



 sparklyr 1.0已可通过CRAN直接下载使用,它提供针对Apache Spark的接口。该版本主要亮点包括:支持Arrow实现Spark和R间更快大数据集传输;支持XGBoost在分布式数据集训练梯度增强模型;用Broom转换Spark模型格式;支持TFRecords编写TensorFlow记录以支持深度学习。
sparklyr 1.0已可通过CRAN直接下载使用,它提供针对Apache Spark的接口。该版本主要亮点包括:支持Arrow实现Spark和R间更快大数据集传输;支持XGBoost在分布式数据集训练梯度增强模型;用Broom转换Spark模型格式;支持TFRecords编写TensorFlow记录以支持深度学习。
作者:Javier Luraschi
翻译:黄小伟,10年资深数据矿工。目前就职杭州有赞,欢迎加入有赞分析团队
sparklyr 1.0目前已经可以通过CRAN直接下载、安装使用!它提供了针对Apache Spark的接口,支持dplyr、MLlib、streaming、extensions等内容,以下是本次发布版本的主要亮点:
1. Arrow: 支持在Spark 和 R之间实现更快、更大数据集的传输
2. XGBoost: 支持在分布式数据集上训练梯度增强模型
3. Broom: 将Spark的模型转换为您熟悉的格式
4. TFRecords: 从Spark编写TensorFlow记录以支持深度学习工作流
install.packages("sparklyr")1. Arrow
Apache Arrow是一种用于内存数据的跨语言开发平台,您可以在Arrow及其他博客文章中阅读更多相关信息。在sparklyr 1.0中,我们从概念上将Arrow视为R和Spark之间的有效桥梁:

实际上,这意味着更快的数据传输和对更大数据集的支持。具体来说,此次改进了collect()、copy_to()和spark_apply()。 以下基准测试使用 bench包来进行。
我们将首先在具有1M和10M行的数据框上对copy_to()进行基准测试:
library(sparklyr)sc <- spark_connect(master = "local")bench::press(rows = c(10^6, 10^7), {bench::mark(arrow_on = {library(arrow)sparklyr_df <<- copy_to(sc, data.frame(y = 1:rows), overwrite = T)},arrow_off = if (rows <= 10^6) {if ("arrow" %in% .packages()) detach("package:arrow")sparklyr_df <<- copy_to(sc, data.frame(y = 1:rows), overwrite = T)} else NULL, iterations = 4, check = FALSE)})
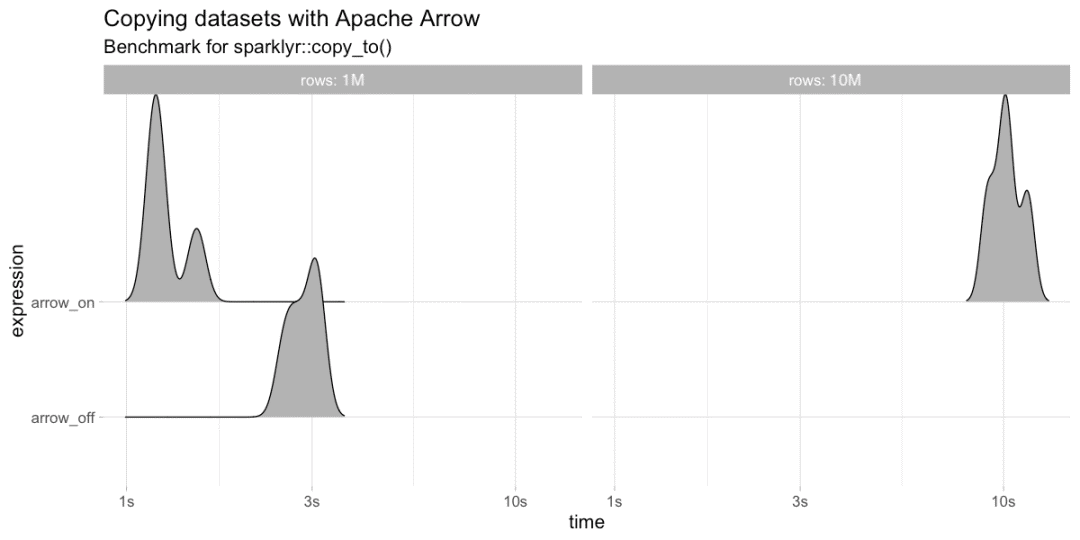
接下来,我们将基于10M和50M记录的collect()进行基准测试:
bench::press(rows = c(10^7, 5 * 10^7), {bench::mark(arrow_on = {library(arrow)collected <- sdf_len(sc, rows) %>% collect()},arrow_off = if (rows <= 10^7) {if ("arrow" %in% .packages()) detach("package:arrow")collected <- sdf_len(sc, rows) %>% collect()} else NULL, iterations = 4, check = FALSE)})
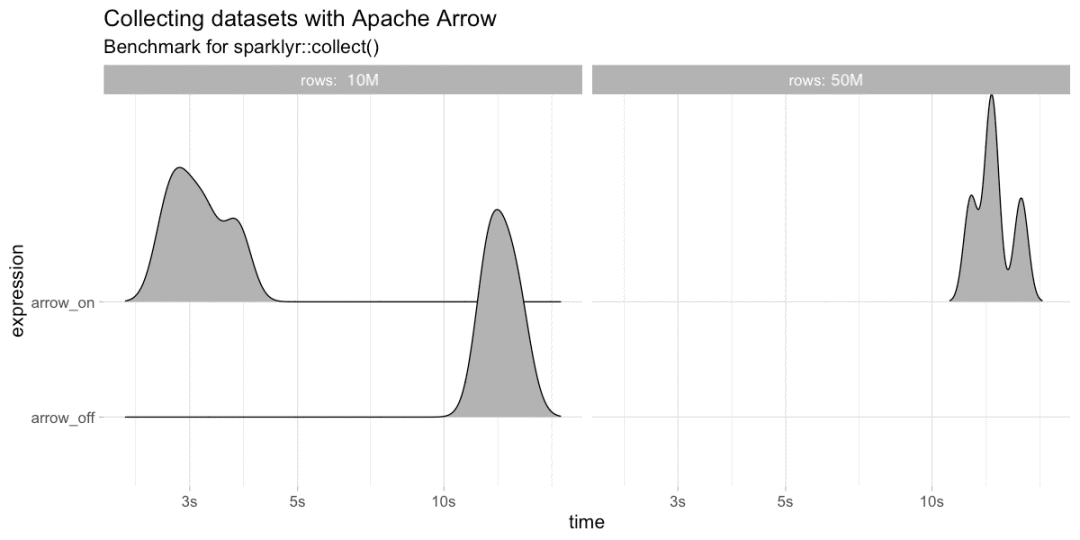
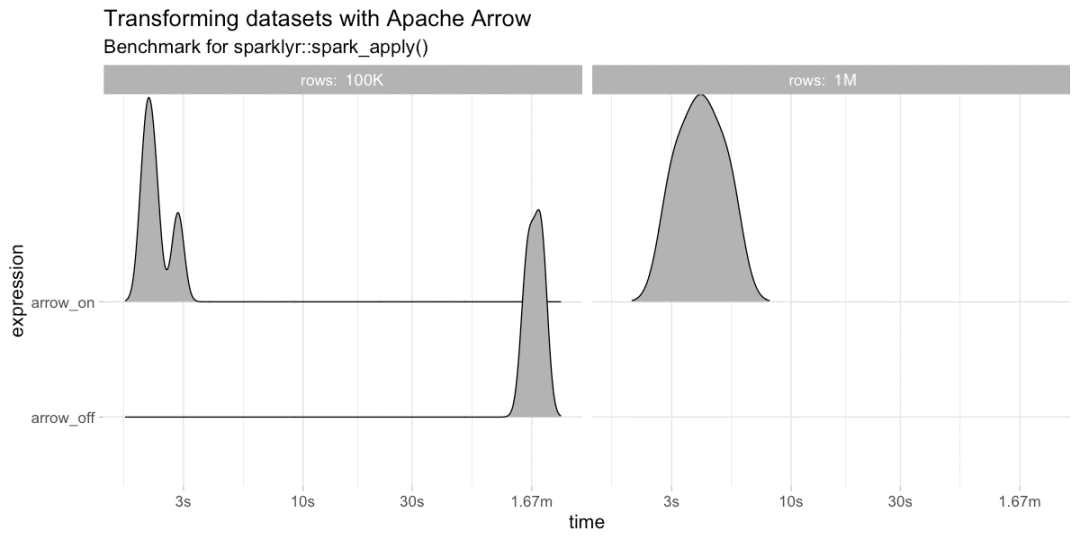
最后但并非最不重要的是,超过100K和1M行的spark_apply()显示了最显著的改进。 在Spark上运行R时,速度提高40倍。
bench::press(rows = c(10^5, 10^6), {bench::mark(arrow_on = {library(arrow)sdf_len(sc, rows) %>% spark_apply(~ .x / 2) %>% dplyr::count() %>% collect},arrow_off = if (rows <= 10^5) {if ("arrow" %in% .packages()) detach("package:arrow")sdf_len(sc, rows) %>% spark_apply(~ .x / 2) %>% dplyr::count() %>% collect} else NULL, iterations = 4, check = FALSE)})
2. XGBoost
sparkxgb是一个新的sparklyr扩展,可用于在Spark中训练XGBoost模型。 sparkxgb可可按如下方式安装:
install.packages("sparkxgb")然后我们可以使用xgboost_classifier()来训练和ml_predict()来轻松预测大型数据集:
library(sparkxgb)library(sparklyr)library(dplyr)sc <- spark_connect(master = "local")iris <- copy_to(sc, iris)xgb_model <- xgboost_classifier(iris,Species ~ .,num_class = 3,num_round = 50,max_depth = 4)xgb_model %>%ml_predict(iris) %>%select(Species, predicted_label, starts_with("probability_")) %>%glimpse()
#> Observations: ??#> Variables: 5#> Database: spark_connection#> $ Species <chr> "setosa", "setosa", "setosa", "setosa", "…#> $ predicted_label <chr> "setosa", "setosa", "setosa", "setosa", "…#> $ probability_versicolor <dbl> 0.003566429, 0.003564076, 0.003566429, 0.…#> $ probability_virginica <dbl> 0.001423170, 0.002082058, 0.001423170, 0.…#> $ probability_setosa <dbl> 0.9950104, 0.9943539, 0.9950104, 0.995010…
3. Broom
虽然Spark通过sparklyr对broom的支持已经开发了很长一段时间,但是这个版本标志着所有建模功能的完成。
movies <- data.frame(user = c(1, 2, 0, 1, 2, 0),item = c(1, 1, 1, 2, 2, 0),rating = c(3, 1, 2, 4, 5, 4))copy_to(sc, movies) %>%ml_als(rating ~ user + item) %>%augment()
# Source: spark<?> [?? x 4]user item rating .prediction<dbl> <dbl> <dbl> <dbl>1 2 2 5 4.862 1 2 4 3.983 0 0 4 3.884 2 1 1 1.085 0 1 2 2.006 1 1 3 2.80
4.TFRecords
sparktf是一个新的sparklyr扩展,允许在Spark中编写TensorFlow记录。 这可用于在使用Keras或TensorFlow在GPU实例中处理大量数据之前对其进行预处理。 sparktf现在可以在CRAN上使用,可以按如下方式安装:
install.packages("sparktf")您可以简单地在Spark中预处理数据,并使用spark_write_tf()将其写为TensorFlow记录:
library(sparktf)library(sparklyr)sc <- spark_connect(master = "local")copy_to(sc, iris) %>%ft_string_indexer_model("Species", "label",labels = c("setosa", "versicolor", "virginica")) %>%spark_write_tfrecord(path = "tfrecord")
详细内容请点击阅读原文进行学习!
往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
要么忙着活,要么忙着死↓

















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









