



考虑数据时间序列的移动用户上下文分析与估计
摘要
近年来,在客户行为分析等领域,对理解移动用户活动的需求日益增加。我们之前的研究表明,通过应用机器学习方法,利用手机的多种传感器数据和用户的生物信号,可以在一定程度上估计移动用户的上下文。本文提出通过考虑数据时间序列来分析和估计上下文,以提高准确率。在分析与估计过程中,使用来自两名受试者的数据,应用卷积神经网络(CNN)及多种机器学习方法,将数据分类为预先定义的八个和七个情境,并进行比较。结果表明,采用256窗口宽度的卷积神经网络分别在两名受试者上达到了97.6%和97.1%的最高宏F1分数。这表明,通过考虑数据时间序列,利用传感器数据和生物信号进行上下文分析与估计可以实现更高的准确性。
关键词 :上下文分析,上下文估计,移动用户,生物信号,传感器数据,机器学习,卷积神经网络
I. 引言
近年来,在客户行为分析等领域,对理解移动用户活动(人类活动识别(HAR)的一种看作情况)的需求不断增加。已有相关研究使用公开的数据集 [1] 对日常生活活动(ADL)进行分类,如坐下、行走和跑步等。对于室内和室外通信环境监测而言,除了HAR所需的运动状态外,还需估计特定用户的上下文,包括行为和周围环境。我们之前的研究[2]表明,通过利用来自手机的多种传感器数据和用户的生物信号,结合机器学习可在一定程度上实现移动用户上下文的估计。在人类活动识别中,考虑数据时间序列的卷积神经网络(CNN)已被用于实现优于传统方法的性能 [1,3]。因此,本文提出应用卷积神经网络(CNN)于移动用户上下文估计,以提高准确率。
移动用户的单一上下文可能会在一段时间内持续发生。因此,我们认为考虑数据时间序列对于深度学习特别重要。为了评估所提出的方案,使用不同窗口宽度Wn(其中n表示窗口宽度)对数据集进行分割,并采用卷积神经网络及其它机器学习方法进行分析。需要注意的是,在W1中未考虑时间序列。本文比较并讨论了不同Wn对分类准确率的影响。
II. 实验
数据通过两种设备收集:Polar H10 教 V800(心率传感器)和 Galaxy S9(智能手机)。表I 列出了这两种设备的数据及维度数。我们使用智能手机应用“Sensor Log”来收集智能手机的数据。
两名年龄分别为22岁和20岁的男性参与了实验,数据收集持续了7天。在实验期间,受试者按要求自由使用智能手机。受试者在移动时尽可能将智能手机握在手中,在不移动时则将其放在附近,与[2]中的方式相同。受试者将实时所处的情境手动输入并复选为9个类别:进食、学习、移动、睡眠、享受娱乐、与朋友聚会、呼吸、饮食和其他。我们在第三和第四节所述的分析与估计中将这些作为真实标签使用。在接下来的部分中,这两名受试者分别称为子集1和子集2。
表I. 设备、数据和预处理方法
| 设备 (维度数) | 采样频率 | 数据类型 (维度数) | 每 1秒 的预处理数据 |
|---|---|---|---|
| Polar H10 教 V800 心率传感器(1) | 130 Hz | RR间期(RRI)(1) | 平均RR间期 |
| 加速度(3) | |||
| 陀螺仪(3) | |||
| 大气压力(1) | 日内中位数 | ||
| Galaxy S9 智能手机 (14) | 1 Hz | 网络使用 小时 | 归一化数据 小时 发送与接收的数据量 |
| 经度(1) | |||
| 纬度(1) | |||
| 信号强度 (1) |
III. 数据分析与估计
A. 数据预处理
数据预处理方法列于表I中。在表格中,括号中的数字表示预处理后数据的维度数。
我们计算每秒的心率变异性HRV(RR间期),作为心率标准化的输入,与[2]中的方法相同。在预处理中,我们计算每秒的心率变异性HRV。对于大气压力,我们将每个实验日的每个测量值替换为该日的中位数。网络使用发送和接收的数据量,单位为小时。我们分别计算每秒发送与接收的数据量,以反映网络使用的归一化情况。加速度和陀螺仪可旁采样至1 Hz,以匹配所有数据。
最后,子集1和子集2的旁采样数据分别具有约150,000秒和240,000秒的15个维度。表II列出了各上下文的数据比例。随后,对数据进行与[2]中相同的方法进行Z-score归一化处理,并将其作为后续实验中的数据集。
表II. 各上下文数据的比率
| 进食 | 学习 | 移动 | 睡眠 | 享受娱乐 | 与朋友聚会 | 呼吸 | 饮食 | 其他 |
|---|---|---|---|---|---|---|---|---|
| 0.053 | 0.076 | 0.219 | 0.584 | 0.287 | 0.038 | 0.030 | 0.085 | 0.076 |
| 0.028 | 0.101 | 0.127 | 0.071 | 0.008 | 0 | 0.053 |
B. 卷积神经网络
我们使用滑动窗口对数据集进行分割,以准备输入到卷积神经网络[3]的数据。采用了五种不同的窗口宽度Wn(n为16、32、64、128、256),所有窗口宽度的滑动窗口重叠率为16。
因此,分割数据的不同采样率on因不同窗口宽度Wn而异,见表III所示。在训练过程中,窗口数据的真实标签由最频繁出现的情境确定,其中子集1使用8种情境(去除“其他”),子集2使用7种情境(去除“饮食”和“其他”)。

图1展示了卷积神经网络的整体结构,其中D为数据集的维度数。每一层中的矩形方框代表卷积核。“*”前的数字分别表示每层中的特征图数量和单个特征图的维度数。该卷积神经网络包含三个双通道卷积层(卷积层1至卷积层3)和四个全连接层(全连接层1至全连接层4)。所有卷积层的卷积核大小均为3,其中一个二维矩形区域内包含两个步长分别为1和2的卷积层。步长为2的卷积层3的输出可进一步传递到后续的全连接层1。每个全连接层中的数字对应其输出单元的数量。该网络还在每一层之间设有整流线性单元(ReLU)、归一化和dropout层。
最后,Fc4的输出被传递到softmax函数中,以生成类别概率分布。针对每个Wn设计了不同的CNN架构。在表III中使用了遵循[4]的架构命名表示法来列出所有参数,其中Cs(n)表示具有n个特征图和步长s的卷积层,F(n)表示具有n个神经元单元的全连接层。所有Cs(n)的特征图数量固定为128,因此所有CNN架构均具有相同的四个全连接层。数据集通过分层抽样方法以7比3的比例随机划分为训练数据和测试数据。此外,我们还在仅包含RRI的数据集上进行了不同的分析,以验证RRI在上下文估计中的有效性。
表III. 卷积神经网络架构用于每个窗口宽度
| Wn | On[%] | 架构 |
|---|---|---|
| 16 | 6.25 | C1(128) - C2(128) - C2(128) - F(1024) - F(512) - F(128) - F(8) |
| 32 | 12.5 | C1(128) - C2(128) - C1(128) - C2(128) - C2(128) - F(1024) - F(512) - F(128) - F(8) |
| 64 | 25 | C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C2(128) - F(1024) - F(512) - F(128) - F(8) |
| 128 | 50 | C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C2(128) - F(1024) - F(512) - F(128) - F(8) |
| 256 | 100 | C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C1(128) - C2(128) - C2(128) - F(1024) - F(512) - F(128) - F(8) |
C. 监督学习
我们使用三种监督学习方法进行比较:KNN(k-近邻)、RF(随机森林)和GBDT(梯度提升决策树),采用与CNN相同的Wn和On,再加上W1,其中输入特征为数据集,目标标签为八个或七个上下文。数据集被随机划分为训练数据和测试数据,划分方式与CNN中相同。我们将分割后的数据序列化作为输入提供给这些模型。所有参数(如KNN中针对Wn的k值)通过分层5折交叉验证的网格搜索方法进行优化。表IV列出了通过网格搜索获得的最佳参数。对于各模型的参数我们使用scikit-learn的默认参数。
表IV. 监督学习最佳参数
| 参数名称 | 16 | 32 | 64 | 128 | 256 | 16 | 32 | 64 | 128 | 256 |
|---|---|---|---|---|---|---|---|---|---|---|
| k值 (KNN) | 1000 | 1000 | 500 | 1000 | 500 | 500 | 100 | 1000 | 100 | 500 |
| 最大深度 (RF) | None | None | None | None | 15 | None | None | None | None | None |
| 学习率 (GBDT) | 0.14 | 0.11 | 0.12 | 0.15 | 0.14 | 0.11 | 0.20 | 0.16 | 0.10 | 0.16 |
| 估计器数量 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| 子采样 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 |
| max_features | auto | auto | auto | auto | auto | auto | auto | auto | auto | auto |
| ## IV. 结果与讨论 |
结果见表V和表VI所示,其中列出了准确率(ACC)、宏召回率(RECm)和宏F1分数(F1m)。每项指标的最佳结果以粗体标出。
在表V中,对于Wn < 64,随机森林的准确率最高。但对于W128和W256,卷积神经网络的准确率最高。所有情况下最高的准确率和宏F1分数均由CNN在W256时实现。
在表VI中,GBDT与W256实现了最高的准确率为96.94%,但CNN与W256的准确率为96.97%。然而,CNN与W256在所有方法中实现了最高的宏召回率和F1分数。因此,考虑数据时间序列有助于更准确地分类用户情境。

图2展示了卷积神经网络和随机森林在子集1上的结果,混淆矩阵对每行进行了归一化。在卷积神经网络中,“进食”、“睡眠”和“饮食”类别的准确率高于随机森林。
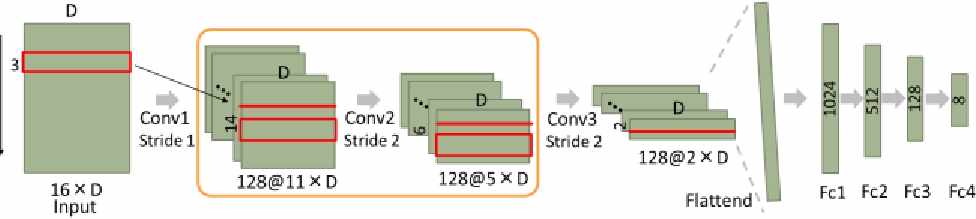
图3展示了卷积神经网络和梯度提升决策树在子集2上的结果,混淆矩阵对每行进行了归一化。在卷积神经网络中,“享受娱乐”和“呼吸”类别的准确率高于梯度提升决策树。在卷积神经网络中,通过在卷积核滑动窗口内对每个传感器数据单独进行卷积,来学习窗口内的时空模式。因此,相比于随机森林和梯度提升决策树,卷积神经网络更能有效学习时间序列中的局部模式。
根据随机森林(RF)和梯度提升决策树(GBDT)的重要特征排名,GPS和“发送的小时数”位于前两位最重要的特征之中,但RRI的排名相对较低。从图2可以看出,RF在区分“进食”和“睡眠”方面表现较差,而GBDT无法有效分类“呼吸”。这说明在用户上下文估计中,RF和GBDT的结果主要受GPS数据和网络使用的影响,而RRI的作用未能充分体现;相比之下,RRI的信息在卷积神经网络(CNN)中得到了更有效的利用。
表V. 卷积神经网络和监督学习(子集1)的准确性
| Wn | 方法 | 准确率 | RECm | F1m |
|---|---|---|---|---|
| 1 | KNN | 0.911 | 0.854 | 0.860 |
| RF | 0.966 | 0.924 | 0.937 | |
| GBDT | 0.966 | 0.929 | 0.939 | |
| 16 | KNN | 0.898 | 0.846 | 0.838 |
| RF | 0.968 | 0.932 | 0.941 | |
| GBDT | 0.960 | 0.912 | 0.924 | |
| 32 | KNN | 0.880 | 0.835 | 0.820 |
| RF | 0.973 | 0.938 | 0.948 | |
| GBDT | 0.970 | 0.932 | 0.943 | |
| 64 | CNN | 0.973 | 0.961 | 0.962 |
| KNN | 0.871 | 0.801 | — | |
| RF | 0.979 | 0.948 | 0.960 | |
| GBDT | 0.974 | 0.950 | 0.956 | |
| 128 | CNN | 0.981 | 0.977 | 0.972 |
| RF | 0.981 | 0.950 | 0.961 | |
| 256 | CNN | 0.987 | 0.981 | 0.976 |
| RF | 0.985 | 0.941 | 0.953 | |
| GBDT | 0.985 | 0.947 | 0.951 |
表VI. 卷积神经网络和监督学习(子集2)的准确性
| Wn | 方法 | 准确率 | RECm | F1m |
|---|---|---|---|---|
| 1 | KNN | 0.755 | — | — |
| RF | 0.979 | 0.924 | 0.937 | |
| GBDT | 0.985 | 0.947 | 0.951 | |
| 16 | KNN | 0.735 | — | — |
| RF | 0.984 | 0.955 | 0.957 | |
| GBDT | 0.983 | 0.968 | 0.950 | |
| 32 | KNN | — | — | — |
| RF | 0.984 | 0.941 | 0.953 | |
| GBDT | 0.989 | 0.971 | 0.971 | |
| 64 | CNN | 0.984 | 0.955 | 0.957 |
| RF | 0.985 | 0.927 | 0.930 | |
| GBDT | 0.982 | 0.922 | 0.932 | |
| 128 | CNN | 0.983 | 0.968 | 0.950 |
| RF | 0.989 | 0.948 | 0.960 | |
| 256 | CNN | 0.989 | 0.971 | 0.971 |
| RF | 0.989 | 0.948 | 0.960 | |
| GBDT | 0.969 | 0.905 | 0.693 |

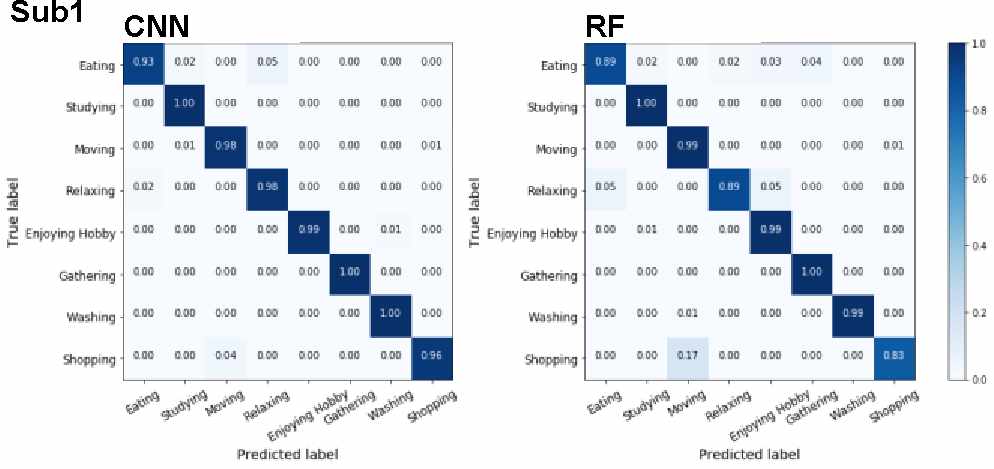
图4和图5展示了每位受试者在使用卷积神经网络(CNN)且窗口宽度为W256时,包含与不包含RRI的每种情境的召回率。对于“进食”和“睡眠”情境,如图4所示,包含RRI的CNN结果的召回率高于不含RRI的情况。类似地,如图5所示,“进食”和“享受娱乐”的召回率在包含RRI时得到提升。因此,可以认为RRI有助于提高分类性能。
根据上述结果,考虑数据时间序列的卷积神经网络在分类任务上优于三种监督学习方法。然而,仍需更多受试者的数据以进一步验证该结论。
V. 结论
在本文中,我们应用卷积神经网络、k-近邻、随机森林和梯度提升决策树,结合数据时间序列,利用包括生物信号在内的传感器数据,实现更准确的移动用户上下文估计。使用W256窗口宽度的卷积神经网络,每个受试者的宏F1分数最高分别达到97.6%和97.1%。结果表明,考虑数据时间序列有助于提高移动用户上下文估计的分类性能。在未来的工作中,我们计划使用自编码器来分析无需预先定义的上下文,并增加受试者数量以进一步验证结果。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









