



 这篇博客介绍了召回策略中item的协同过滤算法的实现,包括物品相似度计算、用户对item的推荐分数以及如何考虑用户活跃度和时间衰减。首先,通过计算用户重合度确定物品相似度,然后利用物品相似度和用户行为得分计算推荐分数。在升级版的算法中,引入了用户活跃度的贡献度降低和时间衰减惩罚。博客提供了Python代码实现,展示了从用户行为数据和物品信息中提取信息,并进行推荐结果计算的过程。
这篇博客介绍了召回策略中item的协同过滤算法的实现,包括物品相似度计算、用户对item的推荐分数以及如何考虑用户活跃度和时间衰减。首先,通过计算用户重合度确定物品相似度,然后利用物品相似度和用户行为得分计算推荐分数。在升级版的算法中,引入了用户活跃度的贡献度降低和时间衰减惩罚。博客提供了Python代码实现,展示了从用户行为数据和物品信息中提取信息,并进行推荐结果计算的过程。
召回策略-item的协同过滤
给用户推荐他之前喜欢的物品的相似物品
1)计算物品的相似度:喜欢两个物品的用户重合度越高,那么两个物品就越相似
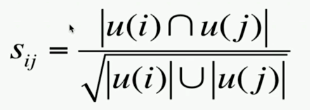
2)用户对item_j对推荐分数
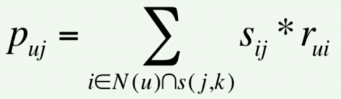
N(u) : user行为过的item 的总数
rui : user对物品i的行为得分(比如电影评分系统中用户对电影的评分-->归一化0~1间的一个值)
Sij : 物品 i 和 j 的相似得分
item i 是用户行为过的物品且是与item j 最相似的top k个 item (一般实战中选取50个)
公式升级
1.理论意义:活跃用户应该被降低在相似度中的贡献度
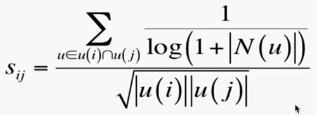
由于部分用户很活跃,对任何商品都有贡献值,所以要降低贡献度
2.理论意义:用户在不同时间对item的操作应给予时间衰减惩罚
随着时间的增长,用户对于item的操作应该进行衰减
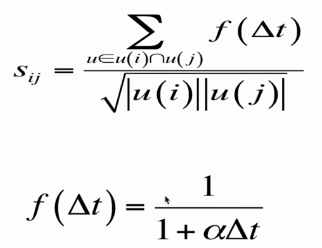
代码实现:抽取相关信息
# -*-coding:utf-8-*-
import os
import sys
#获取user-item数据{userid:[item1,item2],....}
def get_user_click(rating_file):
if not os.path.exists(rating_file):
return {}
fp = open(rating_file)
num = 0
user_click = {}
for line in fp:
if num == 0:
num += 1
continue
item = line.strip().split(',')
if len(item)<4:
continue
[userid, itemid, rating, timestamp]=item
if float(rating)<3.0:
continue
if userid not in user_click:
user_click[userid] = []
user_click[userid].append(itemid)
fp.close()
return user_click
#获取item-fea数据{itemid:[title, genres],....}
def get_item_info(item_file):
if not os.path.exists(item_file):
return {}
num = 0
item_info = {}
fp = open(item_file)
for line in fp:
if num == 0:
num += 1
continue
item = line.strip().split(',')
if len(item)<3:
continue
if len(item) == 3:
[itemid, title, genres] = item
elif len(item)>3:
itemid = item[0]
genres = item[-1]
title = ",".join(item[1:-1])
if itemid not in item_info:
item_info[itemid] = [title, genres]
fp.close()
return item_info
if __name__ == "__main__":
user_click = get_user_click("./data/ratings.csv")
# print(len(user_click))
# print(user_click['2'])
item_info = get_item_info("./data/movies.csv")
print(item_info["1"])
itemcf的实现,根据公式1进行的编码
# -*-coding:utf-8-*-
import os
import sys
import reader as reader
import math
import operator
def base_contribute_score():
return 1
def cal_item_sim(user_click):
"""
args: user_click:dict, key userid value [itemid1,itemid2]
return:dict, key:itemid_i, value dict, value_key itemid_j,value_value simscore
"""
co_appear = {}
item_user_click_time = {}
for user, itemlist in user_click.items():
for index_i in range(0, len(itemlist)):
itemid_i = itemlist[index_i]
item_user_click_time.setdefault(itemid_i, 0)
item_user_click_time[itemid_i] += 1
for index_j in range(index_i+1, len(itemlist)):
itemid_j = itemlist[index_j]
co_appear.setdefault(itemid_i, {})
co_appear[itemid_i].setdefault(itemid_j, 0)
co_appear[itemid_i][itemid_j] += base_contribute_score()
co_appear.setdefault(itemid_j,{})
co_appear[itemid_j].setdefault(itemid_i, 0)
co_appear[itemid_j][itemid_i] += base_contribute_score()
item_sim_score = {}
item_sim_score_sorted = {}
for itemid_i, relate_item in co_appear.items():
for itemid_j, co_time in relate_item.items():
sim_score = co_time/math.sqrt(item_user_click_time[itemid_i] * item_user_click_time[itemid_j])
item_sim_score.setdefault(itemid_i, {})
item_sim_score[itemid_i].setdefault(itemid_j, 0)
item_sim_score[itemid_i][itemid_j] = sim_score
for itemid in item_sim_score:
item_sim_score_sorted[itemid] = sorted(item_sim_score[itemid].items(), key=operator.itemgetter(1),reverse=True)
return item_sim_score_sorted
def cal_recom_result(sim_info, user_click):
# 召回的item
recent_click_num=3
topk = 5
recom_info = {}
for user in user_click:
click_list = user_click[user]
recom_info.setdefault(user, {})
for itemid in click_list[:recent_click_num]:
if itemid not in sim_info:
continue
for itemsimzuhe in sim_info[itemid][:topk]:
print(itemsimzuhe)
itemsimid = itemsimzuhe[0]
print(itemsimid)
itemsimscore = itemsimzuhe[1]
print(itemsimscore)
recom_info[user][itemsimid] = itemsimscore
return recom_info
def main_flow():
user_click = reader.get_user_click("./data/ratings.csv")
sim_info = cal_item_sim(user_click)
# print('*************',sim_info['1'])
recom_result = cal_recom_result(sim_info, user_click)
print(recom_result["3"])
if __name__ == "__main__":
main_flow()
修改后的升级函数
# -*-coding:utf-8-*-
import os
import sys
import reader as reader
import math
import operator
def base_contribute_score():
return 1
def update_one_contribute_score(user_total_click_num):
return 1/math.log10(1+user_total_click_num)
def cal_item_sim(user_click):
"""
args: user_click:dict, key userid value [itemid1,itemid2]
return:dict, key:itemid_i, value dict, value_key itemid_j,value_value simscore
"""
co_appear = {}
item_user_click_time = {}
for user, itemlist in user_click.items():
for index_i in range(0, len(itemlist)):
itemid_i = itemlist[index_i]
item_user_click_time.setdefault(itemid_i, 0)
item_user_click_time[itemid_i] += 1
for index_j in range(index_i+1, len(itemlist)):
itemid_j = itemlist[index_j]
co_appear.setdefault(itemid_i, {})
co_appear[itemid_i].setdefault(itemid_j, 0)
co_appear[itemid_i][itemid_j] += base_contribute_score()
co_appear.setdefault(itemid_j,{})
co_appear[itemid_j].setdefault(itemid_i, 0)
co_appear[itemid_j][itemid_i] += base_contribute_score()
item_sim_score = {}
item_sim_score_sorted = {}
for itemid_i, relate_item in co_appear.items():
for itemid_j, co_time in relate_item.items():
sim_score = co_time/math.sqrt(item_user_click_time[itemid_i] * item_user_click_time[itemid_j])
item_sim_score.setdefault(itemid_i, {})
item_sim_score[itemid_i].setdefault(itemid_j, 0)
item_sim_score[itemid_i][itemid_j] = sim_score
for itemid in item_sim_score:
item_sim_score_sorted[itemid] = sorted(item_sim_score[itemid].items(), key=operator.itemgetter(1),reverse=True)
return item_sim_score_sorted
def cal_recom_result(sim_info, user_click):
# 召回的item
recent_click_num=3
topk = 5
recom_info = {}
for user in user_click:
click_list = user_click[user]
recom_info.setdefault(user, {})
for itemid in click_list[:recent_click_num]:
if itemid not in sim_info:
continue
for itemsimzuhe in sim_info[itemid][:topk]:
print(itemsimzuhe)
itemsimid = itemsimzuhe[0]
print(itemsimid)
itemsimscore = itemsimzuhe[1]
print(itemsimscore)
recom_info[user][itemsimid] = itemsimscore
return recom_info
# 调试信息,查看推荐的结果和item之间是否相似很大
def debug_getsim(item_info, sim_info):
fixed_itemid = "3"
if fixed_itemid not in item_info:
print("invalid itemid")
return
[title_fix, generes_fix] = item_info[fixed_itemid]
for zuhe in sim_info[fixed_itemid][:5]:
itemid_sim = zuhe[0]
sim_score = zuhe[1]
if itemid_sim not in item_info:
continue
[title, genres] = item_info[itemid_sim]
print(title_fix+"\t"+generes_fix+"\tsim:"+title+'\t'+genres+"\t"+str(sim_score))
def main_flow():
user_click = reader.get_user_click("./data/ratings.csv")
item_info = reader.get_item_info("./data/movies.csv")
sim_info = cal_item_sim(user_click)
# print('*************',sim_info['1'])
debug_getsim(item_info, sim_info)
# recom_result = cal_recom_result(sim_info, user_click)
# print(recom_result["3"])
if __name__ == "__main__":
main_flow()
基于用户的协同过滤usercf
# -*-coding:utf-8-*-
import os
import sys
import reader as reader
import math
import operator
def base_contribution_score():
return 1
def transfer_user_click(user_click):
item_click_by_user = {}
for user in user_click:
item_list = user_click[user]
for itemid in item_list:
item_click_by_user.setdefault(itemid,[])
item_click_by_user[itemid].append(user)
return item_click_by_user
def cal_user_sim(item_click_by_user):
co_appear = {}
user_click_count = {}
for itemid, user_list in item_click_by_user.items():
for index_i in range(0, len(user_list)):
user_i = user_list[index_i]
user_click_count.setdefault(user_i, 0)
user_click_count[user_i] += 1
for index_j in range(index_i+1, len(user_list)):
user_j = user_list[index_j]
co_appear.setdefault(user_i, {})
co_appear[user_i].setdefault(user_j, 0)
co_appear[user_i][user_j] += base_contribution_score()
co_appear.setdefault(user_j, {})
co_appear[user_j].setdefault(user_i, 0)
co_appear[user_j][user_i] += base_contribution_score()
user_sim_info = {}
user_sim_info_sorted = {}
for user_i, relate_user in co_appear.items():
user_sim_info.setdefault(user_i, {})
for user_j, cotime in relate_user.items():
user_sim_info[user_i].setdefault(user_j, 0)
user_sim_info[user_i][user_j] = cotime/math.sqrt(user_click_count[user_i]*user_click_count[user_j])
for user in user_sim_info:
user_sim_info_sorted[user] = sorted(user_sim_info[user].items(), key=operator.itemgetter(1),reverse=True)
return user_sim_info_sorted
def cal_recom_result(user_click, user_sim):
recom_result = {}
topk_user = 3
item_num = 5
for user, item_list in user_click.items():
tmp_dict = {}
for itemid in item_list:
tmp_dict.setdefault(itemid, 1)
recom_result.setdefault(user, {})
for zuhe in user_sim[user][:topk_user]:
userid_j, sim_score = zuhe
if userid_j not in user_click:
continue
for itemid_j in user_click[userid_j][:item_num]:
recom_result[user].setdefault(itemid_j, sim_score)
return recom_result
def main_flow():
user_click = reader.get_user_click("./data/ratings.csv")
item_click_by_user = transfer_user_click(user_click)
user_sim = cal_user_sim(item_click_by_user)
recom_result = cal_recom_result(user_click, user_sim)
print(recom_result["1"])
if __name__ == "__main__":
main_flow()

















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









