



 本文介绍了如何在Kubernetes集群中优雅地关闭Pod,确保应用程序能够正常处理完毕当前任务再退出,减少更新过程中对服务的影响。
本文介绍了如何在Kubernetes集群中优雅地关闭Pod,确保应用程序能够正常处理完毕当前任务再退出,减少更新过程中对服务的影响。
原文标题:Gracefully Shutting Down Pods in a Kubernetes Cluster
发布时间:Jan 26, 2019
原文链接:https://blog.gruntwork.io/zero-downtime-server-updates-for-your-kubernetes-cluster-902009df5b33
文章作者:yorinasub17
这是我们实现 Kubernetes 集群零停机时间更新的第二部分。在本系列的第一部分中,我们列举出了简单粗暴地使用kubectl drain 命令清除集群节点上的 Pod 的问题和挑战。在这篇文章中,我们将介绍解决这些问题和挑战的手段之一:优雅地关闭 Pod。
Pod驱逐的生命周期
默认情况下,kubectl drain命令驱逐节点上的 Pod 时会遵循 Pod 的生命周期,这意味着整个过程会遵守以下规则:
kubectl drain将向控制中心发出删除目标节点上的 Pod 的请求。随后,请求将通知目标节点上的kubelet开始关闭 Pod。节点上的
kubelet将会调用 Pod 里的preStop钩子。当
preStop钩子执行完成后,节点上的kubelet会向Pod容器中运行的程序发送TERM信号 (SIGTERM)。节点上的
kubelet将最多等待指定的宽限期(在pod上指定,或从命令行传入;默认为30秒)然后关闭容器,然后强行终止进程(使用SIGKILL)。注意,这个宽限期包括执行preStop钩子的时间。
译注:Kubelet 终止Pod前的等待宽限期有两种方式指定
在Pod定义里通过Pod模板的spec.terminationGracePeriodSeconds 设定
kubectl delete pod {podName} --grace-period=60
基于此流程,我们可以利用应用程序 Pod 中的preStop钩子和信号处理来正常关闭应用程序,以便在最终终止应用程序之前对其进行“清理”。例如,假如有一个工作进程从队列中读取信息然后处理任务,我们可以让应用程序捕获 TERM 系统信号,以指示该应用程序应停止接受新任务,并在所有当前任务完成后停止运行。或者,如果运行的应用程序无法修改以捕获 TERM 信号(例如第三方应用程序),则可以使用preStop钩子来实现该服务提供的自定义API,来正常关闭应用。
在我们的示例中,Nginx 默认情况下不能处理 TERM 信号,因此,我们将改为依靠 Pod 的 preStop钩子实现正常停止Nginx。我们将修改资源定义,将生命周期钩子添加到容器的spec定义中,如下所示:
lifecycle:
preStop:
exec:
command: [
# Gracefully shutdown nginx
"/usr/sbin/nginx", "-s", "quit"
]
应用此配置后,在将 TERM 信号发送给容器中的Nginx进程之前,kebulet 调用 Pod 的生命周期钩子发出命令 / usr / sbin / nginx -s quit。请注意,由于该命令将会正常停止 Nginx 进程和 Pod,因此 TERM 信号实际上在这个例子中是一个空操作。
在定义文件添加了生命周期钩子后,整个 Deployment 资源的定义变成了下面这样
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: [
# Gracefully shutdown nginx
"/usr/sbin/nginx", "-s", "quit"
]
停机后的后续流量
使用上面的preStop钩子正常关闭 Pod 可以确保 Nginx 在处理完现存流量有才会停止。但是,你可能会发现,Nginx 容器在关闭后仍会继续接收到流量,从而导致服务出现停机时间。
为了了解造成这个问题的原因,让我们来看一个示例图。假定该节点已接收到来自客户端的流量。应用程序会产生一个工作线程来处理请求。我们用在 Nginx Pod 示例图内的圆圈表示该工作线程。

假设在工作线程处理请求的同时,集群的运维人员决定对 Node1 进行维护。运维运行了kubectl drain node-1 后,节点上的kubelet 会执行 Pod 设置的preStop钩子,开始进入Nginx进程正常关闭的流程。
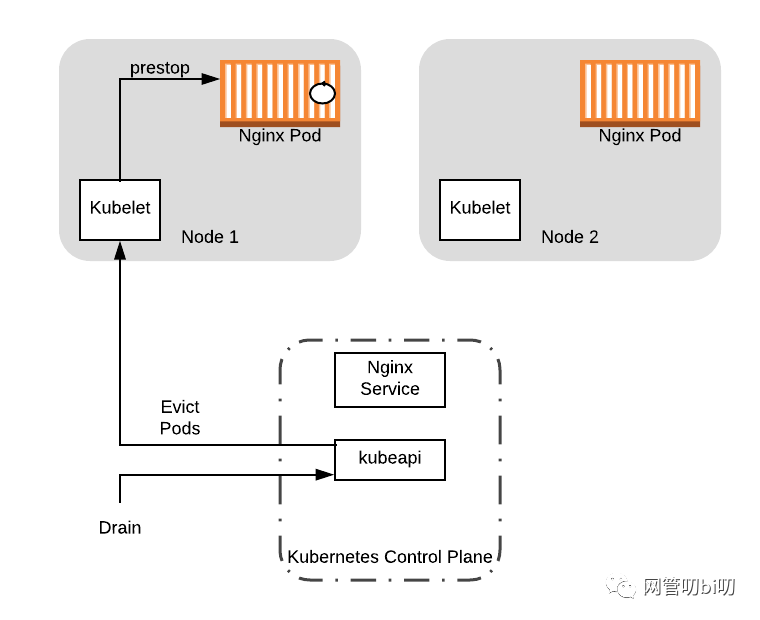
由于 Nginx 仍要处理已存流量的请求,所以进入正常关闭流程后 Nginx 不会马上终止进程,但是会拒绝处理后续到达的流量,向新请求返回错误。
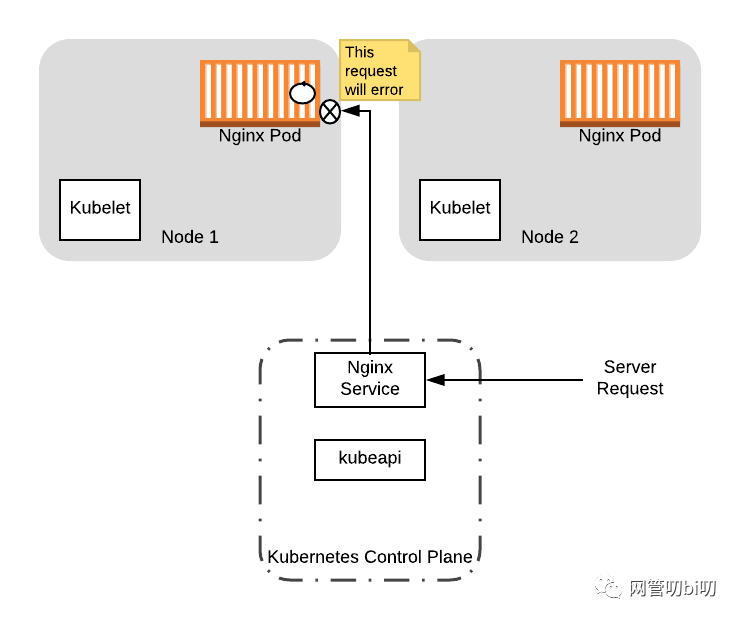
在这个时间点,假设一个新的服务请求到达了 Pod 上层的 Service,因为此时 Pod 仍然是上层 Service 的Endpoint,所以这个即将关闭的 Pod 仍然可能会接收到 Service 分发过来的请求。如果 Pod 真的接收到了分发过来的新请求 Nginx 就会拒绝处理并返回错误。
译注:推荐阅读学练结合快速掌握K8s Service控制器
最终 Nginx 将完成对原始已存请求的处理,随后kubelet会删除 Pod,节点完成排空。
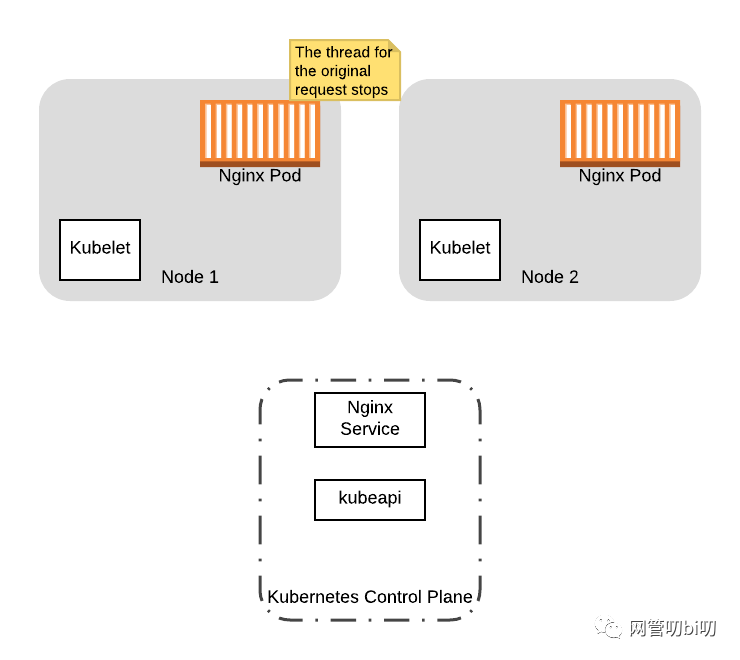
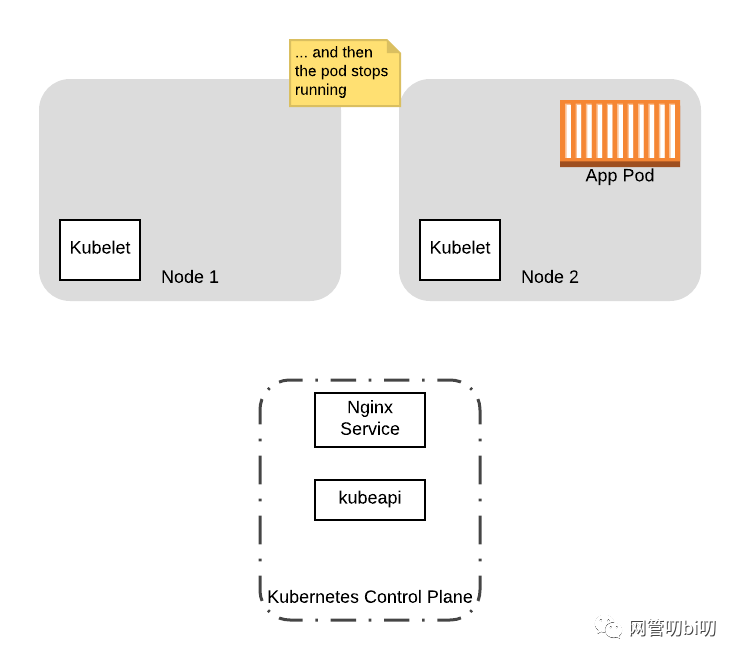
为什么会这样呢?如何避免在Pod执行关闭期间接受到来自客户端的请求呢?在本系列的下一部分中,我们会更详细地介绍 Pod 的生命周期,并给出如何在 preStop 钩子中引入延迟为 Pod 进行摘流,以减轻来自 Service 的后续流量的影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









