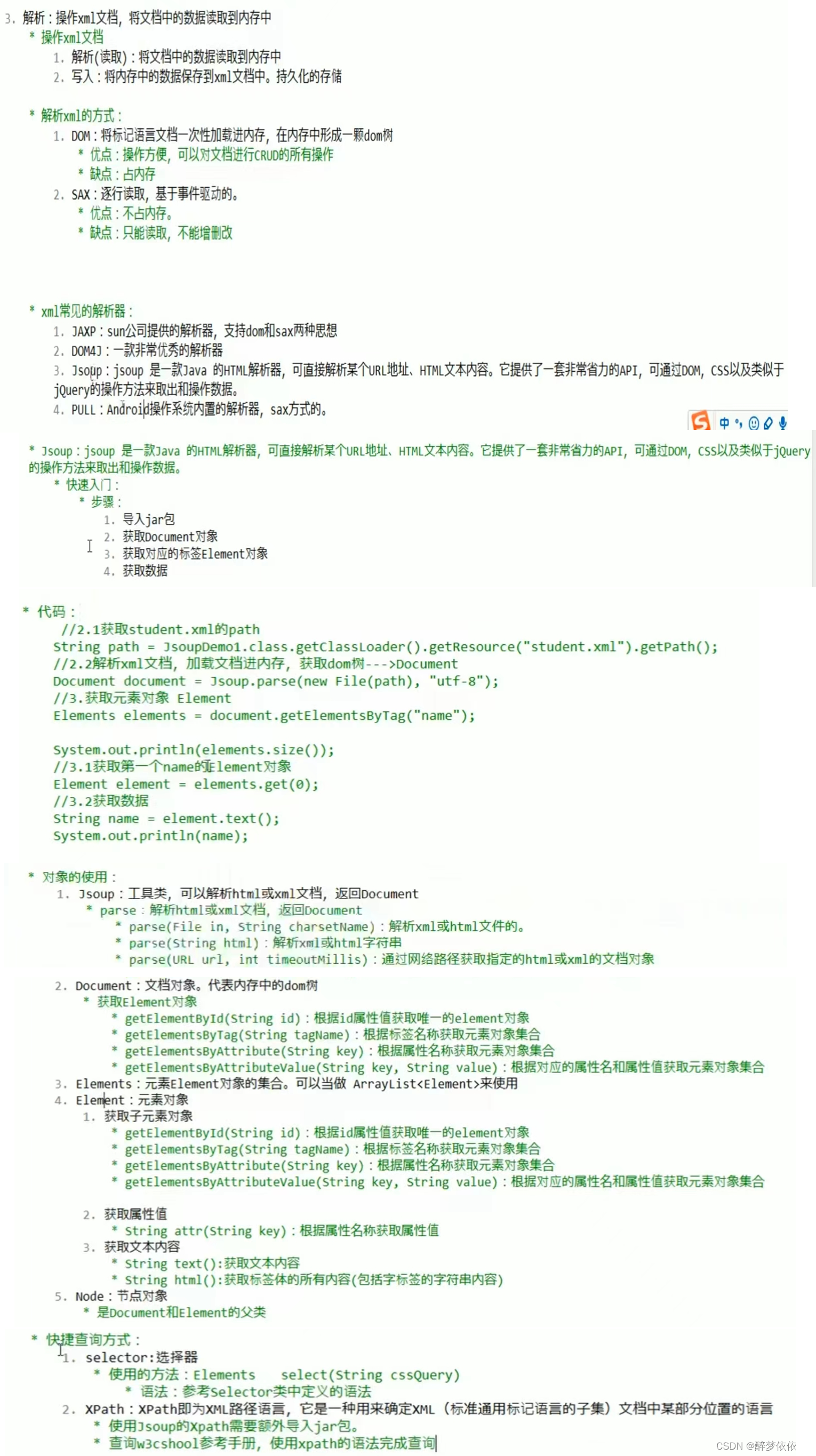
XPath案例:
public class Demo {
public static void main(String[] args) throws IOException, XpathSyntaxErrorException {
Document document = Jsoup.parse(new File("src/student.xml"));
//1.根据document对象,创建JXDocument对象
JXDocument jxDocument=new JXDocument(document);
//2.结合xpath语法查询
//2.1查询所有student标签
List<JXNode> jxNodes = jxDocument.selN("//student");
for (JXNode jx:jxNodes) {
System.out.println(jx);
// Element element = jx.getElement();
}
System.out.println("-------------------");
//2.2查询所有student标签下的name标签
List<JXNode> jxNodes1 = jxDocument.selN("//student/name");
for (JXNode j : jxNodes1) {
System.out.println(j);
}
System.out.println("---------------------");
//2.3查询student标签下带有id属性的name标签
// List<JXNode> jxNodes2 = jxDocument.selN("//student[@number]/name[@id]");//增加了条件
List<JXNode> jxNodes2 = jxDocument.selN("//student/name[@id]");
for (JXNode j2: jxNodes2) {
System.out.println(j2);
}
System.out.println("-------------------");
//2.4查询student标签下带有id属性的name标签,并且id属性值为itcast
List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode j3: jxNodes3) {
System.out.println(j3);
}
}
}
笔记:xpath是不属于jsoup解析器的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









