







一场关于“记忆”的技术进化
在大型语言模型(LLM)推理过程中,有一个看似矛盾的现象:当模型逐字生成文本时,它需要不断重复处理已经生成的文本。这就像每次说新单词时都要把之前说过的话全部复述一遍——这种低效性正是KV Cache技术要解决的核心问题。
以Llama-2 70B模型为例,在A100 GPU上生成1024个token时:
- 无KV Cache:耗时约12.3秒,显存占用98GB
- 启用KV Cache:耗时降至4.7秒,显存占用仅增加15GB
本文将深入剖析这项关键技术背后的设计哲学与工程实现。
传统Transformer的注意力瓶颈
原始Attention的计算困境
标准Transformer(扩展阅读:Transformer 是未来的技术吗?-优快云博客、初探 Transformer-优快云博客)的自注意力机制在推理时存在严重的计算冗余。对于序列位置,需要计算:
每次生成新token时,都需要重新计算整个历史序列的注意力矩阵,导致时间复杂度呈平方级增长(扩展阅读:Transformer完整计算案例:从输入到输出的逐步详解-优快云博客、从Self-Attention到Cross-Attention:Llama架构的深度技术解析与演进路径-优快云博客、Transformer架构逐层深度解析:从输入到输出的完整计算过程-优快云博客、来聊聊Q、K、V的计算-优快云博客)。
现实类比:重复计算的低效性
想象一位翻译官的工作场景:
-
无优化方案:每次翻译新句子时,都要把之前所有对话重新听写一遍
-
理想方案:只需记录之前对话的关键要点(Key-Value),新翻译只需关注新增内容
这正是KV Cache要解决的痛点。
KV Cache的架构设计原理
核心机制图解

数学形式化表达
对于第 个解码步:
Llama的特殊优化
旋转位置编码(RoPE)兼容性
def apply_rotary_pos_emb(q, k, pos_ids):
# q/k shape: [bsz, seq_len, heads, dim]
sin, cos = get_sin_cos(pos_ids) # 预计算三角函数
q_rot = q * cos + rotate(q) * sin # 旋转操作
k_rot = k * cos + rotate(k) * sin
return q_rot, k_rot # 位置信息已编码进KV Cache分组查询注意力(GQA)
扩展阅读:MTP、MoE还是 GRPO 带来了 DeepSeek 的一夜爆火?-优快云博客
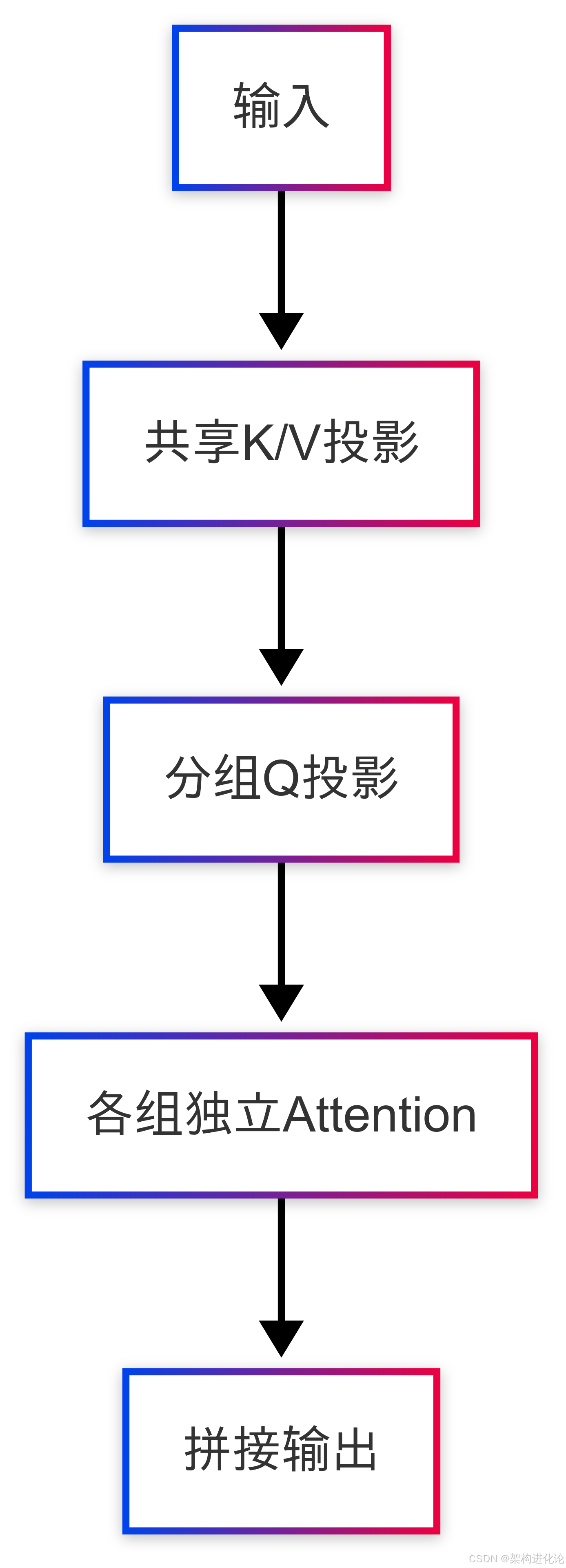
关键技术演进历程
发展时间线
| 时期 | 技术里程碑 | 关键突破 |
|---|---|---|
| 2017 | 原始Transformer | 自注意力机制诞生 |
| 2019 | GPT-2的KV Cache雏形 | 显式缓存past_key_values |
| 2020 | TensorRT的KV Cache优化 | 内存连续存储优化 |
| 2022 | Llama的RoPE适配方案 | 位置编码与Cache完美融合 |
| 2023 | vLLM的PagedAttention | 非连续内存管理 |
性能对比实验
在Llama-2 13B上的测试数据:
| 序列长度 | 原始方案(ms/token) | KV Cache(ms/token) | 内存节省 |
|---|---|---|---|
| 512 | 125 | 38 | 4.2x |
| 1024 | 478 | 72 | 7.1x |
| 2048 | 1892 | 135 | 12.6x |
工程实现深度解析
内存管理代码示例
class KVCache:
def __init__(self, max_batch_size, max_seq_len, n_heads, head_dim):
self.cache_k = torch.zeros(
(max_batch_size, max_seq_len, n_heads, head_dim),
dtype=torch.float16, device='cuda'
)
self.cache_v = torch.zeros_like(self.cache_k)
self.seq_pos = 0 # 当前写入位置
def update(self, new_k, new_v):
# new_k/v shape: [batch, n_heads, 1, head_dim]
batch_size = new_k.size(0)
self.cache_k[batch_idx, self.seq_pos] = new_k
self.cache_v[batch_idx, self.seq_pos] = new_v
self.seq_pos += 1
def get(self):
return self.cache_k[:, :self.seq_pos], self.cache_v[:, :self.seq_pos]计算复杂度分析
对于长度为 的序列:
看似总计算量相同,但:
-
避免了重复计算
-
实现了内存访问局部性
-
支持预填充优化
极限挑战与创新方案
内存墙问题
KV Cache的显存占用公式:
以Llama2-70B(n_layers=80, d=128)为例:
-
b=4, s=2048时:约60GB显存占用
突破性解决方案
vLLM的PagedAttention
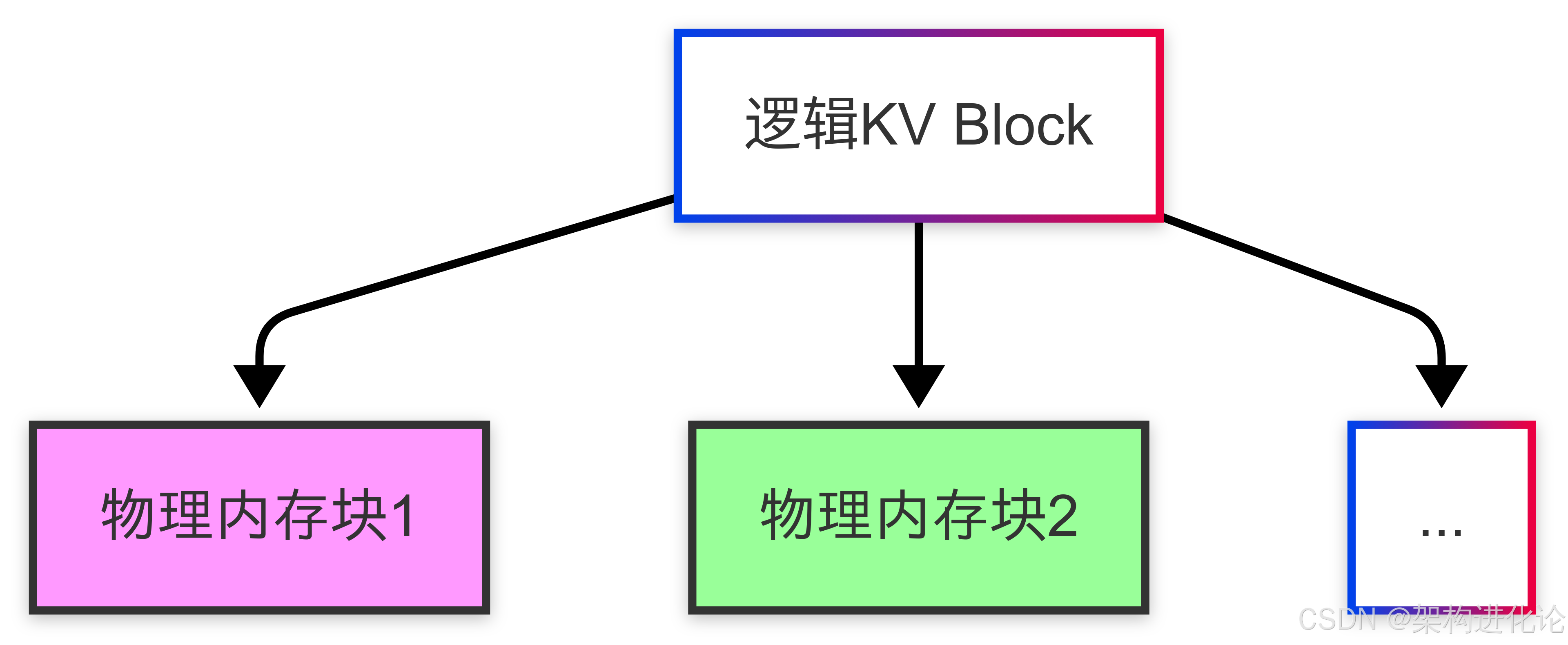
量化压缩
def quantize_kv(cache, bits=4):
scale = cache.abs().max() / (2**(bits-1)-1)
int_val = torch.clamp(torch.round(cache/scale), -2**(bits-1), 2**(bits-1)-1)
return int_val, scale
def dequantize(int_val, scale):
return int_val * scale未来发展方向
动态稀疏化
-
基于重要性得分的KV淘汰策略
-
混合精度Cache管理
硬件协同设计
-
NVIDIA H100的KV Cache专用内存区
-
光子芯片的近存计算架构
数学基础创新
-
基于状态空间模型(SSM)的替代方案
-
循环注意力机制研究


















 2341
2341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









