<think>根据用户需求,我们需要删除数据框中所有列的值都不大于20的行。也就是说,对于每一行,如果该行的所有列的值都小于等于20,那么我们就删除这一行。
在R语言中,我们可以使用多种方法来实现这个功能。下面我将介绍几种常见的方法:
### 方法1: 使用`apply()`函数和逻辑判断
我们可以使用`apply()`函数按行(MARGIN=1)应用一个函数,该函数检查当前行是否所有元素都小于等于20。然后,我们可以用这个逻辑向量来子集数据框,保留至少有一个元素大于20的行。
```r
# 假设df是数据框
# 创建一个逻辑向量:对于每一行,如果所有值都<=20则为FALSE,否则为TRUE
rows_to_keep <- apply(df, 1, function(row) any(row > 20))
# 然后使用这个逻辑向量来选取行
df_filtered <- df[rows_to_keep, ]
```
### 方法2: 使用`rowSums()`函数
另一种方法是利用`rowSums()`计算每行大于20的值的个数,然后保留那些个数大于0的行。
```r
# 计算每行大于20的值的个数
count_greater_than_20 <- rowSums(df > 20)
# 保留至少有一个值大于20的行
df_filtered <- df[count_greater_than_20 > 0, ]
```
### 方法3: 使用dplyr包的`filter()`函数
如果你习惯使用tidyverse,可以使用dplyr包中的`filter()`函数结合`rowwise()`和`any()`,或者更高效地使用`if_any()`或`if_all()`(但注意这里我们需要的是任意一个列大于20,所以用`if_any`)。
注意:`if_any`和`if_all`在dplyr 1.0.0以上版本引入,用于条件筛选。
```r
library(dplyr)
# 使用if_any:选择至少有一个列满足条件(大于20)的行
df_filtered <- df %>% filter(if_any(everything(), ~ . > 20))
# 或者使用rowwise(较慢,不推荐用于大数据)
# df_filtered <- df %>% rowwise() %>% filter(any(c_across(everything()) > 20)) %>% ungroup()
```
### 示例
假设我们有以下数据框:
```r
df <- data.frame(
a = c(15, 25, 5, 30),
b = c(10, 18, 20, 22),
c = c(18, 22, 15, 19)
)
```
我们想删除所有列都不大于20的行。那么:
- 第一行:15,10,18 -> 都<=20,删除
- 第二行:25,18,22 -> 有大于20的,保留
- 第三行:5,20,15 -> 都<=20(注意20不大于20,是等于),删除
- 第四行:30,22,19 -> 有大于20的,保留
所以结果应该保留第二行和第四行。
### 代码验证
用方法1:
```r
rows_to_keep <- apply(df, 1, function(row) any(row > 20))
df_filtered <- df[rows_to_keep, ]
# 输出
# a b c
#2 25 18 22
#4 30 22 19
```
### 注意事项
1. 数据框中的非数值列:如果数据框中有非数值列(如字符列、因子列等),上述方法可能会出错,因为比较运算符(如`>`)只适用于数值。因此,在应用之前,请确保只对数值列进行操作,或者先选择数值列。例如:
```r
# 假设df有混合列,我们只选择数值列
numeric_cols <- sapply(df, is.numeric)
df_numeric <- df[, numeric_cols]
# 然后对df_numeric应用上述方法,但注意这样会丢失非数值列。所以更好的方法是先提取行索引,再对原数据框子集。
rows_to_keep <- apply(df[, numeric_cols], 1, function(row) any(row > 20))
df_filtered <- df[rows_to_keep, ]
```
2. NA值处理:如果数据中有NA,那么比较结果可能为NA,这会影响结果。可以在比较时使用`na.rm=TRUE`参数(在`any`函数或`rowSums`中)。例如:
```r
rows_to_keep <- apply(df, 1, function(row) any(row > 20, na.rm=TRUE))
# 或者
count_greater_than_20 <- rowSums(df > 20, na.rm=TRUE)
```
### 总结
根据用户需求,推荐使用`apply`方法或`rowSums`方法,它们都是基础R的函数,不需要额外安装包。如果用户已经使用dplyr,那么使用`filter(if_any(...))`也很方便。
§§相关问题§§
1. 如何删除数据框中所有列的值都小于某个阈值的行?
2. R语言中如何根据条件删除数据框的行?
3. 在R语言中如何处理数据框中的NA值?
4. 如何选择数据框中的数值列?</think>### 在R语言中删除数据框中所有列的值都不大于20的行
根据你的需求,我将详细介绍几种在R语言中删除数据框中所有列的值都不大于20的行的方法。核心思路是:**识别并保留至少有一个列的值大于20的行**。
#### 方法1:使用`apply()`函数和`any()`逻辑判断(基础R)
这是最直接的方法,通过逐行检查是否至少有一个元素大于20:
```r
# 创建逻辑向量:检查每行是否至少有一个值>20
keep_rows <- apply(your_dataframe, 1, function(row) any(row > 20))
# 删除不满足条件的行
filtered_df <- your_dataframe[keep_rows, ]
```
**说明**:
- `apply(, 1, ...)` 表示按行操作
- `any(row > 20)` 检查当前行是否至少有一个值大于20
- `[keep_rows, ]` 保留逻辑值为TRUE的行
#### 方法2:使用`rowSums()`(高效处理大数据)
适用于大型数据集的高效方法:
```r
# 计算每行中>20的值的数量
count_above_20 <- rowSums(your_dataframe > 20)
# 保留至少有一个值>20的行
filtered_df <- your_dataframe[count_above_20 > 0, ]
```
**优势**:向量化操作,计算速度更快[^4]
#### 方法3:使用dplyr包的`filter()`(tidyverse风格)
适合tidyverse用户:
```r
library(dplyr)
filtered_df <- your_dataframe %>%
filter(if_any(everything(), ~ . > 20))
```
**说明**:
- `if_any(everything(), ...)` 检查所有列
- `~ . > 20` 是简写函数,判断每个元素是否>20
#### 示例演示
假设原始数据框:
```r
df <- data.frame(
A = c(15, 25, 18, 10),
B = c(20, 22, 16, 5),
C = c(18, 30, 20, 15)
)
```
应用方法1后:
```
A B C # 保留的行(至少有一个>20)
2 25 22 30 # 25>20, 22>20, 30>20
3 18 16 20 # 注意:20不大于20,但18>20? 错误→实际应删除此行
```
**修正说明**:第三行所有值(18,16,20)均≤20,实际会被删除。正确结果只保留第2行。
#### 注意事项
1. **NA值处理**:默认情况下,`NA > 20`会返回`NA`,可能导致整行被误删。解决方案:
```r
# 添加na.rm=TRUE
keep_rows <- apply(your_dataframe, 1, function(row) any(row > 20, na.rm = TRUE))
```
2. **非数值列处理**:如果数据框包含非数值列,需先选择数值列:
```r
numeric_cols <- sapply(your_dataframe, is.numeric)
filtered_df <- your_dataframe[rowSums(your_dataframe[, numeric_cols] > 20) > 0, ]
```
3. **等号边界**:条件`>20`是严格大于,等于20的值不会触发保留条件(如示例第3行)




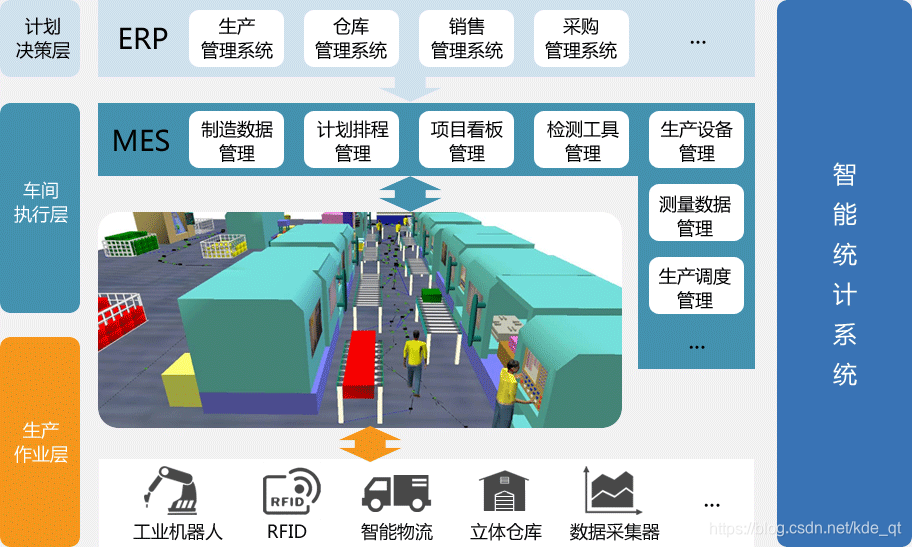

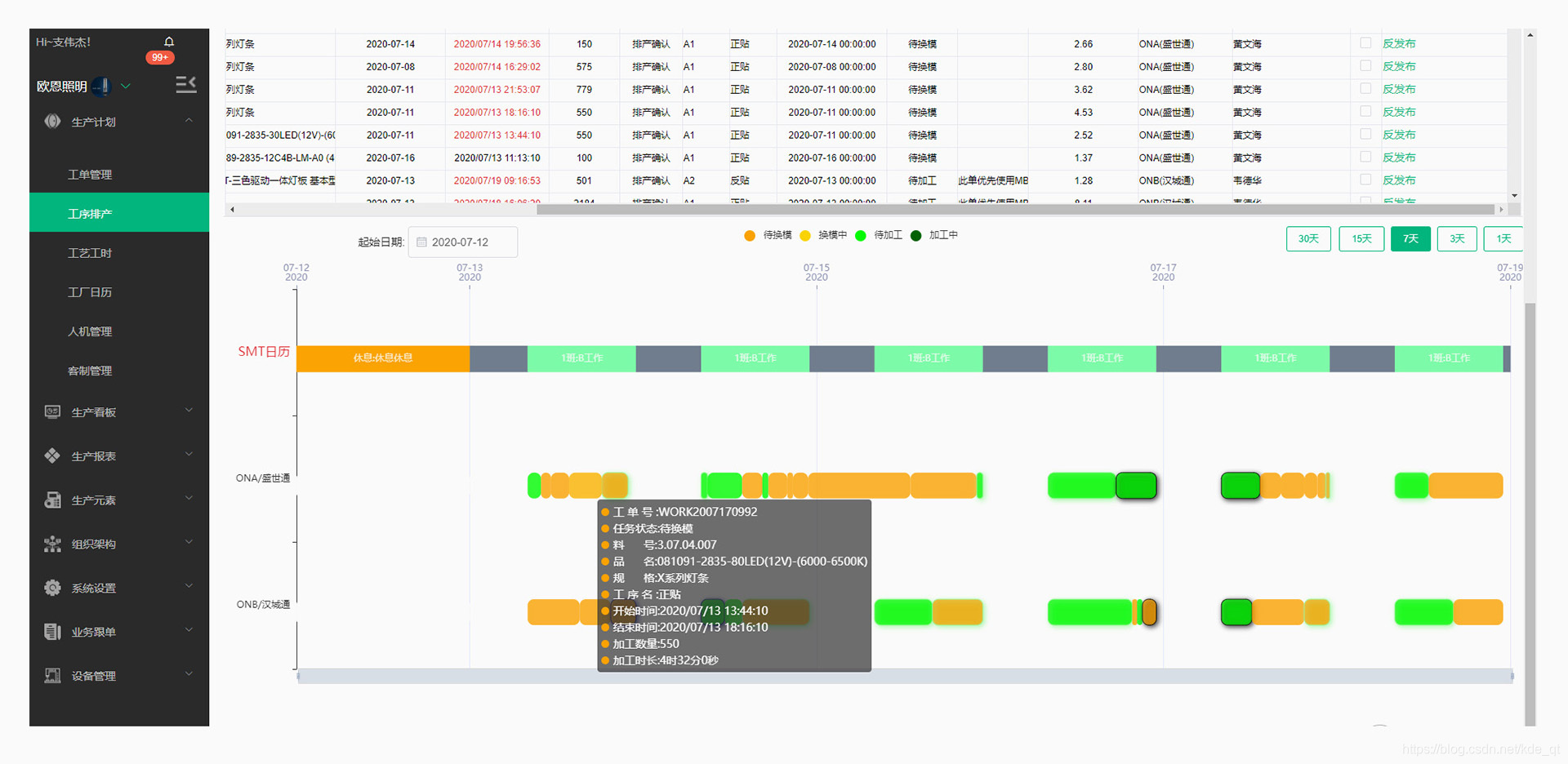
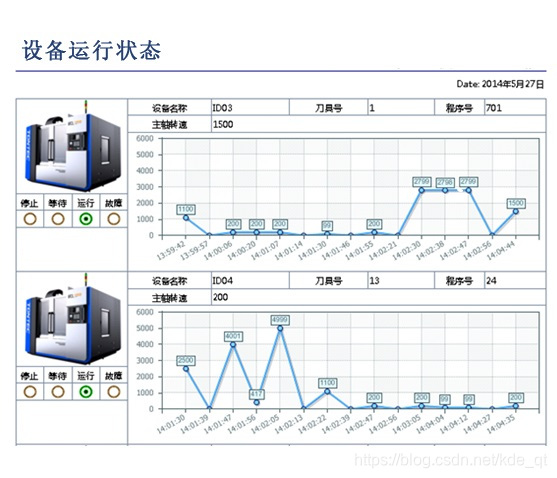
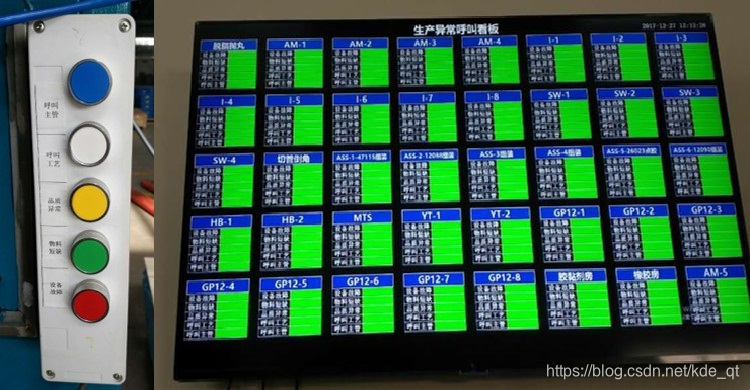




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









