




上周听雨测试智谱开源的 CogVideoX5B 图生视频的时候还需要 16G 显存才能玩耍,没想开源社区这么快就把显存给打下来了,只需要 10G 显存就可以愉快的玩耍了,嗯,只需要一张 3060 12G 的入门显卡就可以了。
听雨之前介绍过 CogVideoX 的文生视频,作为一款开源的文生视频大模型,效果相当惊艳,尤其是后边推出的 CogVideoX5B 效果更佳,开源文生视频领域的 NO1。
当时就一直期待开源社区什么时候可以推出 CogVideoX 的图生视频,这不,他就在万众期待中走来了!
而且还没隔几天呢,CogVideoX5B 的 10G 量化版本就登场了!这不得好好来分享一波啊!
好了,话不多说,我们直接开整。
我们直接来上效果吧,具体的使用方式我们放在文末介绍。
可以看到质量还是很高的,还能看到晃动的头发以及起伏的肩膀。

动作幅度虽然很大,但是人物的一致性保持的非常不错。

可以看到宇航员头盔上的反光画面也是随着宇航员的动作在移动的。

这个运镜和一致性也是保持的相当不错呀,有种宁静致远的感觉。

这个看起来有点像延迟摄影的感觉有么有,而且地面上车辆经过的灯光也是相当真实有么有!

带有文字的图片也可以很好的保持一致性效果。

来个上帝之眼哈哈,这个眼球旁边的绒毛的浮动也是相当丝滑。

演示就到这里啦,剩下的就小伙伴们自己去发挥创作啦!
我们继续来讲讲具体如何操作!
需要用到的插件:GitHub - kijai/ComfyUI-CogVideoXWrapper
ComfyUI 管理器中还没有收录,我们直接通过 Git URL 进行下载就可以了,使用秋叶版的小伙伴也可以直接在绘世客户端版本管理进行安装。
插件同时支持文生视频和图生视频哦!
CogVideoX5B 的 10G 显存量化模型现在有两个版本,一个是官方原版的量化版本,一个是社区基于 CogVideoX 训练开发的 CogVideoX-Fun 的量化版本,这个社区版本支持自由分辨率哦!
听雨比较喜欢用 CogVideoX-Fun 版本,毕竟自由分辨率还是很香的,以下是 CogVideoX-Fun 版本的图生视频工作流。
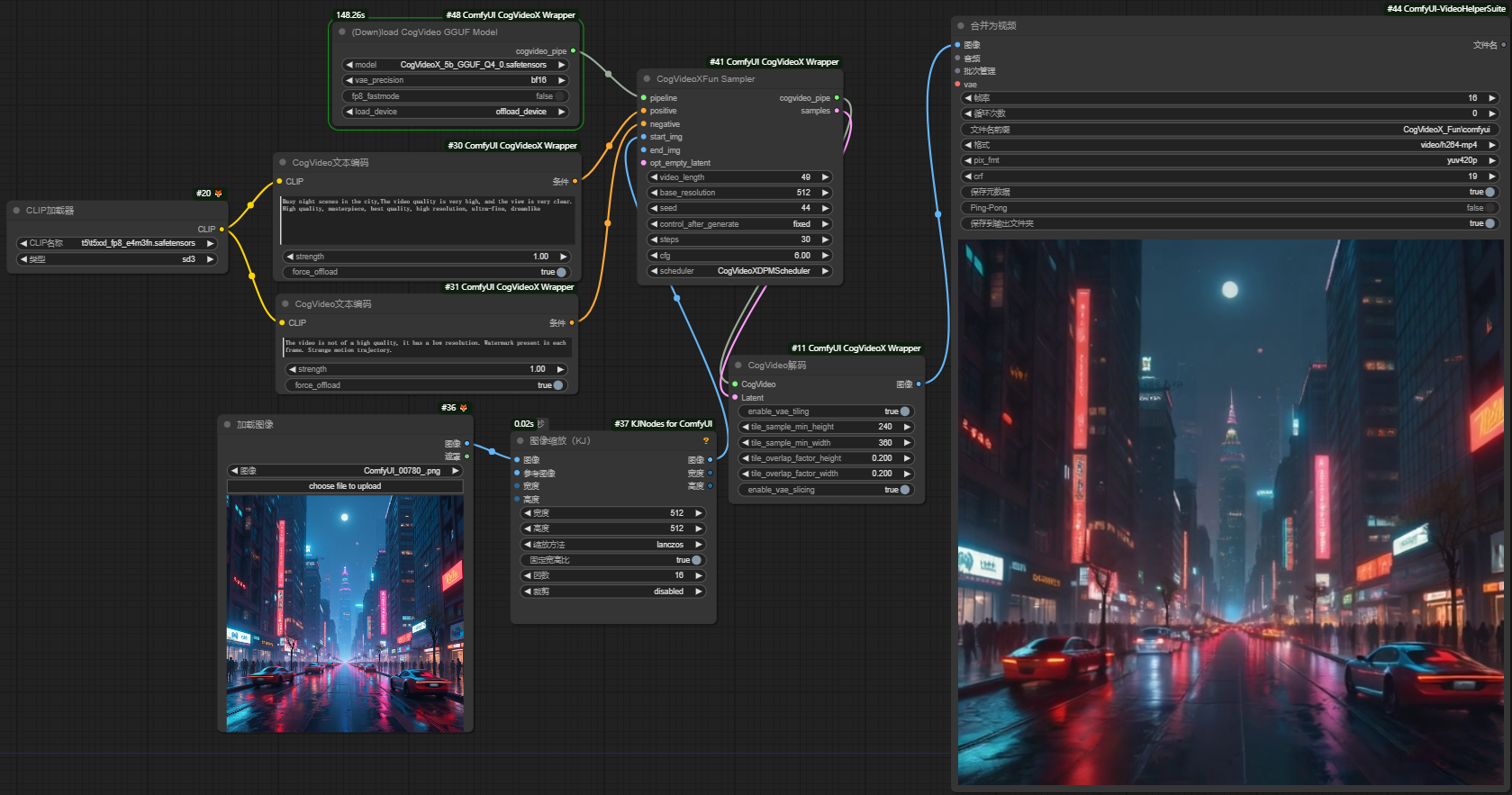
上传一张图片,然后填写动画的描述提示词就可以了,参数可以直接使用默认的即可,最终的视频会按照我们上传的图片尺寸来生成。
第一次运行工作流的时候会自动下载模型,我们也可以手动下载,模型以及工作流放在文末的网盘里了,需要的小伙伴自取。
我们稍微来讲下几个可能会用到的节点参数。
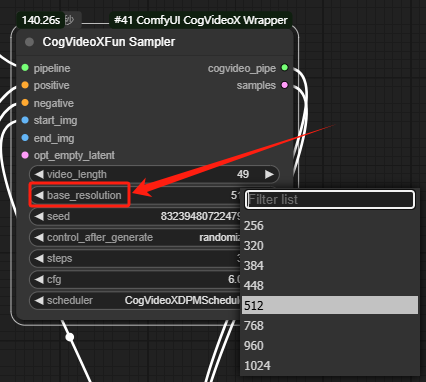
video_length:帧数,最大 49 帧,帧率设置为 8 的话,可以生成 6s 的视频。
base_resolution:最终生成视频的分辨率,分辨率越高所需要的显存越大,生成 512 分辨率的视频需要 10G 显存。
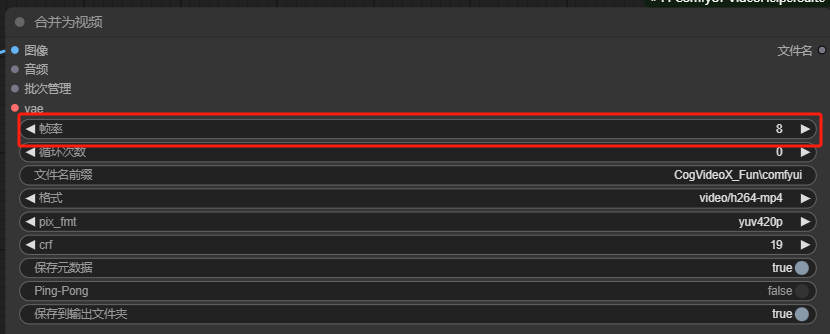
最后的输出节点可以设置帧率,帧数除以帧率就是我们最终视频生成的时长了。其他参数就没啥好讲的了。
整体测试下来,虽然有时候视频不太稳定,但是多抽几次总是可以出来很棒的效果,作为一个开源的可以在消费级显卡上运行的视频大模型来说,已经相当不错了。
而且社区也一直在对模型更新迭代,未来视频效果只会越来越好,让我们再期待一下吧!
好了,今天的分享就到这里了,感兴趣的小伙伴快去试试吧!
网盘链接:模型以及工作流


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









