




合规批量下载美国上市公司年报数据的一些经验和总结
引言
美国证券交易委员会(SEC)通过EDGAR系统公开了纳斯达克和纽约交易所上市公司的财务报告(如10-K年度报告、10-Q季度报告、8-K重大事件报告等),为财务分析提供了重要数据源。然而,手动获取和处理这些报告效率低下,自动化工具成为提升效率的关键。本文总结了一套使用Python脚本批量下载和处理SEC报告的技术经验,旨在为简单财务分析提供支持,分享开发过程中的挑战与解决方案。
数据获取流程概述
该自动化流程的目标是为财务分析提供标准化的数据,涉及以下步骤:
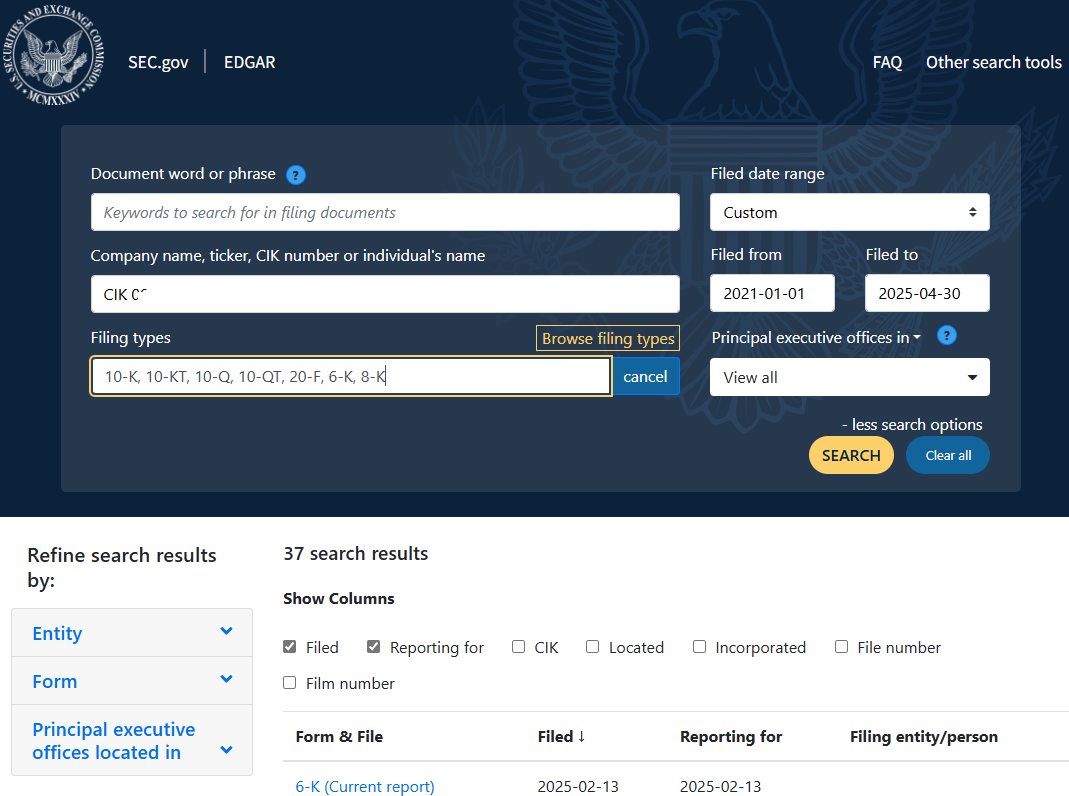
- 通过公司CIK代码查询SEC EDGAR系统,生成包含特定日期和报告类型的URL。
- 下载报告的HTML内容并保存到本地。
- 处理Excel文件,添加中文报告名称并补充文件位置信息。
- 使用多线程优化性能,确保几百条数据的处理效率。
使用的主要技术包括Python、Pandas(数据处理)、Selenium(网页抓取)、Requests(API请求)和ThreadPoolExecutor(多线程)。流程针对几百条数据的规模设计,5个线程足以应对I/O密集型任务。
技术流程详细步骤
步骤1:通过CIK代码查询SEC数据
流程从读取包含公司名称和CIK代码的文件(例如sec_company_name_cikcode.txt或company-255-world.xlsx)开始。脚本通过CIK代码拼接SEC EDGAR搜索URL,指定日期范围(2021-01-01至2025-04-30)和报告类型(如10-K、10-Q等)。使用Selenium访问这些URL,解析页面中的分页信息以确定结果总数(pgcount),并将URL和总数写入Excel文件的指定列。
挑战:最初尝试使用curl访问拼接的URL,但未获得预期结果。调查发现,SEC对自动化请求的User-Agent有严格要求,必须声明公司信息(例如ktkj/1.0 (contact@mycompany.com)),否则会被识别为“未声明的自动化工具”并受限。通过在Requests和Selenium中设置合规的User-Agent解决了问题。
步骤2:下载报告文件
在每个公司子目录中,脚本读取第一个Excel文件的dataSource列,提取URL并解析文件名。使用Selenium访问这些URL,获取页面HTML内容并保存到子目录的files文件夹中。为避免文件名冲突,脚本自动在重名文件后添加_1、_2等后缀。错误(如URL不可访问)被记录到_errlog.txt和_{lines-1}.txt文件中,确保问题可追溯。
步骤3:处理Excel文件
Excel文件处理包括以下操作:
- 标题翻译:根据预定义规则(例如
10-K替换为年度报告),使用正则表达式更新title列,保留原始后缀(如10-Qabc变为10-Q季度报告abc)。 - 内容补充
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









