




Go语言学习笔记(九)
一、使用字符串
Go语言支持两种创建字符串字面量的方法
- 解释型字符串字面量是用
双引号括起的字符,在这里面还包括了rune字面量,rune字面量可将解释型字符串字面量分成多行,还可以在其中包含制表符合其他格式选项。- 原始字符串字面量是用
反引号括起,如`hello`。不同于解释型字符串,原始字符串中的反斜杠没有特殊含义(原始字符串不支持转义字符),Go按原样解释这种字符串。通过使用原始字符串字面量,无需使用反斜杠就能生成和解释型字面量同样的输出。
1 创建字符串字面量
s := "I am an interpreted string literal"
fmt.Println(s)
就是双引号包围的字符串
2 rune字面量
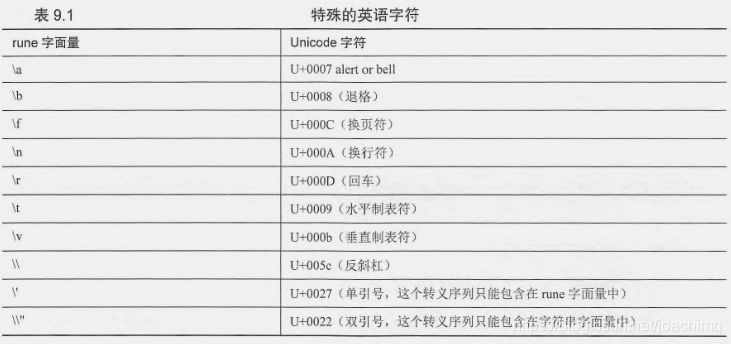
就是转义字符
通过使用rune字面量可以对字符串字面量进行格式划分(不是格式化输出),但实际上,不适用rune字面量也能达到相同的效果。
在如下实例中,我们仅仅使用了原始的字符串字面量
>输出结果如下:
在上面的例子中,我们并没有使用rune字面量,同样达到了我们想要的输出结果和格式,这说明Go语言支持隐形的\n等字符

3 拼接字符串
注意+和+=
同样的,Go语言不支持非字符串类型的拼接,辣么应该肿么办呢,我们可以使用strconv包中的Itoa方法完成字符串类型的转换
package main
import (
"fmt"
"strconv"
)
func main() {
var i int = 1
var s string = " egg"
intTostring := strconv.Itoa(i)
var breakfast string = intTostring + s
fmt.Println(breakfast)//输出:1 egg
}
3.1使用缓冲区拼接字符
- 当我们对少量的字符串进行拼接时,可以使用运算符进行操作,但是如果是数量很多的字符串进行拼接,使用操作符的效率并不高。
- 如果需要在循环中拼接字符串,则使用空的字节缓冲区来拼接的效率会更高。
package main
import (
"bytes"
"fmt"
)
func main() {
var buffer bytes.Buffer
fmt.Printf("%+v\n", buffer)//{buf:[] off:0 lastRead:0}
for i := 0; i < 10; i++ {
buffer.WriteString("z")
}
fmt.Println(buffer.String())//zzzzzzzzzz
}
3.3 处理字符串
对字符串的处理基于strings包中提供的函数
3.3.1 将字符串转换为小写
函数ToLower接受一个字符串作为参数,并将其中所有的大写字符全部转换为小写
使用方法strings.ToLower(字符串),返回一个全部是小写字母的字符串
3.3.2 查找子串
方法Index,找到子串返回第一个子串的索引号,否则返回-1
使用方法:strings.Index(string,substring)
3.3.3 删除字符串中开头和结尾的空格
TrimSpace方法,使用方法和3.3.1中的一样,这里要注意的是删除之后len(变量名)会发生改变
4 相关问题
- Go语言支持UTF-8,能在代码中使用除英语以外的其他语言么?
废话,当然行了。Go语言代码被解读为UTF-8,这意味着函数和方法的名称可包含UTF-8支持的任何字符(有点强) - 创建字符串后,可以对其进行修改吗?
不行。因为字符串相当于是C++中的常量,你见过修改常量的??
参考书籍
[1]: 【Go语言入门经典】[英] 乔治·奥尔波 著 张海燕 译


















&spm=1001.2101.3001.5002&articleId=115483268&d=1&t=3&u=9cd29d20abaf4c0dbf3fc028992fffd7)
 4165
4165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











