



 本文深入探讨了Kafka中的数据采集和统计机制,包括使用滑动窗口进行精确统计,以及Measurable和Stat接口在数据记录和统计中的作用。通过SampledStat类的介绍,展示了Kafka如何通过样本采样和组合来计算平均值、最大值等统计信息。文章还提及了Rate和SampleRate在计算速率方面的应用,并以Follower Fetch副本流量统计为例进行分析。
本文深入探讨了Kafka中的数据采集和统计机制,包括使用滑动窗口进行精确统计,以及Measurable和Stat接口在数据记录和统计中的作用。通过SampledStat类的介绍,展示了Kafka如何通过样本采样和组合来计算平均值、最大值等统计信息。文章还提及了Rate和SampleRate在计算速率方面的应用,并以Follower Fetch副本流量统计为例进行分析。
温馨提示: 获得更好阅读体验请访问
在讲解kafka限流机制之前
我想先讲解一下Kafka中的数据采集和统计机制 你会不会好奇,kafka监控中,那些数据都是怎么计算出来的 比如下图这些指标
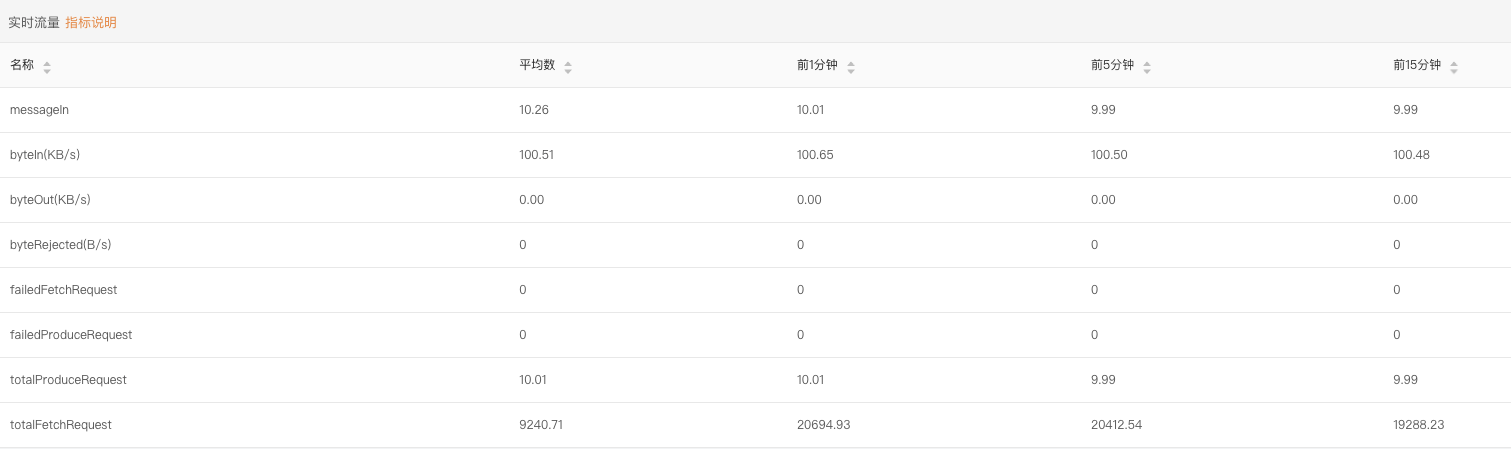
LogiKM监控图
这些数据都是通过Jmx获取的kafka监控指标, 那么我们今天老探讨一下,这些指标都是怎么被计算出来的
在开始分析之前,我们可以 自己思考一下
如果让你统计前一分钟内的流速,你会怎么统计才能够让数字更加精确呢?
我相信你脑海中肯定出现了一个词:滑动窗口
在kafka的数据采样和统计中,也是用了这个方法, 通过多个样本Sample进行采样,并合并统计
当然这一个过程少不了滑动窗口的影子
采集和统计类图
我们先看下整个Kafka的数据采集和统计机制的类图

数据采集和统计全类图
看着整个类图好像很复杂,但是最核心的就是两个Interface接口
Measurable: 可测量的、可统计的 Interface。这个Interface 有一个方法, 专门用来计算需要被统计的值的
/**
* 测量这个数量并将结果作为双精度返回
* 参数:
* config – 此指标的配置
* now – 进行测量的 POSIX 时间(以毫秒为单位)
* 返回:
* 测量值
*/
double measure(MetricConfig config, long now);
比如说返回 近一分钟的bytesIn
Stat: 记录数据, 上面的是统计,但是统计需要数据来支撑, 这个Interface就是用来做记录的,这个Interface有一个方法
/**
* 记录给定的值
* 参数:
* config – 用于该指标的配置
* value – 要记录的值
* timeMs – 此值发生的 POSIX 时间(以毫秒为单位)
*/
void record(MetricConfig config, double value, long timeMs);
有了这两个接口,就基本上可以记录数据和数据统计了
当然这两个接口都有一个 MetricConfig 对象
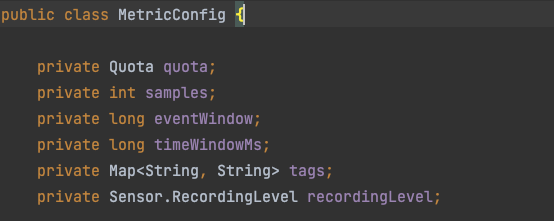
MetricConfig
这是一个统计配置类, 主要是定义 采样的样本数、单个样本的时间窗口大小、单个样本的事件窗口大小、限流机制 有了这样一个配置了,就可以自由定义时间窗口的大小,和采样的样本数之类的影响最终数据精度的变量。
这里我需要对两个参数重点说明一下
单个样本的时间窗口大小: 当前记录时间 - 当前样本的开始时间 >= 此值 则需要使用下一个样本。 单个样本的事件窗口大小: 当前样本窗口时间次数 >= 此值 则需要使用下一个样本
在整个统计中,不一定是按照时间窗口来统计的, 也可以按照事件窗口来统计, 具体按照不同需求选择配置
好了,大家脑海里面已经有了最基本的概念了,我们接下来就以一个kafka内部经常使用的 SampledStat 记录和统计的抽象类来好好的深入分析理解一下。
SampledStat 样本记录统计抽象类
这个记录统计抽象类,是按照采样的形式来计算的。 里面使用了一个或者多个样本进行采样统计 List<Sample> samples; 当前使用的样本: current 样本初始化的值: initialValue
SampledStat : 实现了MeasurableStat 的抽象类,说明它又能采集记录数据,又能统计分析数据
当然它自身也定义了有两个抽象方法
/** 更新具体样本的数值 (单个样本)**/
protected abstract void update(Sample sample, MetricConfig config, double value, long timeMs);
/**组合所有样本的数据 来统计出想要的数据 **/
public abstract double combine(List<Sample> samples, MetricConfig config, long now);
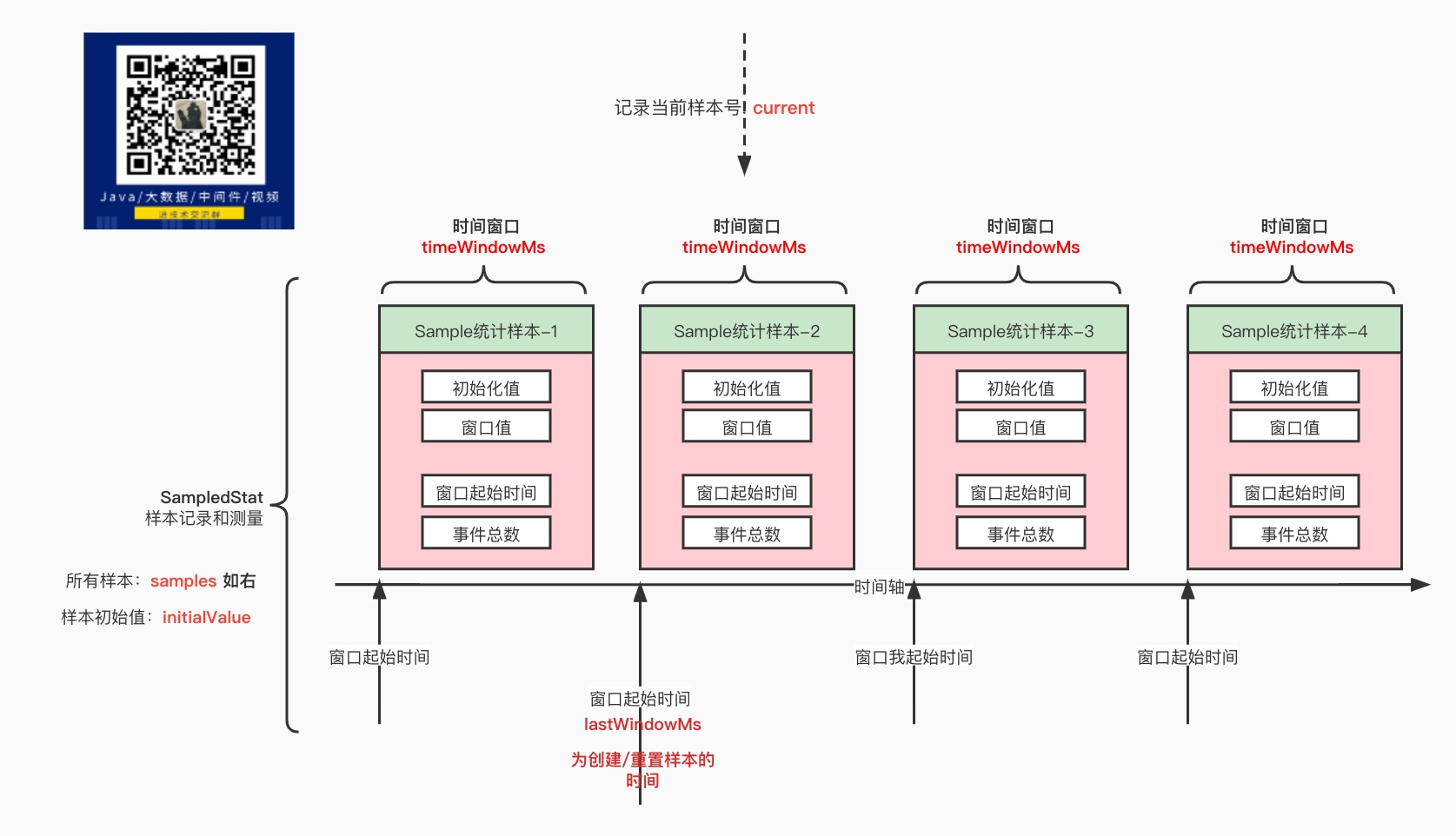
SampledStat图形化展示
如上图所示, 是一个SampledStat 的图形化展示, 其中定义了 若干个样本 Sample
记录数据
@Override
public void record(MetricConfig config, double value, long timeMs) {
Sample sample = current(timeMs);
if (sample.isComplete(timeMs, config))
sample = advance(config, timeMs);
update(sample, config, value, timeMs);
sample.eventCount += 1;
}
- 获取当前的Sample号,如果没有则创建一个新的Sample, 创建的时候设置 初始化值 和 Sample起始时间(当前时间) ,并保存到样品列表里面
- 判断这个Sample是否完成(超过窗口期),判断的逻辑是 当前时间 - 当前Sample的开始时间 >= 配置的时间窗口值 或者 事件总数 >= 配置的事件窗口值
/** 当前时间 - 当前Sample的开始时间 >= 配置的时间窗口值 或者 事件总数 >= 配置的事件窗口值 **/
public boolean isComplete(long timeMs, MetricConfig config) {
return timeMs - lastWindowMs >= config.timeWindowMs() || eventCount >= config.eventWindow();
}
- 如果这个Sample已经完成(超过窗口期), 则开始选择下一个窗口,如果下一个还没创建则创建新的,如果下一个已经存在,则重置这个Sample
- 拿到最终要使用的Sample后, 将数据记录到这个Sample中。具体怎么记录是让具体的实现类来实现的,因为想要最终统计的数据可以不一样,比如你只想记录Sample中的最大值,那么更新的时候判断是不是比之前的值大则更新,如果你想统计平均值,那么这里就让单个Sample中所有的值累加(最终会 除以 Sample数量 求平均数的)
- 记录事件次数+1。
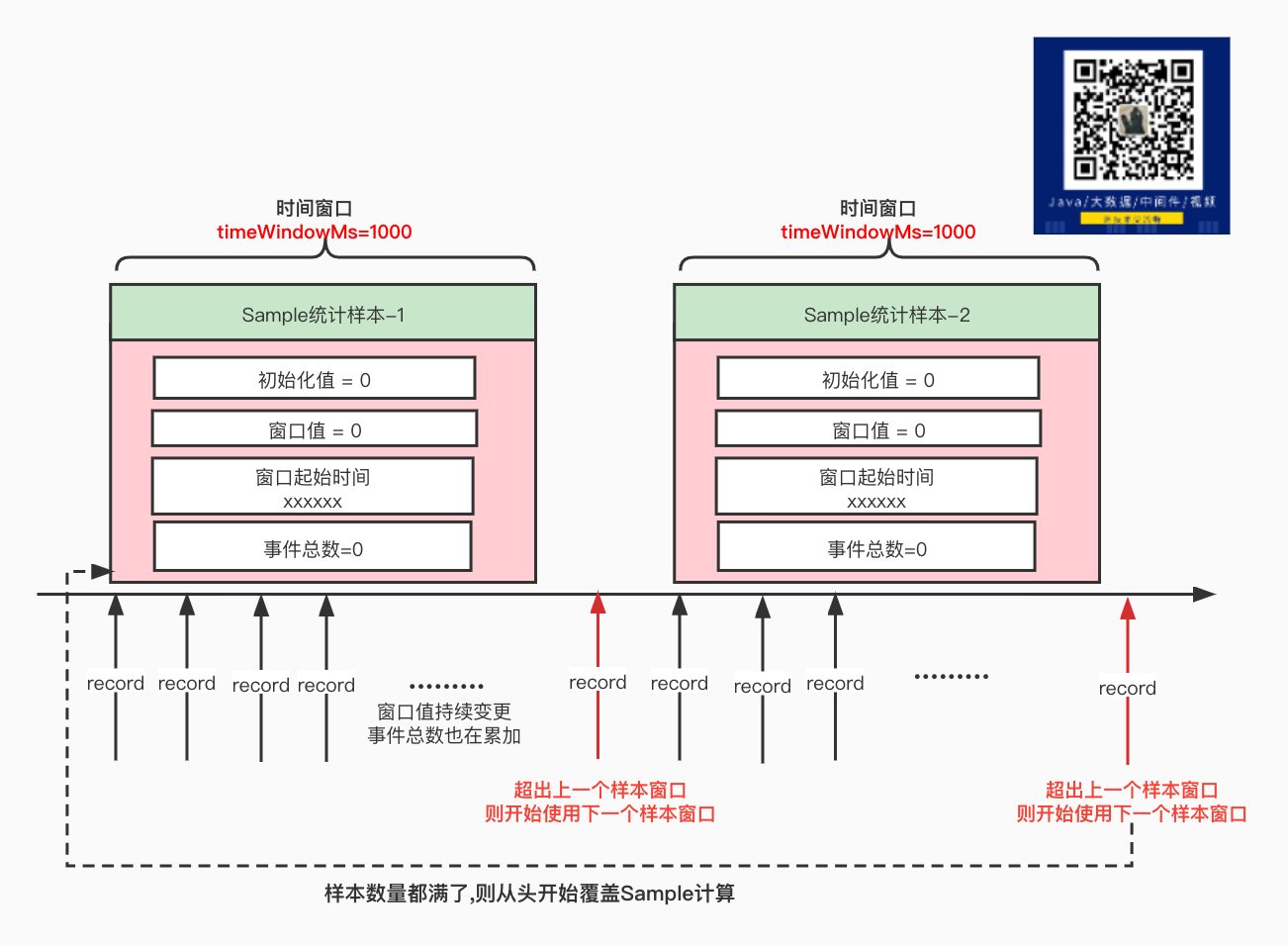
记录数据的展示图
统计数据
/** 测量 统计 数据**/
@Override
public double measure(MetricConfig config, long now) {
// 重置过期样本
purgeObsoleteSamples(config, now);
// 组合所有样本数据,并展示最终统计数据,具体实现类来实现该方法
return combine(this.samples, config, now);
}
- 先重置 过期样本 , 过期样本的意思是:当前时间 - 每个样本的起始事件 > 样本数量 * 每个样本的窗口时间 ; 就是滑动窗口的概念,只统计这个滑动窗口的样本数据, 过期的样本数据会被重置(过期数据不采纳), 如下图所示
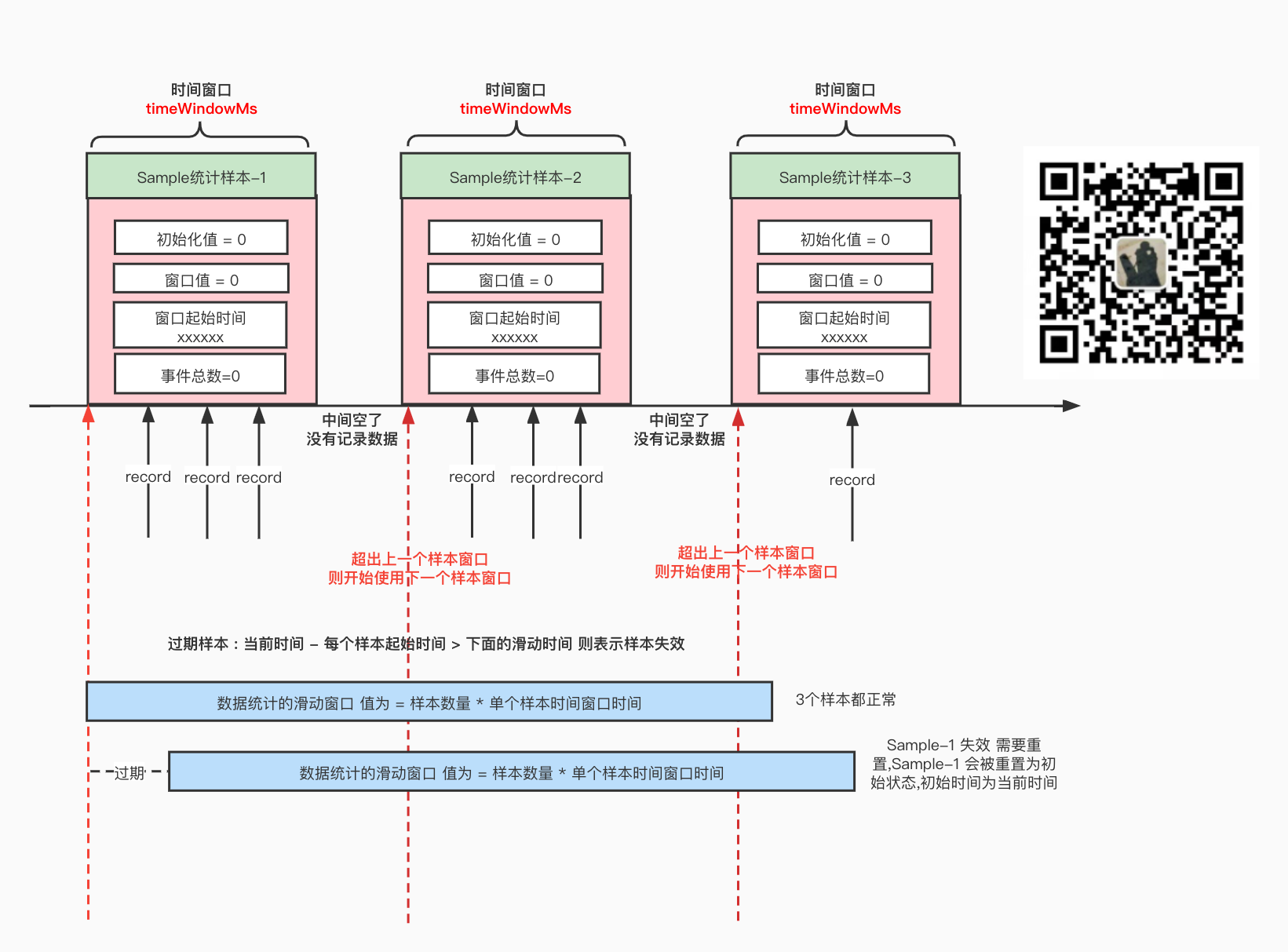
滑动窗口重置过期数据
- 组合所有样本数据并进行不同维度的统计并返回数值, 因为不同场景想要得到的数据不同,所以这个只是一个抽象方法,需要实现类来实现这个计算逻辑,比如如果是计算平均值 Avg, 它的计算逻辑就是把所有的样本数据值累加并除以累积的次数
那我们再来看看不同的统计实现类
Avg 计算平均值
一个简单的SampledStat实现类 它统计所有样本最终的平均值 每个样本都会累加每一次的记录值, 最后把所有样本数据叠加 / 总共记录的次数
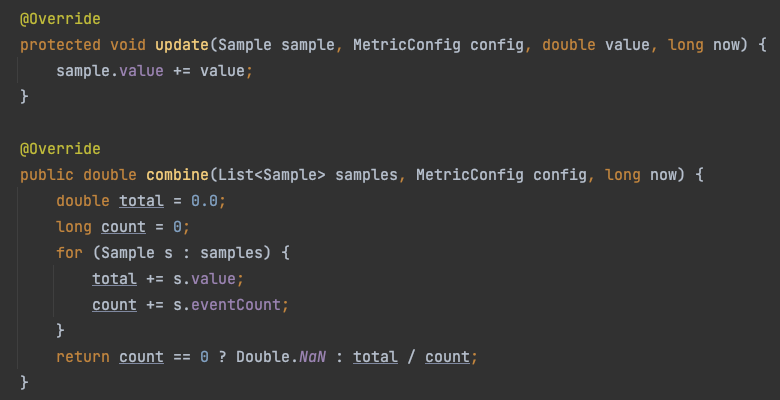
在这里插入图片描述
Max 计算最大值
每个样本都保存这个样本的最大值, 然后最后再对比所有样本值的最大值
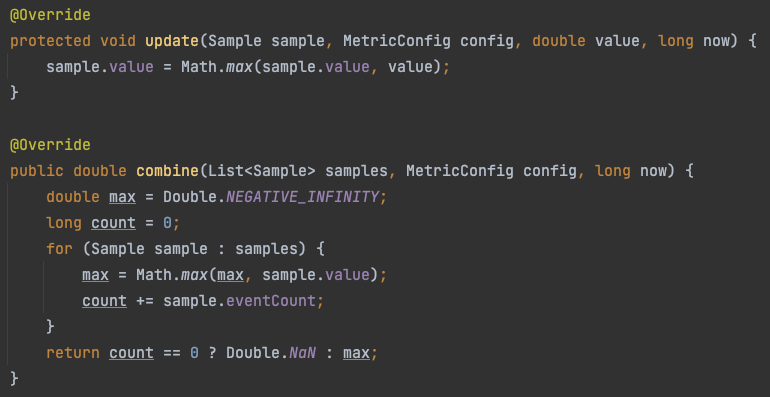
在这里插入图片描述
WindowedSum 所有样本窗口总和值
每个样本累积每一次的记录值, 统计的时候 把所有样本的累计值 再累积返回
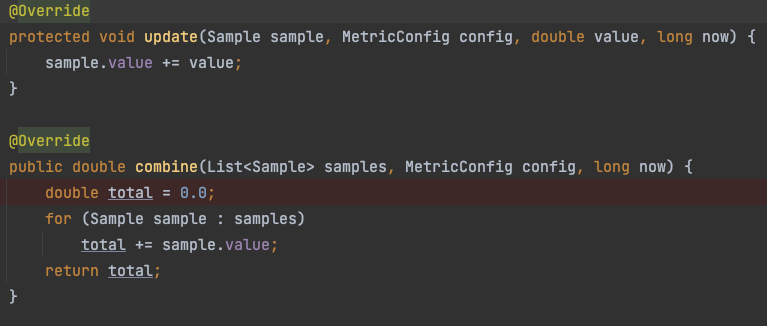
在这里插入图片描述
Rate 样本记录统计求速率
Rate 也是实现了 MeasurableStat接口的,说明 它也有 记录record 和 统计 measure 的方法, 实际上这个类 是一个组合类 ,里面组合了 SampledStat 和TimeUnit unit ,这不是很明显了么, SampledStat负责记录和统计, 得到的数据 跟时间TimeUnit做一下处理就得出来速率了, 比如SampledStat的实现类AVG可以算出来 被统计的 评价值, 但是如果我们再除以 一个时间维度, 是不是就可以得出 平均速率 了
如何计算统计的有效时间呢
这个有效时间 的计算会影响着最终速率的结果
public long windowSize(MetricConfig config, long now) {
// 将过期的样本给重置掉
stat.purgeObsoleteSamples(config, now);
// 总共运行的时候 = 当前时间 - 最早的样本的开始时间
long totalElapsedTimeMs = now - stat.oldest(now).lastWindowMs;
// 总时间/单个创建时间 = 多少个完整的窗口时间
int numFullWindows = (int) (totalElapsedTimeMs / config.timeWindowMs());
int minFullWindows = config.samples() - 1;
// If the available windows are less than the minimum required, add the difference to the totalElapsedTime
if (numFullWindows < minFullWindows)
totalElapsedTimeMs += (minFullWindows - numFullWindows) * config.timeWindowMs();
return totalElapsedTimeMs;
}
这是Rate的有效时间的计算逻辑,当然Rate 还有一个子类是 SampleRate

SampleRate的窗口Size计算逻辑
这个子类,将 有效时间的计算逻辑改的更简单, 如果运行时间<一个样本窗口的时间 则他的运行时间就是单个样本的窗口时间, 否则就直接用这个运行的时间, 这个计算逻辑更简单 它跟Rate的区别就是, 不考虑采样的时间是否足够多,我们用图来简单描述一下
SampleRate
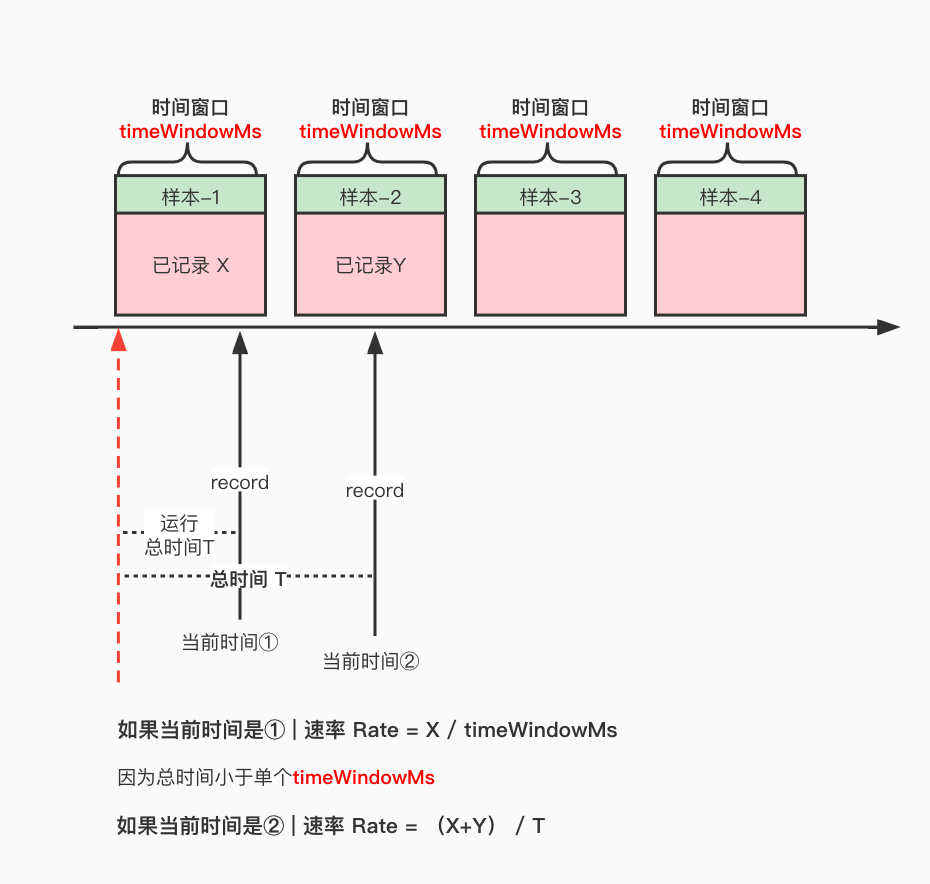
SampleRate 速率逻辑
Rate
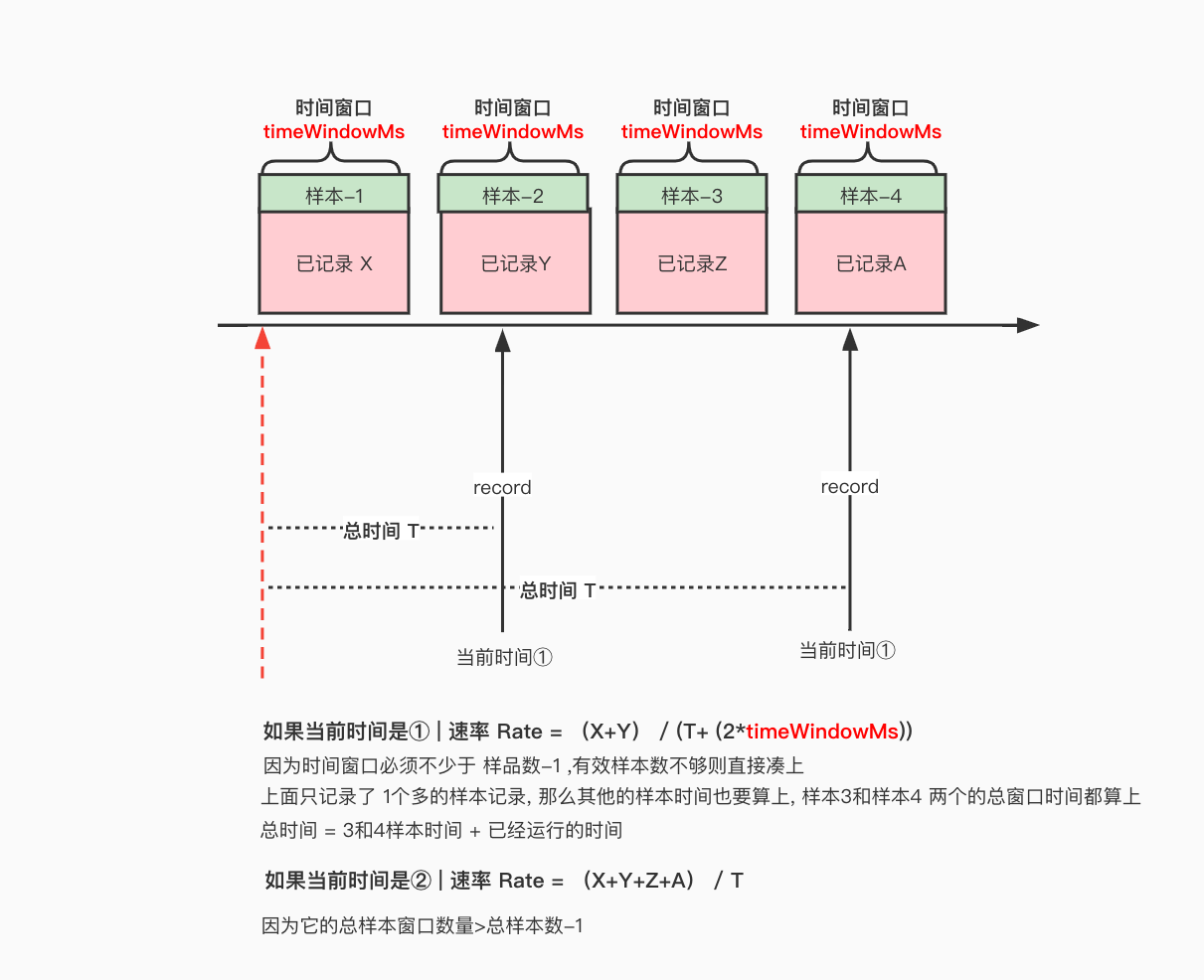
Rate 速率逻辑
Meter 包含速率和累积总指标的复合统计数据
这是一个CompoundStat的实现类, 说明它是一个复合统计, 可以统计很多指标在这里面 它包含速率指标和累积总指标的复合统计数据
底层实现的逻辑还是上面讲解过的
副本Fetch流量的速率统计 案例分析
我们知道 在分区副本重分配过程中,有一个限流机制,就是指定某个限流值,副本同步过程不能超过这个阈值。 做限流,那么肯定首先就需要统计 副本同步 的流速;那么上面我们将了这么多,你应该很容易能够想到如果统计了吧? 流速 bytes/s , 统计一秒钟同步了多少流量, 那么我们可以把样本窗口设置为 1s,然后多设置几个样本窗口求平均值。
接下来我们看看 Kafka是怎么统计的, 首先找到记录 Follower Fetch 副本流量的地方如下
ReplicaFetcherThread#processPartitionData
if(quota.isThrottled(topicPartition))
quota.record(records.sizeInBytes)
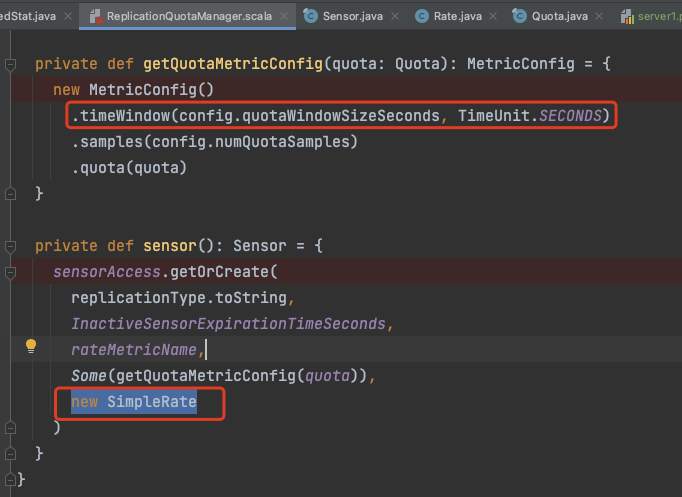
设置时间窗口配置
这里设置的 timeWindowMs 单个样本窗口时间= 1 s numQuotaSamples 样本数 = 11 当然这些都是可以配置的
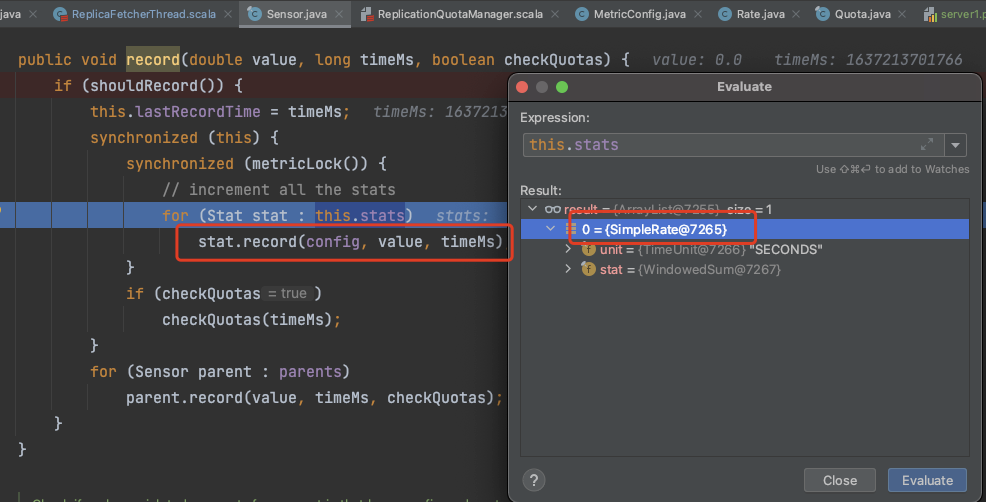
查看使用了哪个实现类
我们可以看到最终是使用了 SampleRate 来统计流量 !
Gauge 瞬时读数的指标
上面我们起始是主要讲解了Measurable接口, 它的父类是MetricValueProvider<Double> ,它没有方法,只是定义,当还有一个子接口是 Gauge ,它并不是上面那种采样的形式来统计数据, 它返回的是当前的值, 瞬时值 它提供的方法是 value() , Measurable提供的是measure()
这个在kafka中使用场景很少,就不详细介绍了。
好了,这一篇我们主要讲解了一下 Kafka中的数据采集和统计机制
那么 接下来下一篇,我们来聊聊 Kafka的监控机制, 如何把这些采集到的信息给保存起来并对外提供!!!
国内最大最权威的 Kafka中文社区 ,在这里你可以结交各大互联网Kafka大佬以及近2000+Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,免费加入中~


















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









