




这几年来大数据非常的热门,到处都有大数据分析的演讲。 演讲内容通常是宣传各种大数据分析成功的案例。 但实际上大数据该怎么做呢? 大部份的讨论似乎都仅止于怎么搜集大量的数据, 然后用个工具(hadoop/spark)后就会马上变出商机和钱来。
大数据技术最重要的核心在于如何设计可以高性能处理大量数据的程式 (highly scalable programs.)
目前大数据相关工作可以粗分几类。有资料系统串接者, 设计大数据演算法实做的人,以及管理大型丛集 (cluster) 的工程师。 很多人对大数据工程师的理解还停留在资料系统串接者的程度, 以为只要将资料汇入某个神奇系统,就能将自己想要的结果生出来。 但实际上数据量变得很大时,我们往往需要自己客制化自己的资料系统,并且撰写特殊的演算法处理之。 以台湾和美国业界而言,第二种工程师是最稀少也需求量最高的。 这本书的目的就是由浅入深的介绍如何成为此类型的工程师。
不知道在学习大数据的读者们有没有想过,超级电脑的发明是1960年代的事, 为什么直到近年大数据才红起来?任何科技及技术都有其历史脉络, 学习一点相关历史会让自己在追逐新科技时更清楚自己要解决的问题的定位在哪边。
一、大数据是什么?
大数据,big data,《大数据》一书对大数据这么定义,大数据是指不能用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。
这句话至少传递两种信息:
1、大数据是海量的数据
2、大数据处理无捷径,对分析处理技术提出了更高的要求
二、大数据的处理流程
下图是数据处理流程:
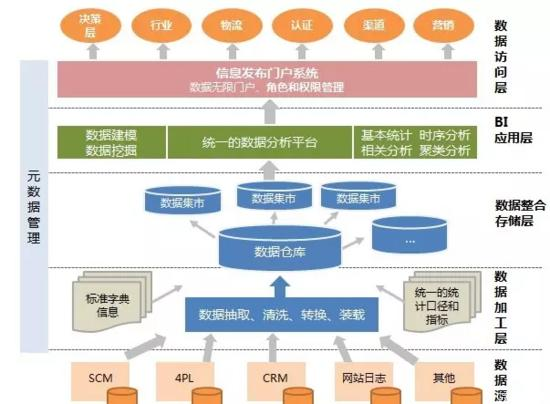
大数据是对海量数据进行存储、计算、统计、分析处理的一系列处理手段,处理的数据量通常是T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









