




在现代多核处理器架构中,并发编程就像是在一个看不见的战场上指挥千军万马。每个CPU核心都拥有自己的“前线指挥部”(缓存),而主内存则是“总指挥部”。当多个核心同时执行任务时,如何确保它们看到的数据是一致的?这就引出了我们今天要深入探讨的主题——内存屏障。
想象一下交通指挥中的场景:在没有交通信号灯的路口,车辆各行其道,很容易发生碰撞。内存屏障就如同这个路口的交通警察,确保数据“车辆”按照正确的顺序通过,避免“交通事故”——即数据不一致的问题。
为什么需要内存屏障
现代计算机的内存层次结构
现代计算机系统为了弥补CPU与内存之间的速度差距,设计了复杂的内存层次结构:
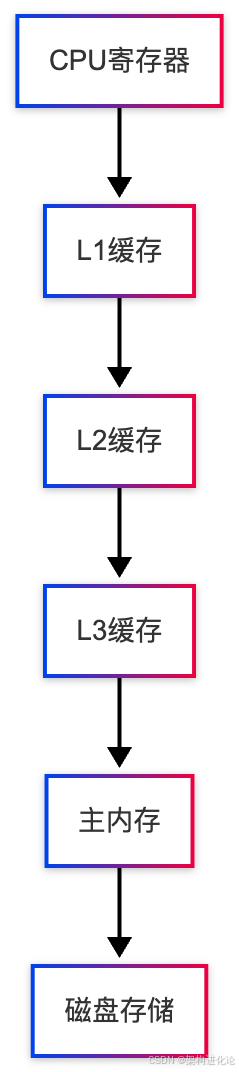
在这个层次结构中,越靠近CPU的存储速度越快,但容量越小。多核处理器中,每个核心通常有自己独享的L1和L2缓存,而L3缓存则由所有核心共享。
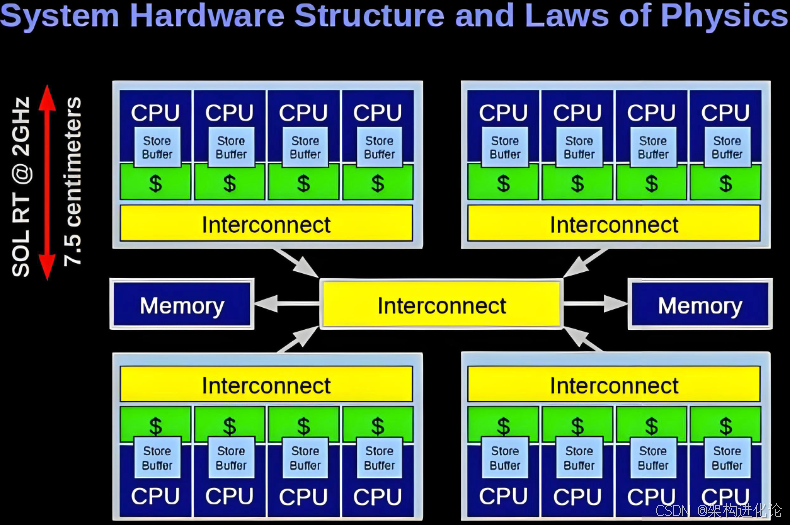
内存一致性问题
由于缓存的存在,同一个数据可能在多个缓存中有多个副本。当某个核心修改了自己缓存中的数据时,其他核心的缓存副本就变成了过时的数据,这就是内存一致性问题。
现实案例:想象一个团队协作编辑文档的场景。如果每个成员都在自己的本地副本上编辑,而没有及时同步到主文档,最终就会出现版本冲突和数据不一致。
指令重排序的挑战
为了提高性能,编译器和处理器都会对指令进行重排序优化:
// 示例1:可能被重排序的代码
public class ReorderingExample {
private int x = 0;
private int y = 0;
private boolean ready = false;
// 线程1执行
public void writer() {
x = 1; // 语句1
y = 2; // 语句2
ready = true; // 语句3
}
// 线程2执行
public void reader() {
if (ready) { // 语句4
System.out.println("x=" + x + ", y=" + y); // 语句5
}
}
}
在这个例子中,由于指令重排序,线程1可能先执行语句3,然后线程2看到ready=true,但此时x和y可能还没有被赋值,导致输出意外的结果。
Java内存模型(JMM)基础
JMM的抽象
Java内存模型定义了线程如何与内存交互,以及线程之间如何通过内存进行通信。JMM的主要目标是屏蔽各种硬件和操作系统的内存访问差异,实现Java程序在各种平台上的内存访问一致性。
happens-before关系
happens-before是JMM的核心概念,它定义了操作之间的偏序关系,确保如果一个操作happens-before另一个操作,那么第一个操作的结果对第二个操作可见。
// 示例2:happens-before关系示例
public class HappensBeforeExample {
private volatile boolean flag = false;
private int data = 0;
public void write() {
data = 42; // 操作1
flag = true; // 操作2 - 由于volatile,操作1 happens-before 操作2
}
public void read() {
if (flag) { // 操作3 - 由于volatile,操作2 happens-before 操作3
System.out.println(data); // 操作4 - 可以安全地读取42
}
}
}
内存屏障在JMM中的角色
内存屏障是实现happens-before关系的底层机制。它在指令序列中插入特殊的屏障指令,限制指令的重排序,并确保内存可见性。
Java中的内存屏障类型
硬件层面的内存屏障
在硬件层面,内存屏障主要分为四种类型:
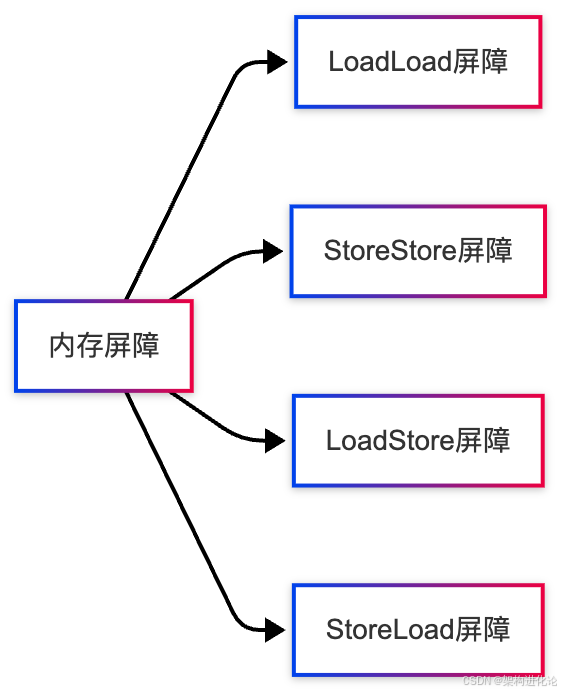
LoadLoad屏障
确保Load1的数据装载操作在Load2及后续装载操作之前完成。
现实案例:就像在超市排队结账,必须等前面的人装完商品,你才能开始装自己的商品。
StoreStore屏障
确保Store1的数据存储操作及其结果对其他处理器可见在Store2及后续存储操作之前。
现实案例:如同快递员送快递,必须确保第一个包裹已经妥投并记录,才能开始处理第二个包裹的投递。
LoadStore屏障
确保Load1的数据装载操作在Store2及后续存储操作之前完成。
StoreLoad屏障
确保Store1的数据存储操作及其结果对其他处理器可见在Load2及后续装载操作之前。这是最重量级的屏障,具有其他三种屏障的效果。
Java语言中的内存屏障
在Java中,我们不需要直接使用硬件内存屏障,而是通过语言级别的关键字和API来间接使用:
volatile关键字
// 示例3:volatile的内存屏障语义
public class VolatileBarrierExample {
private volatile int counter = 0;
private int ordinaryVar = 0;
public void increment() {
ordinaryVar = 1; // 普通写
// StoreStore屏障 - 确保ordinaryVar=1对其它线程可见在counter写入之前
counter = counter + 1; // volatile写
// StoreLoad屏障 - 确保counter的写入立即对所有线程可见
}
public void read() {
int local = counter; // volatile读
// LoadLoad屏障 + LoadStore屏障 - 确保counter读取后,后续操作不会重排序到前面
System.out.println(ordinaryVar); // 可能看到0或1,因为ordinaryVar不是volatile
}
}
volatile变量在写操作前后插入StoreStore屏障和StoreLoad屏障,在读操作后插入LoadLoad屏障和LoadStore屏障。
synchronized关键字
// 示例4:synchronized的内存屏障语义
public class SynchronizedBarrierExample {
private int sharedData = 0;
private final Object lock = new Object();
public void updateData() {
// 进入同步块 - 相当于获取锁
// 内存屏障:清空工作内存,从主内存重新加载变量
synchronized(lock) {
sharedData++;
// 内存屏障:确保共享变量的修改刷新到主内存
}
// 退出同步块 - 相当于释放锁
// 内存屏障:确保所有修改对后续获取该锁的线程可见
}
public int readData() {
synchronized(lock) {
return sharedData;
}
}
}
final字段
// 示例5:final字段的内存语义
public class FinalFieldExample {
private final int finalField;
private int ordinaryField;
public FinalFieldExample(int value) {
this.ordinaryField = value;
// StoreStore屏障 - 确保ordinaryField的写入在finalField之前对其它线程可见
this.finalField = value;
// 构造函数返回前的StoreStore屏障 - 确保final字段的写入在构造函数完成前对所有线程可见
}
public void reader() {
int local = finalField; // 可以安全地读取正确初始化的值
// ordinaryField可能看到默认值0或构造函数设置的值,但finalField保证看到构造函数设置的值
}
}
Java内存屏障的演进与创新设计
传统内存屏障的局限性
传统的硬内存屏障(如x86的mfence、lfence、sfence)虽然功能强大,但存在性能开销大的问题。特别是在StoreLoad屏障的情况下,可能导致处理器流水线停滞。
Java 5:JSR-133内存模型修订
Java 5对内存模型进行了重大修订,解决了原有模型中的缺陷,明确了volatile和final的内存语义。
增强的volatile语义
// 示例6:Java 5增强的volatile语义
public class EnhancedVolatile {
private volatile boolean initialized = false;
private Config config;
public void init() {
config = loadConfig(); // 非volatile写
// StoreStore屏障
initialized = true; // volatile写
// StoreLoad屏障
}
public void use() {
if (initialized) { // volatile读
// LoadLoad屏障 + LoadStore屏障
config.doWork(); // 安全使用,保证看到完全初始化的config
}
}
private Config loadConfig() {
// 模拟耗时的配置加载
return new Config();
}
}
Java 8:StampedLock与乐观读
Java 8引入了StampedLock,提供了乐观读机制,在某些场景下可以减少内存屏障的使用。
// 示例7:StampedLock的乐观读与内存屏障
public class StampedLockExample {
private final StampedLock lock = new StampedLock();
private double x, y;
public void move(double deltaX, double deltaY) {
long stamp = lock.writeLock(); // 获取写锁,插入完整内存屏障
try {
x += deltaX;
y += deltaY;
} finally {
lock.unlockWrite(stamp); // 释放写锁,插入完整内存屏障
}
}
public double distanceFromOrigin() {
// 尝试乐观读 - 不获取锁,没有内存屏障
long stamp = lock.tryOptimisticRead();
double currentX = x, currentY = y;
// 验证乐观读期间没有写操作发生
// 这里需要LoadLoad屏障,确保验证在读取x,y之后
if (!lock.validate(stamp)) {
// 如果验证失败,升级为悲观读锁
stamp = lock.readLock(); // 获取读锁,插入内存屏障
try {
currentX = x;
currentY = y;
} finally {
lock.unlockRead(stamp); // 释放读锁,插入内存屏障
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}
Java 9:VarHandle的精细控制
Java 9引入了VarHandle,提供了比反射更高效、更精细的内存访问控制,包括各种内存排序模式。
// 示例8:VarHandle的精细内存控制
public class VarHandleExample {
private int plainValue;
private volatile int volatileValue;
private static final VarHandle PLAIN_VALUE_HANDLE;
private static final VarHandle VOLATILE_VALUE_HANDLE;
static {
try {
MethodHandles.Lookup lookup = MethodHandles.lookup();
PLAIN_VALUE_HANDLE = lookup.findVarHandle(
VarHandleExample.class, "plainValue", int.class);
VOLATILE_VALUE_HANDLE = lookup.findVarHandle(
VarHandleExample.class, "volatileValue", int.class);
} catch (Exception e) {
throw new Error(e);
}
}
public void atomicOperations() {
// plainValue的原子操作 - 使用放松的内存排序
PLAIN_VALUE_HANDLE.getAndAdd(this, 1); // 放松内存排序
// volatileValue的原子操作 - 使用volatile内存排序
VOLATILE_VALUE_HANDLE.getAndAdd(this, 1); // volatile内存排序
// 使用精确控制的内存排序
VOLATILE_VALUE_HANDLE.getAndAddAcquire(this, 1); // 获取语义
VOLATILE_VALUE_HANDLE.getAndAddRelease(this, 1); // 释放语义
}
public void memoryOrderingControl() {
// 放松排序 - 无内存屏障,只保证原子性
int relaxed = (int) VOLATILE_VALUE_HANDLE.getOpaque(this);
// 获取语义 - 保证该读操作之后的读写不会重排序到前面
int acquire = (int) VOLATILE_VALUE_HANDLE.getAcquire(this);
// 释放语义 - 保证该写操作之前的读写不会重排序到后面
VOLATILE_VALUE_HANDLE.setRelease(this, 42);
}
}
创新设计:基于使用模式的自适应内存屏障
现代JVM实现了基于使用模式的自适应内存屏障优化:
// 示例9:JVM可能优化的场景
public class AdaptiveBarrierOptimization {
private volatile int hotspotCounter = 0;
private final ReentrantLock lock = new ReentrantLock();
// 场景1:单线程频繁访问的volatile - JVM可能优化掉部分屏障
public void singleThreadedIncrement() {
// 如果JVM检测到始终在单线程环境中访问,
// 可能优化掉不必要的内存屏障
for (int i = 0; i < 1000; i++) {
hotspotCounter++; // 在单线程中,volatile的部分语义可能被放松
}
}
// 场景2:锁粗化 - 合并多个同步块的屏障
public void lockCoarsening() {
// 未优化的版本 - 多个内存屏障
synchronized(this) { operation1(); }
synchronized(this) { operation2(); }
synchronized(this) { operation3(); }
// JVM可能优化为 - 单个内存屏障
synchronized(this) {
operation1();
operation2();
operation3();
}
}
// 场景3:逃逸分析 - 消除不必要的同步
public void escapeAnalysis() {
Object localObject = new Object();
// 如果localObject没有逃逸出方法,JVM可能消除这个同步块
synchronized(localObject) {
// 一些操作
}
}
}
内存屏障在并发容器中的应用
ConcurrentHashMap的内存屏障设计
// 示例10:ConcurrentHashMap中的内存屏障应用
public class ConcurrentHashMapBarriers {
// 简化的Node类,展示内存屏障应用
static class Node<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
}
// 读操作 - 使用volatile读语义
public V get(Node<K,V>[] tab, int hash, K key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 读取table引用 - 需要内存屏障确保看到最新值
tab = table;
if (tab != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & hash)) != null) {
// 使用volatile语义读取节点
if ((eh = e.hash) == hash) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val; // volatile读
}
// 遍历链表 - 每次读取next都需要内存屏障
while ((e = e.next) != null) {
if (e.hash == hash &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val; // volatile读
}
}
return null;
}
// 使用Unsafe实现原子操作,包含精确的内存屏障控制
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// 具有volatile读语义的数组访问
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
// CAS操作包含完整的内存屏障
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
}
CopyOnWriteArrayList的写时复制屏障
// 示例11:CopyOnWriteArrayList的内存屏障设计
public class CopyOnWriteBarrierExample {
private volatile Object[] array;
public boolean add(Object element) {
synchronized(this) {
Object[] elements = getArray();
int len = elements.length;
// 创建新数组 - 普通写操作
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = element;
// StoreStore屏障 - 确保新数组完全初始化
// 然后volatile写 - 包含StoreLoad屏障
setArray(newElements);
return true;
}
}
public Object get(int index) {
// volatile读 - 包含LoadLoad屏障
Object[] elements = getArray();
return elements[index]; // 普通读 - 但在volatile读之后,看到一致的数据
}
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
}
内存屏障性能优化实践
减少不必要的内存屏障
// 示例12:减少不必要内存屏障的优化技巧
public class BarrierReductionOptimization {
private volatile int primaryIndicator;
private int secondaryData1;
private int secondaryData2;
private int secondaryData3;
// 不优化的版本 - 每个写操作都使用volatile
public void unoptimizedUpdate(int a, int b, int c) {
secondaryData1 = a;
secondaryData2 = b;
secondaryData3 = c;
primaryIndicator++; // volatile写 - 完整内存屏障
}
// 优化的版本 - 减少volatile写操作
public void optimizedUpdate(int a, int b, int c) {
// 批量更新非volatile字段
secondaryData1 = a;
secondaryData2 = b;
secondaryData3 = c;
// 只在必要时插入内存屏障
if (needVisibility()) {
// StoreStore屏障确保非volatile写入在volatile写入前对其他线程可见
primaryIndicator++; // volatile写
}
}
// 使用线程局部变量避免共享
public void threadLocalOptimization() {
ThreadLocalRandom random = ThreadLocalRandom.current();
// 使用线程局部变量,不需要内存屏障
int localData = random.nextInt();
processLocally(localData);
// 只有最终结果需要同步
synchronized(this) {
updateSharedState(localData);
}
}
private boolean needVisibility() {
// 根据业务逻辑决定是否需要立即可见性
return true;
}
}
基于字段分组的内存屏障优化
// 示例13:字段分组减少内存屏障
public class FieldGroupingOptimization {
// 将需要一起更新的字段分组
private static class DataGroup {
int field1;
int field2;
int field3;
}
// 使用volatile引用确保整个组的可见性
private volatile DataGroup currentGroup = new DataGroup();
public void updateGroup(int a, int b, int c) {
// 创建新对象,避免修改过程中的不一致状态
DataGroup newGroup = new DataGroup();
newGroup.field1 = a;
newGroup.field2 = b;
newGroup.field3 = c;
// 单个volatile写确保整个组的原子发布
// StoreStore屏障确保新组完全初始化
currentGroup = newGroup; // volatile写
}
public void readConsistentGroup() {
// 单个volatile读获取一致的数据组
DataGroup group = currentGroup; // volatile读
process(group.field1, group.field2, group.field3);
}
}
未来展望与创新趋势
硬件内存模型的发展
新一代的硬件架构正在提供更精细的内存排序控制:
-
ARMv8的弱内存模型需要更多显式屏障
-
RISC-V提供可选的强/弱内存模型
-
异构计算架构需要针对不同处理单元的内存屏障
语言和运行时层面的创新
项目Loom与轻量级内存屏障
// 示例14:虚拟线程与内存屏障的潜在优化
public class VirtualThreadBarrier {
// 在虚拟线程场景下,JVM可能优化线程局部的内存屏障
public void virtualThreadFriendlyOperation() {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 10000; i++) {
executor.submit(() -> {
// 虚拟线程可能允许更轻量级的内存屏障
// 因为调度在用户态,JVM有更多优化机会
performThreadLocalWork();
});
}
}
}
}
值类型与内存屏障优化
// 示例15:值类型(Project Valhalla)可能的内存屏障优化
public class ValueTypeBarrierOptimization {
// 值类型的不可变性可能减少内存屏障需求
public static inline class Point {
final int x;
final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
private volatile Point currentLocation;
public void updateLocation(int x, int y) {
// 值类型的原子更新可能使用更轻量的屏障
Point newPoint = new Point(x, y);
// 由于值类型的不可变性,可能优化发布语义
currentLocation = newPoint;
}
}
结论
Java内存屏障作为并发编程的隐形守护者,在现代多核处理器架构中扮演着至关重要的角色。从最初的简单volatile语义,到如今精细化的内存排序控制,Java内存屏障的设计不断演进,在保证正确性的同时追求极致的性能。
通过本文的分析,我们可以看到:
-
内存屏障是Java内存模型的实现基石,它确保了happens-before关系的实现
-
Java提供了多层次的内存屏障抽象,从语言关键字到底层API,满足不同场景的需求
-
现代JVM实现了智能的屏障优化,基于使用模式自适应地调整屏障策略
-
未来发展趋势是更精细的控制和更智能的优化
作为架构师,深入理解内存屏障的工作原理和优化策略,对于设计高性能、高并发的系统至关重要。正确使用内存屏障,既能避免诡异的并发bug,又能在保证正确性的前提下最大化性能。
在并发编程的这个“看不见的战场”上,内存屏障就是我们最可靠的“交通警察”,确保数据的“车辆”安全、有序地通行,让我们的系统在高速运行中保持稳定和一致。



















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











