




 本文深入探讨了Spark2.X的内存管理模型,包括执行内存和存储内存的使用,以及如何在不同工作负载下实现内存资源的有效分配。通过理解Spark内存管理机制,用户可以更好地优化应用程序性能。
本文深入探讨了Spark2.X的内存管理模型,包括执行内存和存储内存的使用,以及如何在不同工作负载下实现内存资源的有效分配。通过理解Spark内存管理机制,用户可以更好地优化应用程序性能。
Spark2.X的内存管理模型如下图所示:
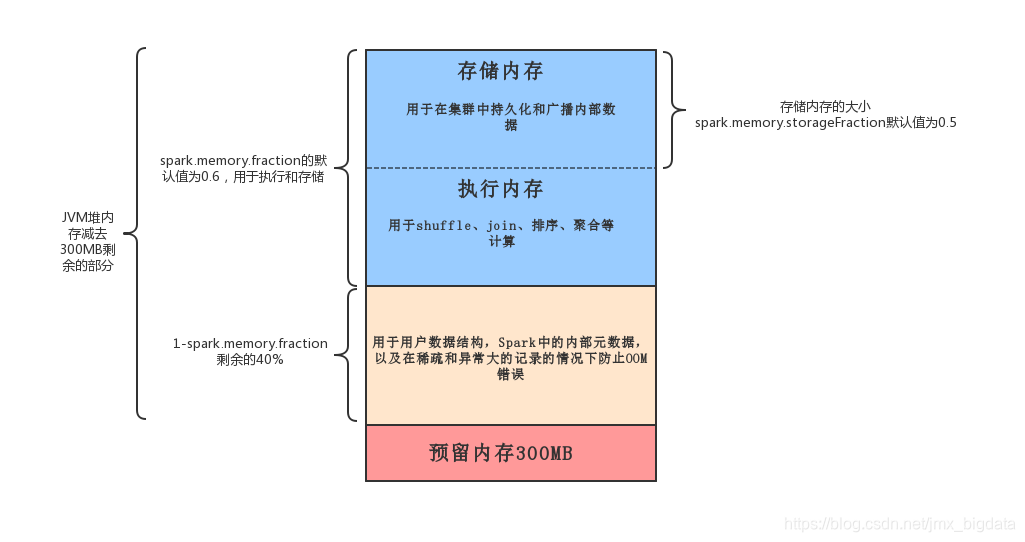
Spark中的内存使用大致包括两种类型:执行和存储。执行内存是指用于用于shuffle、join、排序、聚合等计算的内存,而存储内存是指用于在集群中持久化和广播内部数据的内存。在Spark中,执行内存和存储内存共享一个统一的区域。当没有使用执行内存时,存储内存可以获取所有可用内存,反之亦然。如有必要,执行内存可以占用存储存储,但仅限于总存储内存使用量低于某个阈值。
该设计确保了几种理想的特性。首先,不使用缓存的应用程序可以使用整个空间执行,从而避免不必要的磁盘溢出。其次,使用缓存的应用程序可以保留最小存储空间。最后,这种方法为各种工作负载提供了合理的开箱即用性能,而无需用户内部划分内存的专业知识。
虽然有两种相关配置,但一般情况下不需要调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction默认大小为(JVM堆内存 - 300MB)的一小部分(默认值为0.6)。剩下的空间(40%)保留用于用户数据结构,Spark中的内部元数据,以及在稀疏和异常大的记录的情况下防止OOM错误。
spark.memory.storageFraction默认大小为(JVM堆内存 - 300MB)*0.6*0.5。

















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









