




MAML
1.论文地址和代码
https://arxiv.org/abs/1703.03400
https://github.com/dragen1860/MAML-Pytorch
2.基本概念
Meta Learning是模仿人类的学习过程,先学习一个先验知识,并且利用这些知识,在新的问题上学的更快更好。通过学习到的模型,来学习新的模型。用任务task生成模型model。
2.1 举例
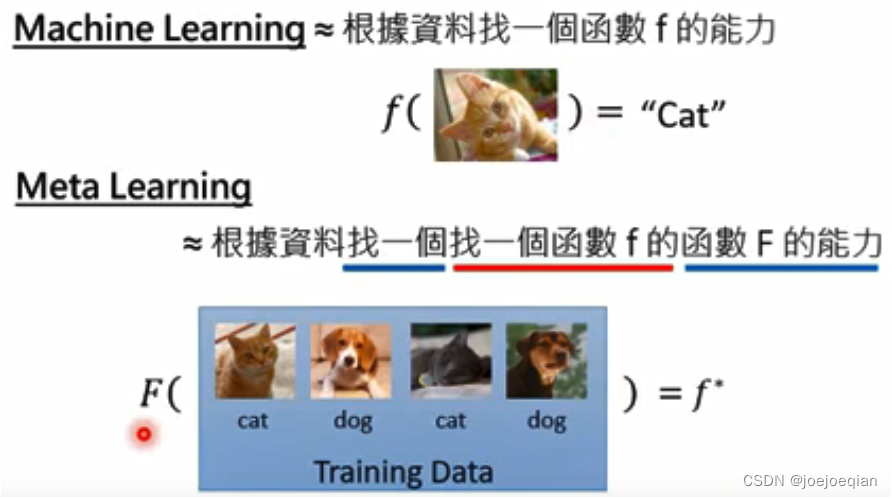
Meta learning是找一个 F F F,通过一堆任务训练,得到参数 θ \theta θ,然后对新的分类任务时,让 θ \theta θ自己调整适合新任务的、分类模型的、最优 θ ∗ \theta^* θ∗,这个调整只需要几步。
所以,怎么找这个参数 θ \theta θ就成了我们的目标。
2.1.1 元学习的目标
元学习的目标是在接触到新任务或者迁移到新环境中时,可以根据之前的经验和少量的样本快速学习去应对。
2.1.2 元学习有三种常见的实现方法
- 1)学习有效的距离度量方式(基于度量的方法);
- 2)使用带有显式或隐式记忆储存的(循环)神经网络(基于模型的方法);
- 3)训练以快速学习为目标的模型(基于优化的方法)
三种方式分别举例:
- 在没有猫的训练集上训练出来一个图片分类器,这个分类器需要在看过少数几张猫的照片后分辨出测试集的照片中有没有猫。
- 训练一个玩游戏的AI,这个AI需要快速学会如何玩一个从来没玩过的游戏。
- 一个仅在平地上训练过的机器人,需要在山坡上完成给定的任务。
3.MAML
3.1 MAML就是用于找参数 θ \theta θ的方法

它是基于初始化的方法。
3.2 MAML的基本思路
1.假设有一个适用于所有task的初始化参数 θ \theta θ。
2. θ \theta θ经过每一个 t a s k i , i = 1 , 2 , ⋯ , n task_i,i=1,2,\cdots,n taski,i=1,2,⋯,n都会得到对应的专属参数 θ 1 , θ 2 , ⋯ , θ n \theta_1,\theta_2,\cdots,\theta_n θ1,θ2,⋯,θn。
3.如果能找到一个很好的初始化参数 θ \theta θ,对于新任务,它只需要经过很少的步数就能获得新任务的 θ i \theta_i θi,并且在新任务上表现的很好。
评价初始 θ \theta θ的指标
主要看它被更新为 θ i \theta_i θi之后,在对应的任务 T i T_i Ti表现情况,对表现的评估用loss来评估。
4.每次输入一个batch的tasks,然后利用 θ \theta θ在这个batch中所有的tasks上更新,更新完毕后把这些Task上的测试损失值求和,得到一个大Loss(这个batch中所有任务的损失之和),然后用这个Loss来评价 θ \theta θ的好坏,然后通过优化方法找到最好的初始化参数 θ \theta θ,这样就找到一个很好的初始化参数 θ \theta θ,对于新任务,它只需要经过很少的步数就能获得新任务的 θ i \theta_i θi,并且在新任务上表现的很好。
3.3 基本术语
task任务:把已有的数据集切分转化为多个任务。
举例:以Mini-ImageNet数据集为例,如下图:
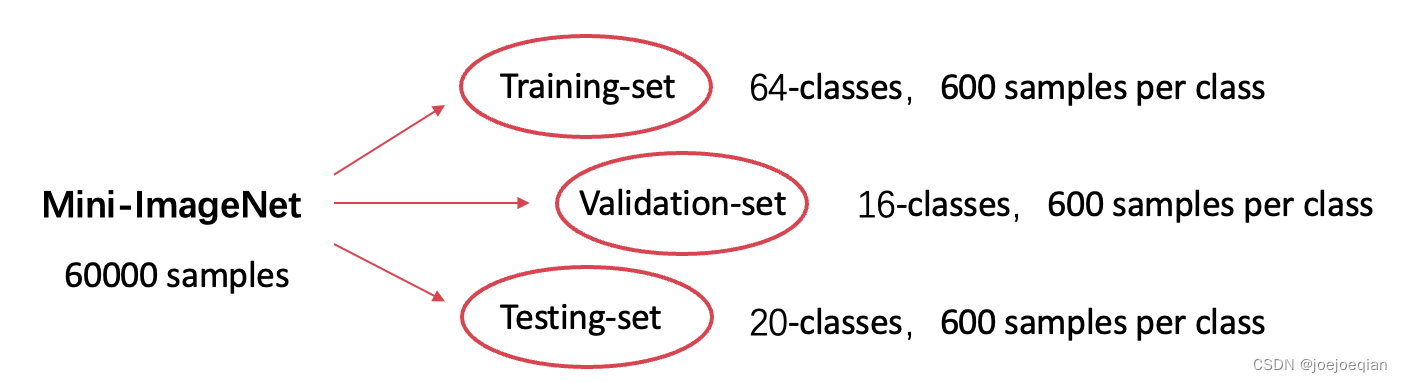
其中,每张图片剪裁成84*84的大小.
将训练集变成训练任务,这些训练任务就变成了N-way K-shot任务(或者是N-way K-shot Q-Query)。
N-way :从数据集上随机抽取N个类别
K-shot:每个类别下面抽取K个样本用于任务的训练。
N-way K-shot组成的数据集被称为Support set。
Q-Query:对N个类别每一个类别中再次抽取Q个样本,作为Query集,用于测试。
实际每个类别要抽取K+Q个样本,这样就得到了N-way K-shot任务。
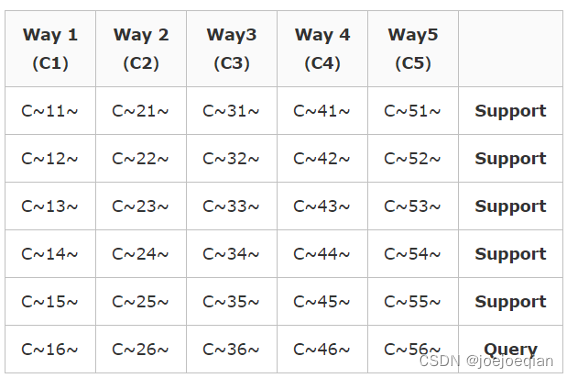
下面这个例子,就是5-way 5-shot 1-Query任务:
3.4 从数据集中抽样的方法
举例,如对Mini-ImageNet做5-way 1-shot 15-Query

每个文件夹对应一个类别,每次抽取5个文件夹(相当于抽取了5个类)
Random.sample(folders, self.n_way)
然后每个文件夹抽取16张图片
labels_and_images = get_images(sampled_folders,
range(self.n_way),
nb_samples=self.n_img,
shuffle=False)
重复以上两步,200000次,就会得到200000个Tasks,作为训练任务集。
验证集和测试集也是同样的操作。
接下来:
假设batchsize为4,每一轮执行4个task,在meta-training时,按barch输入成tensor,4个任务,每个任务80张图片,图片大小为84x84x3,label为类别,5个类别,即得:
support_x : [4, 1x5, 84x84x3]
query_x : [4, 15x5, 84x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









