




大模型应用的技术特点:门槛低、天花板高(稍微有点基础都能上手,但搞懂搞透需要大量的积累和沉淀)
大模型应用的技术架构主要有四种方式:纯 prompt、Agent+Function Calling、RAG(检索增强生成)和 Fine-tuning(微调)。
纯 Prompt
纯 prompt 是最简单的大模型应用方式,直接通过自然语言指令(prompt)引导模型生成所需的输出。适合任务简单、无需额外数据或复杂逻辑的场景。
-
Prompt 是操作⼤模型的唯⼀接⼝
-
你说⼀句,它回⼀句,你再说⼀句,它再回⼀句
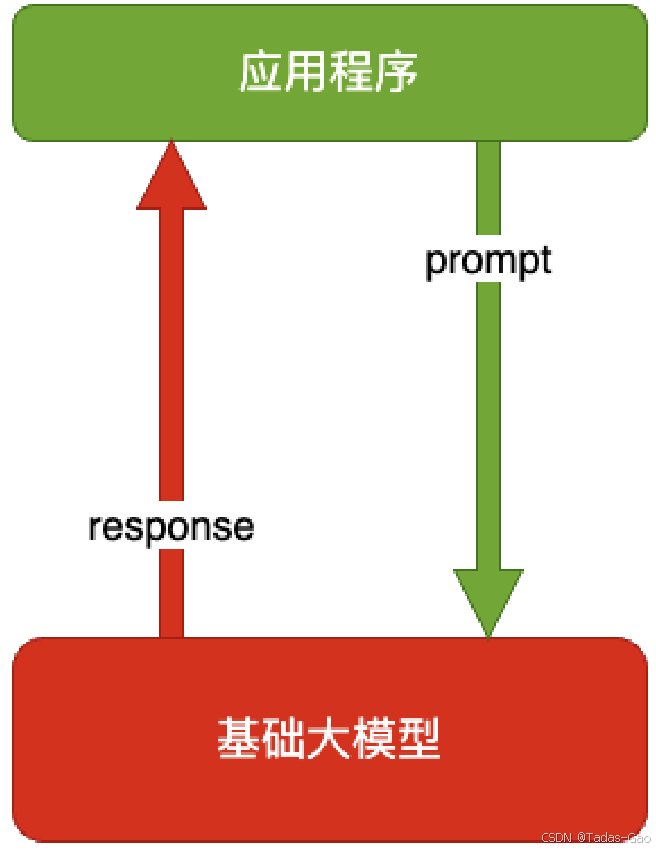
纯 prompt 的核心在于设计高效的提示词(prompt engineering),通过调整 prompt 的措辞、结构或示例,优化模型的输出质量。常见的技巧包括:
- 提供清晰的指令和上下文
- 使用 few-shot learning(示例学习)
- 添加限制条件(如输出格式)
response = model.generate(
"请用一句话总结以下文本:'大模型应用的技术架构包括多种方式。'"
)
优点在于开发成本低、部署简单,但依赖模型本身的能力上限,难以处理复杂任务或定制化需求。
Agent + Function Calling
Agent+Function Calling 架构通过将大模型作为“智能代理”(Agent),结合外部工具或函数(Function Calling)完成复杂任务。模型负责理解用户意图并调用合适的工具,工具执行具体操作后返回结果。
-
Agent:AI 主动提要求
-
Function Calling:AI 要求执⾏某个函数
-
你问它「我明天去杭州出差,要带伞吗?」,它让你先看天⽓预报,你看了告诉它,它再告诉你要不要带伞
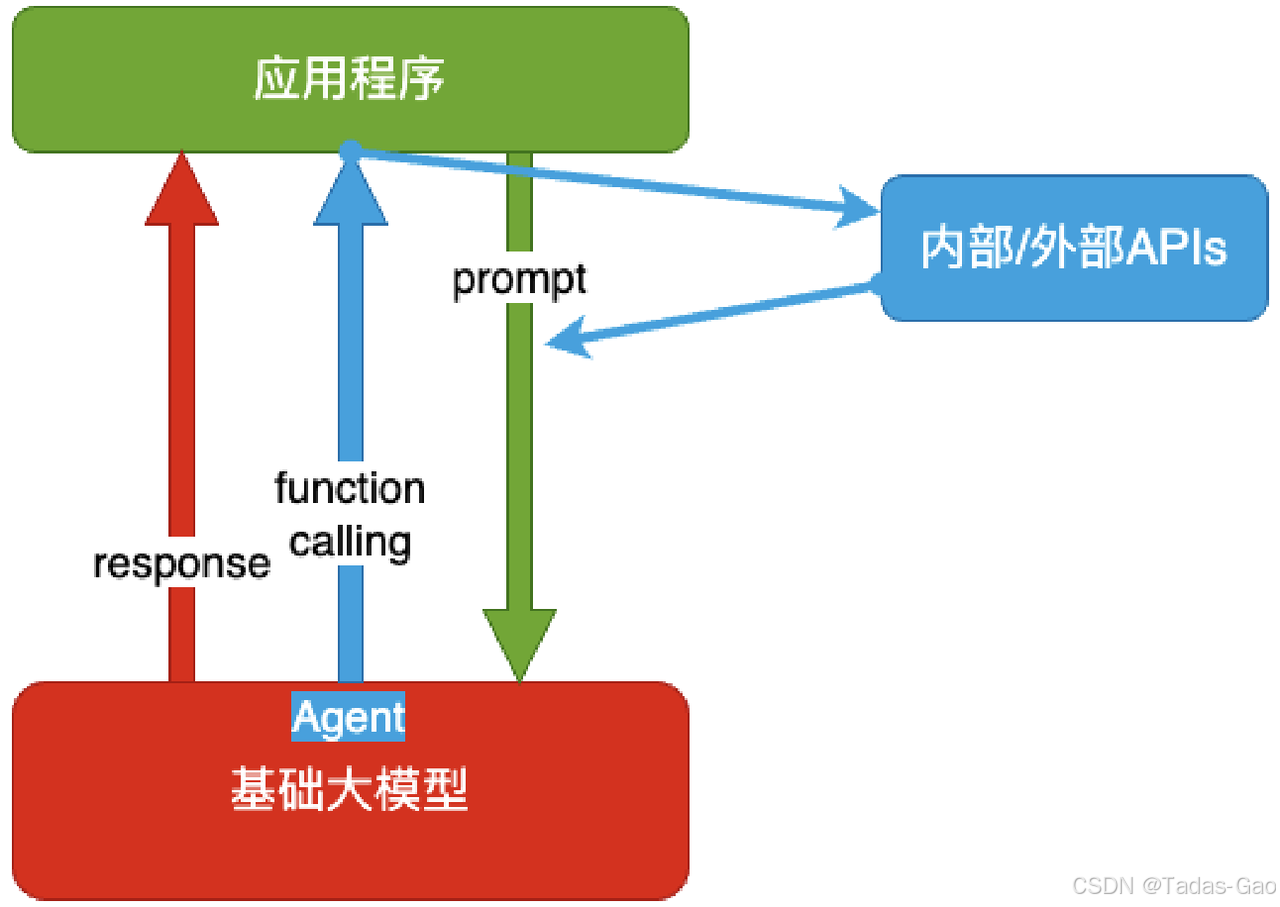
典型流程:
- 用户输入请求(如“查询北京天气”)
- 模型判断需要调用天气 API
- 系统执行 API 调用
- 模型整合 API 返回结果并生成回复
def get_weather(city):
# 调用天气 API
return weather_data
response = model.generate(
"用户问:'北京天气如何?'",
functions=[get_weather]
)
适合需要实时数据、计算或专业工具支持的任务(如数据分析、代码执行)。灵活性高,但需额外开发工具集成逻辑。
RAG
RAG 结合检索(Retrieval)和生成(Generation),通过从外部知识库检索相关信息,再输入模型生成答案。解决模型静态知识库的局限性,适合需要动态或领域知识的场景。
-
Embeddings:把⽂字转换为更易于相似度计算的编码
-
向量数据库:把向量存起来,⽅便查找
-
向量搜索:根据输⼊向量,找到最相似的向量
-
考试答题时,到书上找相关内容,再结合题⽬组成答案,然后,就都忘了
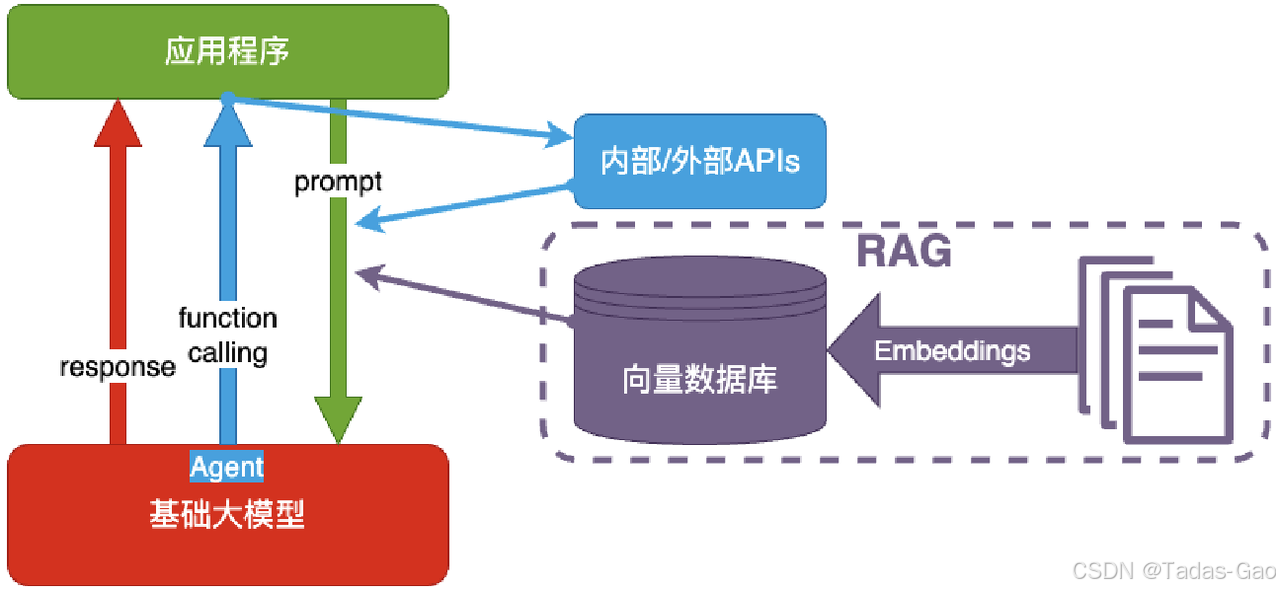
工作流程:
- 用户提问(如“最新的深度学习框架有哪些?”)
- 检索系统从文档/数据库查找相关内容
- 将检索结果与问题一起输入模型
- 模型生成最终答案
retrieved_docs = vector_db.search("最新深度学习框架")
response = model.generate(
f"根据以下资料回答问题:{retrieved_docs}\n问题:最新的深度学习框架有哪些?"
)
优点在于知识可更新、回答准确性高,但需维护检索系统和知识库。
Fine-tuning(精调 / 微调)
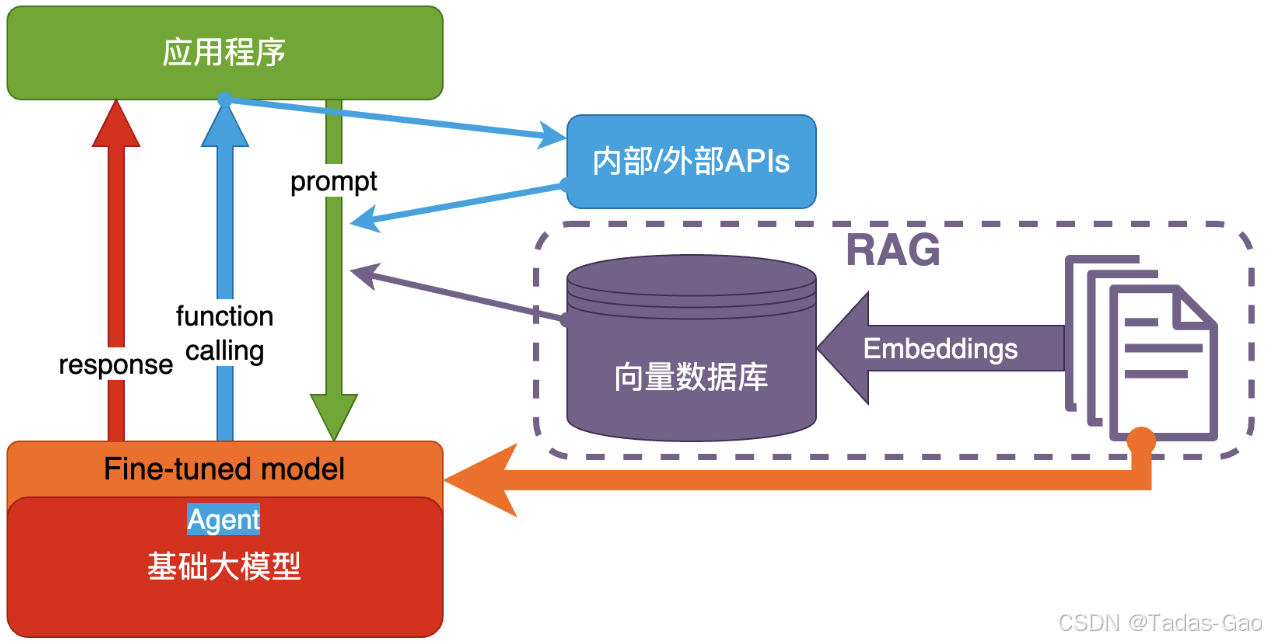
微调通过在领域数据上继续训练大模型,使其适配特定任务或领域。适合需要模型深度定制化的场景(如医疗、法律专业问答)。
微调分为全参数微调(调整所有模型参数)和高效微调(如 LoRA、Adapter,仅调整部分参数)。
-
努⼒学习考试内容,⻓期记住,活学活⽤。
from transformers import Trainer
trainer = Trainer(
model=model,
train_dataset=dataset,
args=training_args
)
trainer.train()
优点在于模型性能高度优化,但需要标注数据、计算成本高,且可能过拟合小规模数据。
架构选择建议
- 简单任务:优先尝试纯 prompt 或 RAG
- 实时数据/工具需求:选择 Agent+Function Calling
- 领域专业化:考虑 RAG 或 Fine-tuning
- 资源与成本:纯 prompt 和 RAG 更轻量,微调需评估投入产出比
实际应用中常组合多种架构(如 RAG+Agent)以平衡效果与成本。



















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











