




目录
一、选择题(如果为计算题,写出简要的计算过程)
1、一个四位二进制补码的表示范围是(B)
A、0~15 B、-8~7 C、-7~7 D、-7~8
2、十进制数-48 用补码表示为(C)
A、10110000 B、11010000 C、11110000 D、11001111
-48原码为10110000,反码为11001111,加1后为11010000.
3、如果 X 为负数,由[x]补求[-x]补是将(D)
A、[x]补各值保持不变
B、[x]补符号位变反,其他各位不变
C、[x]补除符号位外,各位变反,末位加 1
D、[x]补连同符号位一起各位变反,末位加 1
4、机器数 80H 所表示的真值是-128,则该机器数为 (C)形式的表示。
A、原码 B、反码 C、补码 D、移码
5、在浮点数中,阶码、尾数的表示格式是(A)。
A、阶码定点整数,尾数定点小数 B、阶码定点整数,尾数定点整数
C、阶码定点小数,尾数定点整数 D、阶码定点小数,尾数定点小数
比如1234=1.234*10^3其中5就是阶码(整数),10是阶码的底,1.234是尾数(小数)
6、已知[x]补=10110111,[y]补=01001010,则[ x – y ]补的结果是( A)。
A、溢出 B、01101010 C、01001010 D、11001010
[ x – y ]补=[x]补+[-y]补,[-y]补=10110101+1=10110110,故[x-y]补=10110111+10110110=101101101,所以溢出。
7、某机字长 8 位,含一位数符,采用原码表示,则定点小数所能表示的非零最小正数为
( D)。
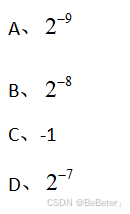
8位字符去除符号位,还剩7位,所以最小为2^(-7)
8、下列数中最小的数是(C)。
A、[10010101]原 B、[10010101]反 C、[10010101]补 D、[10010101]2
A为-21;B原码为11101010,为-106;C原码为11101011,为-107;D为+149;</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









