




 本文详细解析了在使用MySQL进行数据批量插入时遇到的关键字字段问题及解决方案,同时分享了在MyBatis框架下实现批量更新时的常见错误与正确配置方法。
本文详细解析了在使用MySQL进行数据批量插入时遇到的关键字字段问题及解决方案,同时分享了在MyBatis框架下实现批量更新时的常见错误与正确配置方法。
一、数据库mysql 批量插入 时遇到的问题:
数据表的字段 一定不要是关键字(key,value等),否则你执行sql的时候一直报错,告诉你糟糕的sql语法,错误靠近###等
但是出于常理,我们肯定不会去想 是数据表的字段名出了问题,而是想sql语法,或者是值传的有问题。
但最后我还是发现了关键字的问题,因为我用排除法排除所有结果,剩下的那个就是真相。
因为首先我们确保sql的语法是正确的,那么错误就在数据上,首先将数据表字段的数据分为几类,比如字符串,int,和时间 ,然后逐个排除。
1、先将sql中只留字符串类型,然后执行,看是否报错,有错说明在这几个字符串中某些出了问题,在细分找;没问题的话就下一步
2、sql的插入条件只留int类型,然后执行,。。。。
3、sql 中只留时间data类型,
最后你就会发现,关键字的列会报错,然后把名字改成普通的,就运行通过了!
2、这是修改后我批量查询的sql:
<!-- 批量保存数据 -->
<insert id="saveEnvConfig" parameterType="arrayList">
<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT @@IDENTITY AS id
</selectKey>
insert into envconfig(version,createTime,editTime,createUser,editUser,resourceID,envResourceID,envKey,envValue)values
<foreach collection="list" item="item" index="index" separator=",">
(0,#{item.createTime},#{item.editTime},#{item.createUser},#{item.editUser},#{item.resourceID},#{item.envResourceID},#{item.envKey},#{item.envValue})
</foreach>
</insert>
3、批量查询出错了,不要惊慌,先试试插入单条数据,如果单条插入数据也出错,那么原因很有可能就是数据的问题。
之后就是排除法一一知道找错错误的那一列。
4、报错的sql:
insert into envconfig(version,createTime,editTime,createUser,editUser,resourceID,envResourceID,key,value) values
(0,#{createTime},#{editTime},#{createUser},#{editUser},#{resourceID},#{envResourceID},#{key},#{value})
5、报错内容:
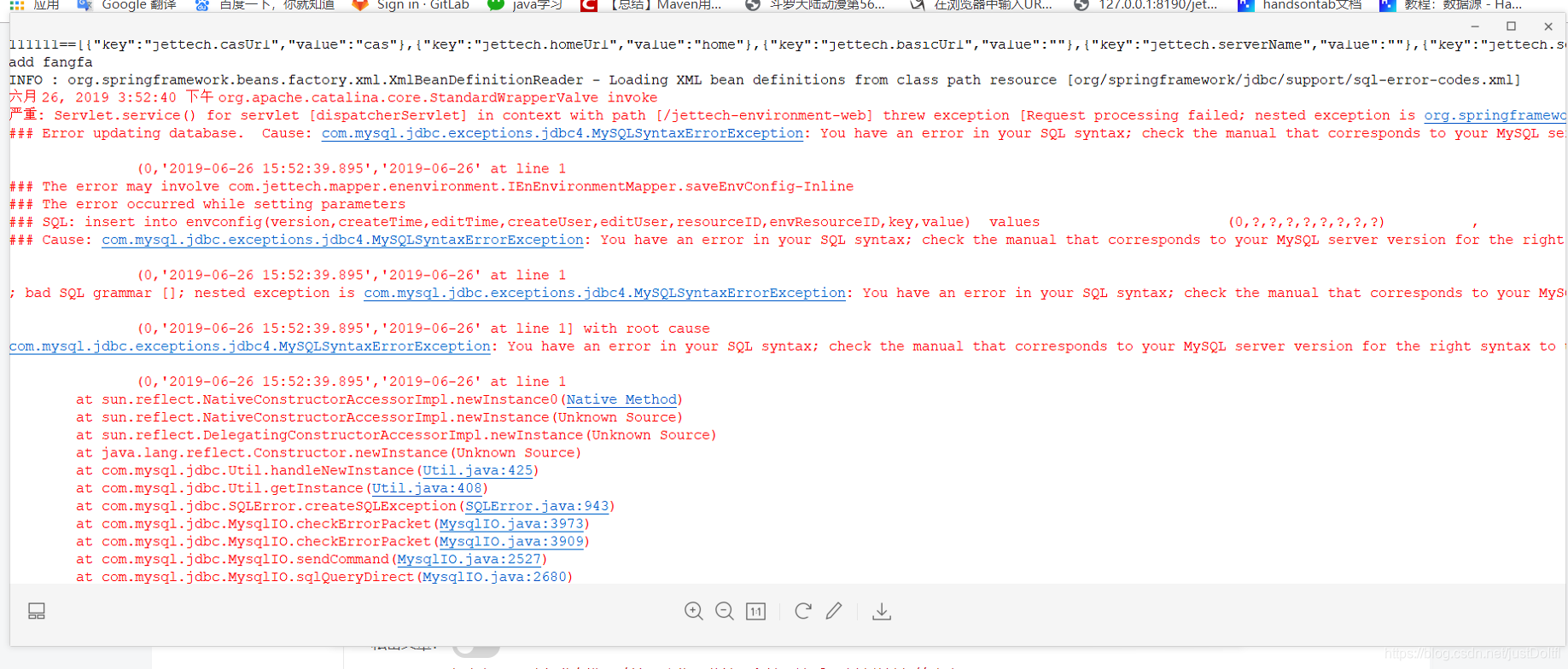
最后附上,调错一定要细心,粗心大意会浪费你很多时间,写到这里,着重感谢刘**对我热心的帮助。希望以后编程路上能永远充满激情,克服粗心,着急,手忙脚乱的坏习惯。
特别注意的情况:(批量更新不起作用)
二、mybatis实现批量更新,一直报错,说我的sql语句不对,然后我仔细检查了语句没问题,还是执行不了,运行报错。
原来,在连接数据库的url中要加入 ?allowMultiQueries=true 这段,而且要放在第一行。
url: jdbc:mysql://localhost:3306/crm?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8
username: root
password: root

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









