




项目简介
VoxCPM 是由 OpenBMB 团队推出的开源多模态语音大模型,聚焦于语音理解、语音生成、语音问答、语音指令跟随等多种任务。VoxCPM 采用主流的编码-融合-解码架构,结合大规模语音-文本数据预训练和多任务微调,具备强大的多语言、多模态泛化能力,适合学术研究、工业应用、AI Agent、语音助手等场景。
主要特性:
- 支持语音转文本(ASR)、语音问答、语音指令跟随、语音内容生成等多任务
- 多模态输入(语音+文本),多语言适配
- 基于Transformer/LLM架构,具备强泛化能力
- 开源训练代码、模型权重与推理API
- 支持本地化部署与云端服务
模型结构深度解析
整体架构
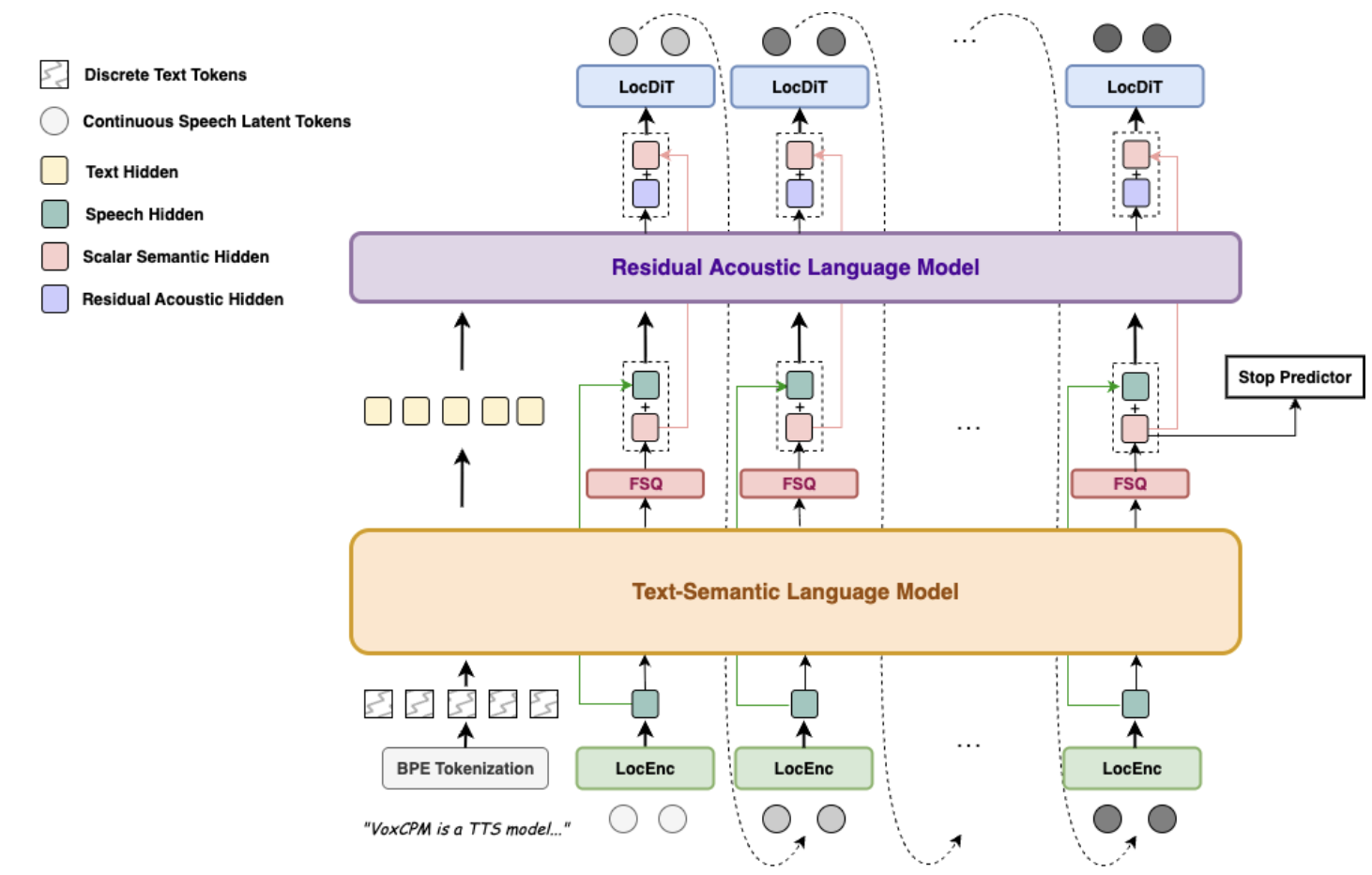
VoxCPM 采用“语音编码器 + 多模态融合 + 语言模型解码器”架构,核心模块包括:
- 语音编码器:将原始语音信号转为高维特征
- 多模态融合层:将语音特征与文本特征对齐融合
- 语言模型(LLM):负责理解、推理、生成文本或语音内容
- 输出头:根据任务输出文本、标签、语音等
架构图:
语音输入
↓
语音编码器(Conformer/Transformer/CNN)
↓
多模态融合层(Cross Attention/Concat/MLP)
↓
语言模型(LLM/Transformer)
↓
输出头(文本/标签/语音)
语音编码器设计
- 主流采用 Conformer 或 Transformer 结构,兼顾局部特征与全局建模能力
- 输入为原始语音波形或梅尔频谱(Mel-Spectrogram)
- 输出为高维语音特征序列
import torch.nn as nn
class SpeechEncoder(nn.Module):
def __init__(self):
super().__init__()
self.conformer = ConformerEncoder(
input_dim=80, # Mel谱维度
num_layers=12,
hidden_dim=512,
num_heads=8
)
def forward(self, x):
return self.conformer(x)
语言模型与多模态融合
- 语言模型采用 CPM/LLaMA/BERT 等主流结构
- 多模态融合层采用 Cross Attention 或 MLP,将语音特征与文本特征对齐
- 支持语音+文本联合输入,提升复杂任务能力
融合层代码片段:
class MultiModalFusion(nn.Module):
def __init__(self):
super().__init__()
self.cross_attn = nn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











