




在当今人工智能飞速发展的时代,大型语言模型(LLM)已成为技术创新的核心驱动力。选择合适的开发框架对于构建高效、可扩展的大模型应用至关重要。本文将对四种主流大模型开发框架——Spring AI、LangChain、LangGraph和LlamaIndex进行全面对比分析,从核心架构、功能特性、适用场景到性能表现等多个维度展开深入探讨,帮助开发者根据项目需求做出明智的技术选型决策。
框架概述与核心定位
在深入比较之前,我们首先需要明确各框架的基本定位和设计哲学,这是理解其适用场景的基础。四种框架虽然都服务于大模型应用开发,但各自有着不同的侧重点和技术路线。
Spring AI是Spring生态系统中的新成员,专为Java开发者设计,旨在将大模型能力无缝集成到企业级Java应用中。作为Spring官方推出的框架,它继承了Spring生态系统的诸多优势,如依赖注入、自动配置和与Spring Boot的深度集成。Spring AI提供了对多种大模型供应商的统一抽象接口,支持OpenAI、Microsoft、Amazon、Google、HuggingFace等主流模型服务。其核心设计理念是“为Java开发者提供简单易用的AI开发体验”,特别适合已有Spring技术栈的企业快速引入AI能力。
LangChain是一个功能全面的Python框架,被誉为“大模型开发界的瑞士军刀”。它采用模块化设计,支持将不同组件(如模型、记忆、工具等)链接成复杂的工作流。LangChain的核心优势在于其灵活性和扩展性,能够处理从简单问答到复杂多步骤任务的各种场景。它提供了丰富的集成选项,包括与各类数据库、API和文件系统的连接能力,使其成为构建复杂NLP应用的强大工具。LangChain的学习曲线相对陡峭,但一旦掌握,开发者几乎可以实现任何基于大模型的创意(扩展阅读:Java大模型开发框架深度对决:Spring AI与LangChain4j的技术选型指南-优快云博客)。
LangGraph是LangChain生态系统中的扩展组件,专注于构建有状态、循环的工作流。与传统的链式结构不同,LangGraph引入了图计算的概念,允许开发者构建包含分支、循环和状态保持的复杂推理流程。这种架构特别适合需要多轮交互、动态决策的应用场景,如高级对话系统和复杂任务自动化。LangGraph可以看作是LangChain在复杂工作流管理方面的补充和增强。
LlamaIndex(前身为GPT-Index)则采取了完全不同的技术路线,专注于高效数据检索和索引优化。它的核心价值在于为大型语言模型提供快速、精准的数据访问能力,特别适合构建检索增强生成(RAG)系统。LlamaIndex通过先进的索引策略和查询优化技术,能够高效处理海量文档的存储和检索问题,使大模型能够基于特定领域知识生成更准确的响应。与LangChain的广泛适用性不同,LlamaIndex在数据检索这一垂直领域做到了极致优化。
| 框架 | 核心定位 | 主要优势 | 典型使用场景 |
|---|---|---|---|
| Spring AI | Java生态的大模型集成框架 | Spring生态无缝集成,企业级支持 | Java企业应用快速AI化 |
| LangChain | 通用大模型应用开发框架 | 模块化设计,高度灵活 | 复杂NLP应用,多组件集成 |
| LangGraph | 复杂工作流管理框架 | 状态保持,循环控制 | 多轮对话,动态决策系统 |
| LlamaIndex | 高效数据检索与索引框架 | 检索性能优化,RAG支持 | 知识密集型应用,文档问答 |
从技术架构角度看,这四种框架体现了不同的设计哲学。Spring AI采用传统的分层架构,强调与企业现有系统的兼容性;LangChain采用模块化链式架构,强调组件的可组合性;LangGraph引入图计算模型,强调复杂流程的动态性;LlamaIndex则专注于索引和检索的性能优化。理解这些根本差异是进行技术选型的第一步。
功能特性与技术架构深度解析
深入理解各框架的技术架构和功能特性是做出明智选择的关键。本节将从核心组件、扩展能力、语言支持等多个维度进行详细对比分析,揭示各框架的内在机制和独特价值。
Spring AI的技术实现与Java生态整合
Spring AI作为Java生态中的大模型框架,其架构设计充分考虑了Java开发者的习惯和企业应用的需求。它提供了一系列标准化的抽象接口,如ChatClient、EmbeddingClient和VectorStore等,使开发者可以用统一的方式与不同的大模型服务交互。这种设计显著降低了切换模型供应商的成本,提高了代码的可维护性。
Spring AI的一个显著特点是其自动配置能力。通过Spring Boot的starter机制,开发者只需添加相关依赖并配置必要的API密钥,即可快速启用大模型功能。例如,要集成OpenAI的聊天服务,只需在application.properties中配置:
spring.ai.openai.api-key=your-api-key
spring.ai.openai.chat.model=gpt-4然后在代码中注入ChatClient即可使用:
@RestController
public class AiController {
private final ChatClient chatClient;
public AiController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai/chat")
public String chat(@RequestParam String message) {
return chatClient.call(message);
}
}Spring AI还提供了对向量数据库的集成支持,包括Chroma、Milvus、Neo4j、PGVector等,方便开发者构建RAG应用。在数据处理方面,Spring AI提供了ETL(抽取、转换、加载)框架,能够将各种格式的数据转换为模型可用的形式。
然而,Spring AI的功能深度相比LangChain仍有一定差距。例如,在实现复杂对话逻辑或工具调用时,Spring AI的抽象层级较高,灵活性相对不足。对于需要精细控制的应用场景,开发者可能需要直接操作底层API或结合其他框架使用。
LangChain的模块化设计与链式架构
LangChain的核心创新在于其链式架构(Chain Architecture),它允许开发者将不同的处理单元(称为“链”)连接起来,形成复杂的工作流。每个链可以执行特定的任务,如调用模型、处理输入/输出、访问外部数据等。这种设计既保证了灵活性,又提高了代码的可复用性。
LangChain的功能模块可以概括为以下几个核心组件:
-
模型交互层:提供与各种LLM的统一接口,包括OpenAI、Anthropic、Hugging Face等主流模型提供商。
-
记忆系统:支持对话历史管理,使模型能够保持上下文感知。记忆可以是简单的对话轮次记录,也可以是复杂的向量化记忆存储。
-
索引与检索:包括文档加载、文本分割、向量存储和检索器等组件,支持构建知识增强的应用。
-
工具与代理:允许模型调用外部工具(如计算器、API、数据库查询等),实现更复杂的功能。
-
链与流水线:将上述组件组合成可执行的工作流,支持条件逻辑和有限的状态管理。
LangChain的典型使用模式是构建“代理”(Agent)——一个能够根据输入自主选择工具和行动路径的智能系统。例如,一个客服代理可能根据用户问题决定是直接回答、查询知识库还是转接人工服务。这种能力使LangChain非常适合构建复杂的交互式应用。
LangChain的另一个优势是其多语言支持,除了Python外,还提供了JavaScript/TypeScript的实现(LangChain.js),适合全栈开发。然而,LangChain的复杂性也带来了较高的学习曲线,初学者可能需要花费较长时间才能掌握其核心概念和最佳实践。
LangGraph的状态管理与循环工作流
LangGraph是LangChain生态系统中的扩展,专门用于处理传统链式架构难以应对的复杂控制流需求。它引入了图计算的概念,将工作流建模为有向图,其中节点表示处理步骤,边表示步骤间的转移条件。
LangGraph的核心创新在于对状态管理和循环控制的支持。在传统的链式结构中,数据处理通常是单向流动的,难以实现多轮交互或动态调整流程。而LangGraph允许工作流保持内部状态,并根据状态内容决定下一步行动,甚至循环执行某些步骤直到满足条件。
这种架构特别适合以下场景:
-
多轮对话系统:根据用户输入的意图动态调整对话路径
-
复杂任务分解:将大任务拆分为子任务并监控执行进度
-
自适应处理流程:根据中间结果选择不同的处理策略
LangGraph的典型使用模式是定义状态结构和节点函数,然后组合成工作流图。例如:
from langgraph.graph import Graph
def node1(state):
# 处理逻辑
return {"new_data": processed_data}
def node2(state):
# 另一处理逻辑
return {"more_data": other_data}
workflow = Graph()
workflow.add_node("node1", node1)
workflow.add_node("node2", node2)
workflow.add_edge("node1", "node2")
workflow.set_entry_point("node1")虽然功能强大,但LangGraph的学习曲线更为陡峭,且目前生态相对较小,适合有特定复杂流程需求的进阶用户。
LlamaIndex的高效索引与检索优化
LlamaIndex专注于解决大模型应用中的一个关键挑战:如何让模型高效访问和组织大规模私有数据。与通用框架不同,LlamaIndex将全部精力放在数据索引和检索优化上,形成了独特的技术优势。
LlamaIndex的核心架构包含以下几个关键组件:
-
数据连接器:支持从各种数据源(如PDF、Word、网页、数据库等)加载内容。
-
索引构建器:将原始数据转换为高效的索引结构,包括扁平索引、层次索引、关键字索引和向量索引等。
-
查询引擎:提供灵活的检索接口,支持关键词搜索、语义搜索和混合搜索等多种模式。
-
检索器:根据查询从索引中获取相关内容,支持多种相似度计算和排序算法。
LlamaIndex的一个突出特点是其对检索性能的极致优化。它采用了多种先进技术来提高大规模数据检索的效率:
-
分层索引:将数据组织为多级结构,平衡检索速度和内存占用
-
智能缓存:缓存频繁访问的内容和中间结果,减少重复计算
-
查询重写:分析并优化用户查询,提高检索精准度
-
分布式处理:支持水平扩展,应对超大规模数据集
LlamaIndex的典型使用场景是构建RAG(检索增强生成)系统。开发者可以轻松地将它与各种LLM结合,创建基于特定知识库的问答或摘要应用。例如:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 加载文档
documents = SimpleDirectoryReader("data/").load_data()
# 构建向量索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 执行查询
response = query_engine.query("什么是量子计算?")
print(response)LlamaIndex的API设计相对简洁,学习曲线比LangChain平缓,特别适合数据密集型的应用场景。然而,它在通用NLP任务处理方面的能力有限,通常需要与其他框架配合使用以获得完整功能。
适用场景与性能对比分析
了解各框架的理论特性后,我们需要将其置于实际应用场景中进行对比,考察它们在具体任务中的表现和适用性。本节将通过典型用例分析、性能指标比较和限制因素探讨,帮助开发者根据项目需求做出合理选择。
各框架的典型应用场景分析
不同的业务需求需要不同的技术解决方案。通过分析各框架的设计目标和功能侧重,我们可以建立清晰的场景-框架匹配关系。
Spring AI最适合Java企业环境中需要快速集成AI能力的场景。例如:
-
传统Java应用的AI功能扩展:为现有Spring Boot应用添加智能聊天、内容生成或数据分析功能,无需重构整体架构。
-
企业级AI服务开发:利用Spring的安全、事务管理和微服务支持,构建符合企业标准的AI服务。
-
云原生AI应用:结合Spring Cloud和Kubernetes生态系统,开发可扩展的分布式AI应用。
Spring AI在这些场景中的优势在于其与Java生态的无缝集成,以及Spring框架本身提供的企业级功能支持。然而,对于需要复杂NLP处理或灵活工作流管理的场景,Spring AI可能显得力不从心。
LangChain是构建复杂NLP应用的首选框架。典型场景包括:
-
多功能聊天机器人:需要结合对话管理、工具调用和知识检索的智能助手。
-
定制化内容处理流水线:如自动文档摘要、多语言翻译、情感分析等复杂文本处理任务。
-
智能决策系统:基于大模型分析输入数据,调用适当工具或API执行操作的自动化系统。
LangChain的模块化设计使其能够灵活应对各种非常规需求,开发者可以通过组合现有组件或创建自定义模块来实现特定功能。这种灵活性是以更高的复杂性为代价的,适合有一定经验的团队。
LangGraph专为解决复杂工作流问题而设计。其典型应用场景有:
-
多轮对话系统:需要根据上下文动态调整对话路径的客服或导购机器人。
-
自适应任务处理:如根据输入内容选择不同处理策略的文档分析系统。
-
循环验证流程:需要多次迭代直至满足质量标准的自动内容生成或代码编写。
LangGraph的状态管理和循环控制能力填补了传统链式架构的空白,为复杂交互式应用提供了新的可能性。然而,对于简单线性任务,使用LangGraph可能会引入不必要的复杂性。
LlamaIndex在数据密集型应用中表现卓越。主要场景包括:
-
企业知识库问答:基于内部文档构建的智能问答系统。
-
专业领域辅助工具:如法律、医疗或金融领域的文档检索与分析应用。
-
实时信息检索系统:需要快速访问最新数据的应用,如新闻摘要或市场分析。
LlamaIndex的检索优化特性使其能够高效处理百万级甚至更大规模的文档集合,这是其他框架难以比拟的。但对于不依赖大量外部数据的应用,LlamaIndex可能不是最佳选择。
性能指标与资源需求对比
在实际应用中,框架的性能表现和资源需求直接影响系统的可用性和运营成本。我们从计算效率、内存占用和学习成本三个维度进行比较分析。
计算效率方面,LlamaIndex在数据检索任务中表现最为出色。它采用多种优化技术如缓存、查询预处理和分布式索引,能够实现毫秒级的文档检索速度。LangChain和LangGraph由于需要处理更复杂的逻辑,其吞吐量通常较低,尤其是在涉及多个模型调用和工具执行的场景中。Spring AI在简单模型调用上效率较高,但复杂任务性能与LangChain相近。
内存占用方面,LlamaIndex再次领先,其索引结构经过专门优化,能够高效利用内存。LangChain和LangGraph由于需要维护各种组件和中间状态,内存消耗较大。Spring AI在Java环境中通常表现出更好的内存管理特性,尤其是在长时间运行的服务中。
学习成本是另一个重要考量因素。Spring AI对于已有Spring经验的Java开发者最为友好,学习曲线相对平缓。LlamaIndex的API设计简洁明了,专注于数据检索这一单一职责,新手较易上手。LangChain和LangGraph则需要掌握更多概念和模式,学习成本最高。
| 框架 | 计算效率 | 内存占用 | 学习成本 | 适用团队规模 |
|---|---|---|---|---|
| Spring AI | 高(简单任务) 中(复杂任务) | 中等 | 低(Java开发者) | 中大型企业团队 |
| LangChain | 中到低 | 高 | 高 | 有经验的AI团队 |
| LangGraph | 中 | 高 | 很高 | 专业AI研发团队 |
| LlamaIndex | 很高(检索任务) | 低 | 中等 | 各种规模团队 |
各框架的限制与挑战
任何技术选择都需要权衡利弊,了解各框架的限制有助于避免项目实施过程中的陷阱。
Spring AI的主要限制包括:
-
功能深度不足:相比Python生态的框架,Spring AI在某些高级功能上支持有限。
-
模型覆盖不全:对国内大模型和某些专业模型的支持不够完善。
-
创新延迟:作为较新的框架,Spring AI在采纳最新研究成果方面可能滞后于Python生态。
LangChain面临的挑战有:
-
复杂性高:丰富的功能带来了陡峭的学习曲线和较高的出错概率。
-
依赖管理困难:大型项目中组件版本冲突时有发生。
-
性能开销:模块化设计在带来灵活性的同时,也引入了额外的运行时开销。
LangGraph作为新兴框架,存在以下问题:
-
生态系统不成熟:可用组件和社区资源相对有限。
-
调试困难:复杂工作流的状态跟踪和问题诊断具有挑战性。
-
适用场景有限:不适合简单线性任务,可能造成过度设计。
LlamaIndex的局限性体现在:
-
功能单一:仅专注于数据检索,构建完整应用需要结合其他框架。
-
索引构建成本:大规模数据的初始索引过程可能耗时较长。
-
领域适应性:对某些特殊数据类型(如多媒体)的支持不够完善。
理解这些限制有助于开发者在选型时做出更全面的评估,避免项目后期遇到不可预见的技术障碍。
技术选型指南与最佳实践
理论对比之后,我们需要将知识转化为可执行的决策框架。本节将提供具体的技术选型方法论、混合使用策略以及面向未来的发展考量,帮助开发团队制定最优的技术采用路线。
基于项目需求的决策框架
选择大模型开发框架不是寻找“最好”的工具,而是寻找最适合当前项目和团队的技术方案。我们提出一个四维评估模型,帮助系统化决策过程:
应用复杂度维度:
-
简单直接的功能(如单一模型调用):Spring AI或LlamaIndex
-
中等复杂工作流(如条件逻辑链):LangChain
-
高度复杂交互(如多轮状态保持):LangGraph
技术栈维度:
-
Java/Spring生态系统:优先考虑Spring AI
-
Python生态系统:LangChain/LangGraph/LlamaIndex
-
全栈应用:考虑LangChain.js与后端组合
数据需求维度:
-
主要依赖模型内部知识:Spring AI或基础LangChain
-
需要集成外部数据源:LangChain+LlamaIndex组合
-
超大规模专有数据:LlamaIndex为核心
团队能力维度:
-
初级团队:Spring AI或LlamaIndex
-
有经验的AI团队:LangChain
-
高级研发团队:考虑LangGraph复杂工作流
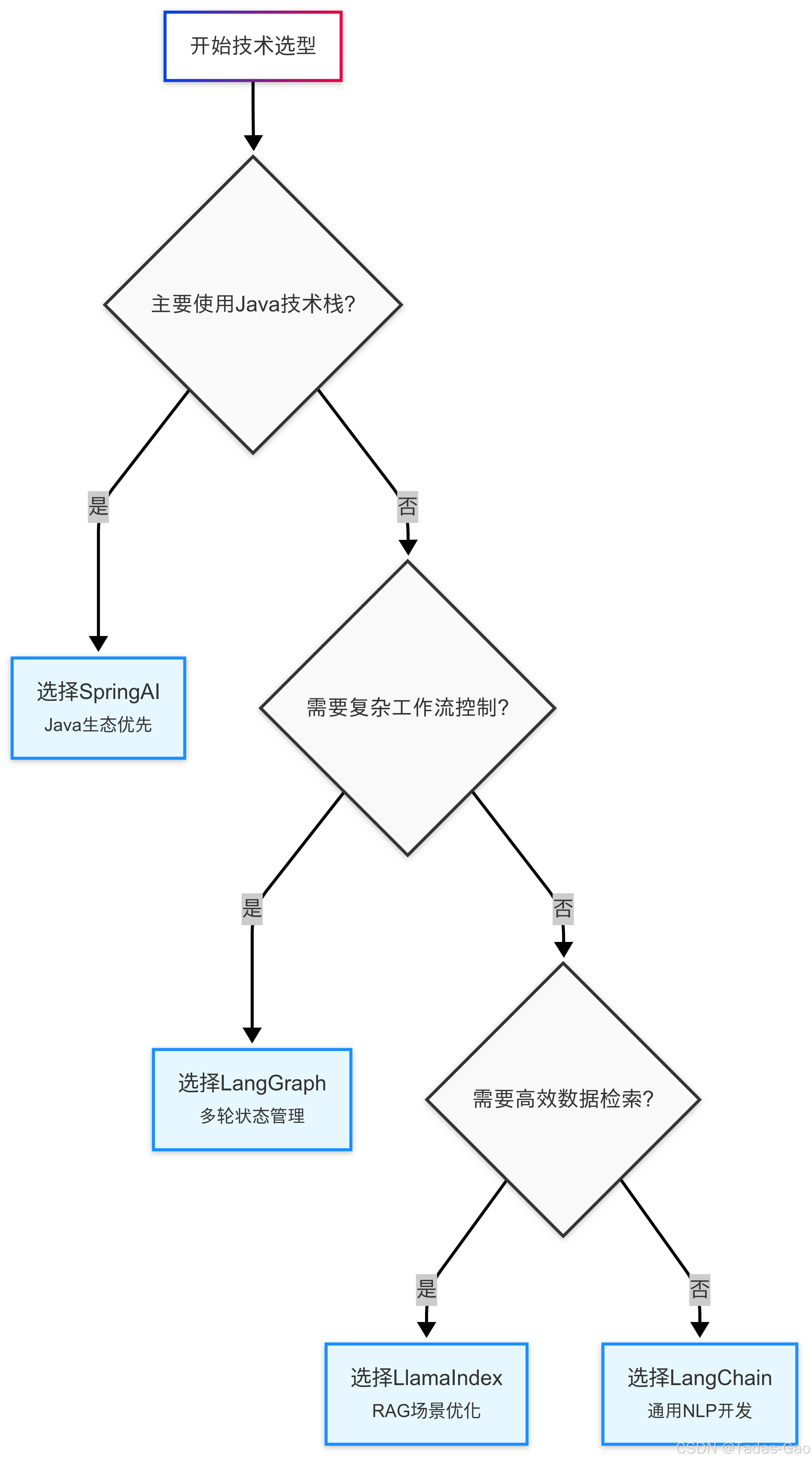
对于企业级决策,建议采用加权评分法。列出关键需求(如开发速度、性能要求、可维护性等),为每个需求分配权重,然后对各框架进行评分,最后计算加权总分作为选型参考。
混合架构与框架组合策略
在实际项目中,单一框架往往无法满足所有需求。明智的混合使用可以发挥各框架的优势,创造更强大的解决方案。以下是几种经过验证的有效组合模式:
LangChain + LlamaIndex:这是构建复杂RAG应用的黄金组合。LlamaIndex负责高效数据检索,LangChain处理工作流和模型交互。这种架构既保证了检索性能,又提供了灵活的流程控制。
# 组合使用示例
from llama_index import VectorStoreIndex
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# LlamaIndex构建索引
index = VectorStoreIndex.load_from_disk("index_dir")
# 转换为LangChain检索器
retriever = index.as_retriever()
# 构建LangChain问答链
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=retriever
)
# 执行查询
result = qa_chain.run("问题内容")Spring AI + Python框架:在Java为主的企业环境中,可以使用Spring AI处理基础集成,同时通过微服务架构调用Python实现的复杂AI功能。这种混合架构平衡了企业需求和技术创新。
LangChain + LangGraph:对于极端复杂的交互系统,可以用LangGraph管理高层工作流,而用LangChain处理具体的任务执行。这种分层设计提高了系统的可维护性。
混合架构虽然强大,但也带来了一些挑战:
-
跨语言交互:Java和Python间的数据交换需要设计良好的API契约
-
调试复杂性:问题可能出现在多个层次,需要综合诊断
-
运维负担:需要管理更多组件和依赖
建议采用渐进式混合策略:先以一个框架为主实现核心功能,再逐步引入其他框架解决特定问题,避免过度设计。
实施建议与学习路径
选定框架后,如何高效学习和实施同样重要。针对不同框架,我们推荐以下学习路径:
Spring AI:
-
从Spring官方文档和示例代码入手,了解基本概念
-
实践核心功能:聊天完成、嵌入生成、简单RAG
-
探索与Spring Security、Spring Data等组件的集成
-
研究企业级部署模式,如Kubernetes部署
LangChain:
-
从官方“Getting Started”教程开始,理解基本组件
-
重点掌握:模型封装、记忆管理、工具调用、代理构建
-
通过实际项目练习链式组合和自定义组件开发
-
学习性能优化和调试技巧,处理复杂场景
LangGraph:
-
先熟练掌握LangChain核心概念
-
研究状态管理和图工作流的基本模式
-
从简单循环流程开始,逐步构建复杂交互
-
学习调试和监控技术,确保系统可靠性
LlamaIndex:
-
快速上手数据加载和基本查询
-
深入理解不同索引类型的特性和适用场景
-
实践性能优化技巧:缓存、查询重写、分布式处理
-
学习与各种向量数据库和LLM的集成
对于团队能力建设,建议:
-
组织内部技术分享会,交流最佳实践
-
建立代码库和模板,避免重复工作
-
从POC项目开始,积累经验再扩大范围
-
关注框架更新,定期评估技术路线
未来趋势与长期考量
技术选型不仅要考虑当前需求,还需要展望未来发展。大模型框架领域有几个明显趋势值得关注:
-
多框架融合:框架间的界限逐渐模糊,如Spring AI吸收LangChain理念,LangChain增强检索能力。未来可能出现更统一的开发生态。
-
性能优化:随着应用规模扩大,框架的运行时效率和资源管理将变得更加关键。特别是对GPU资源的智能调度和优化。
-
企业特性增强:安全、审计、权限控制等企业级功能将成为框架的标准配置,而不仅是附加组件。
-
低代码/无代码集成:为降低使用门槛,框架可能提供更多可视化工具和配置选项,减少硬编码需求。
-
标准化进程:可能出现类似SQL的标准化查询语言或类似ONNX的模型交换格式,减少厂商锁定风险。
在长期项目规划中,建议:
-
选择活跃维护、社区健康的框架
-
评估供应商锁定风险,保持一定的可移植性
-
设计模块化架构,便于未来技术迁移
-
预留性能扩展空间,应对业务增长
技术决策需要平衡短期需求和长期发展,既要解决眼前问题,又要为未来演进留出空间。通过系统化的评估和实施策略,团队可以最大化框架选择带来的价值,构建可持续进化的大模型应用体系。



















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











