




 本文详细解析斯坦福大学《MachineLearning》课程中的反向传播算法核心公式,通过逐步推导帮助理解神经网络误差如何反向传播及各公式背后的含义。
本文详细解析斯坦福大学《MachineLearning》课程中的反向传播算法核心公式,通过逐步推导帮助理解神经网络误差如何反向传播及各公式背后的含义。
斯坦福大学《Machine Learning》第五周学习过程中,对反向传播算法的几个公式看得云里雾里的,这里做一个详细的推导和总结
- 公式一:
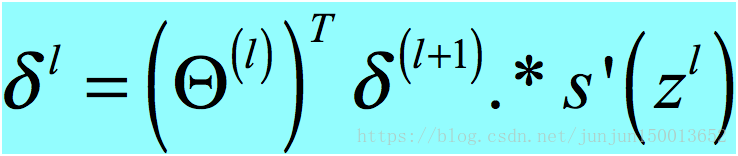
- 公式二:

- 公式三:
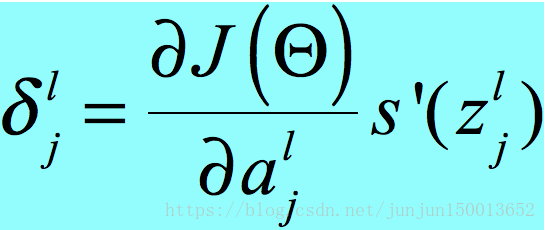
首先已知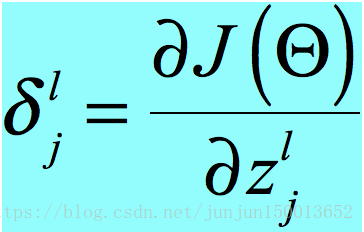 ,这个是我们定义的,不用推导,但是为什么要这样定义呢?
,这个是我们定义的,不用推导,但是为什么要这样定义呢?
我们给神经元的加权输入添加一点改变![]() ,这就导致了神经元的输出变成了
,这就导致了神经元的输出变成了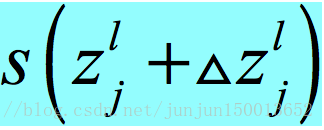 ,而不是之前的
,而不是之前的![]() 。这个改变在后续的网络层中传播,最终使全部代价改变了
。这个改变在后续的网络层中传播,最终使全部代价改变了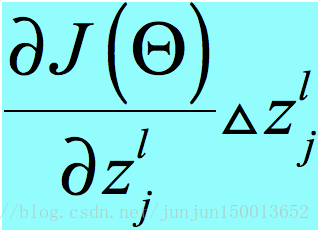 。因此,
。因此,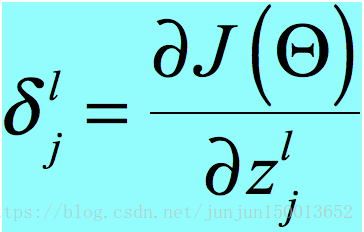 可以用来衡量神经元里的错误量.
可以用来衡量神经元里的错误量.
公式一证明:
要证明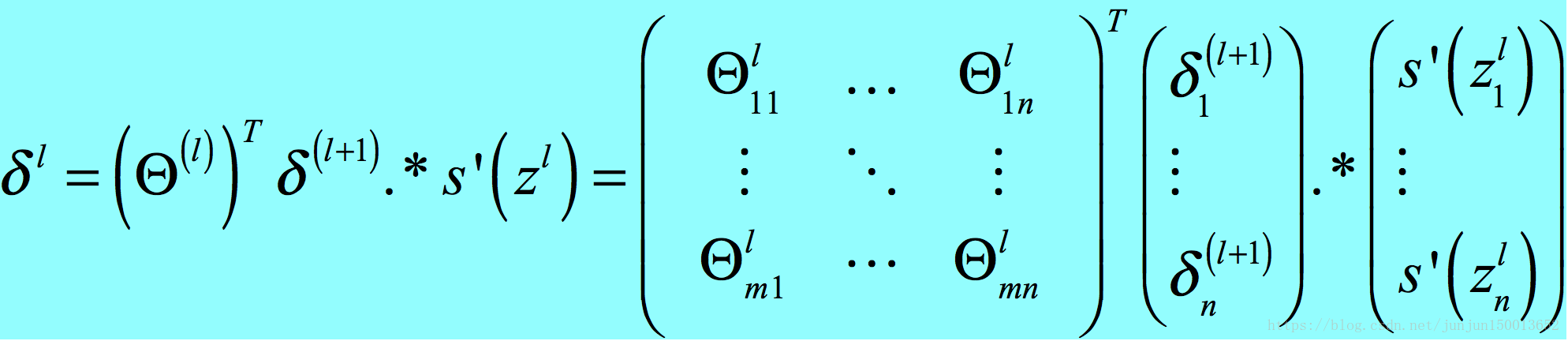
也就是证明 (1) 这个式子就是反向传播的核心式子,和我们求a的过程是一样的,只是方向相反。
(1) 这个式子就是反向传播的核心式子,和我们求a的过程是一样的,只是方向相反。
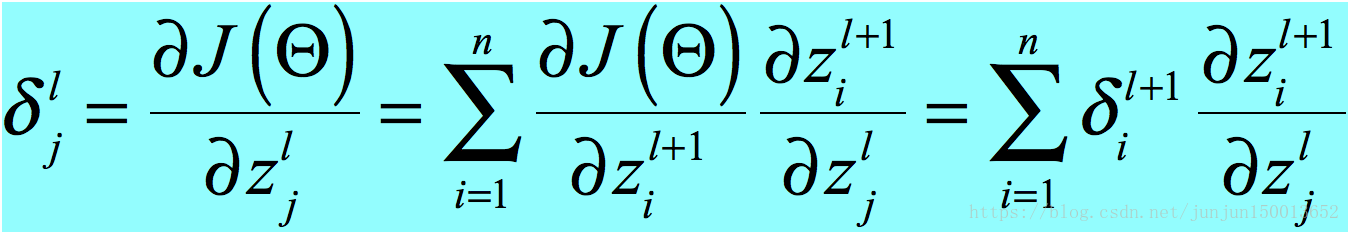 (2) 这里第二个等号后面的累加符号不太好理解,你可以这样想,(l+1)层的每个z都是z(l)j的函数,z(l)j的细小改变会影响到整个z(l+1)的变化,打个比方,M = u(x,y)+v(x,y),M对u或者v求偏导就类同J对l+1层的z求导,M对x或者y求偏导就类同J对z(l)j求导,这也就是求导公式的链式法则。
(2) 这里第二个等号后面的累加符号不太好理解,你可以这样想,(l+1)层的每个z都是z(l)j的函数,z(l)j的细小改变会影响到整个z(l+1)的变化,打个比方,M = u(x,y)+v(x,y),M对u或者v求偏导就类同J对l+1层的z求导,M对x或者y求偏导就类同J对z(l)j求导,这也就是求导公式的链式法则。
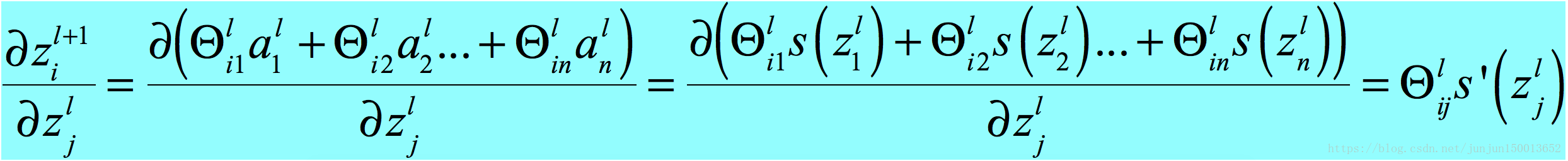 (3)
(3)
将(3)代入(2)即得到我们要证明的(1),证毕
公式二证明:
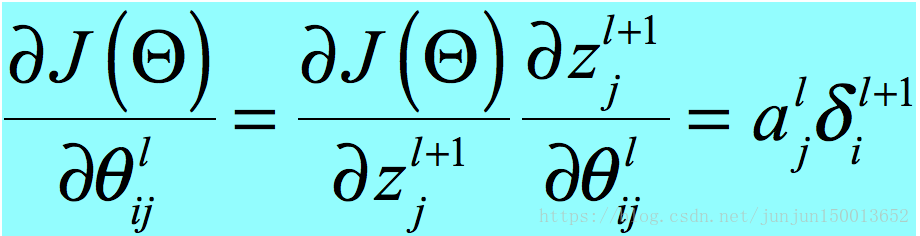
公式三证明:
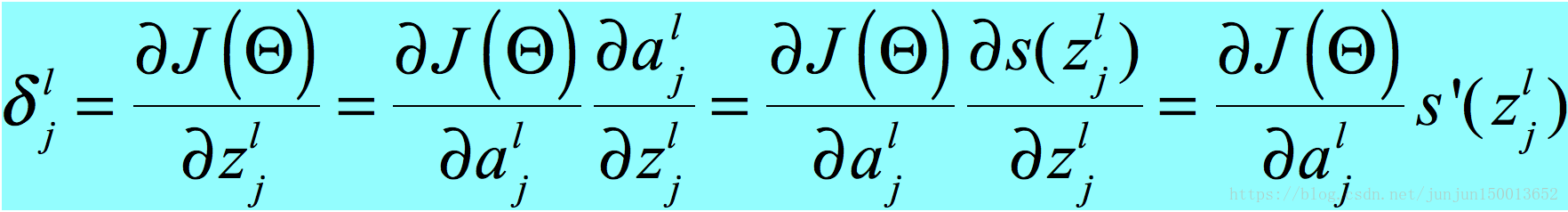

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









