




Apache Spark最初在2009年诞生于美国加州大学伯克利分校的APM实验室,并于2010年开源,如今是Apache软件基金会下的顶级开源项目之一。Spark的目标是设计一种编程模型,能够快速地进行数据分析。Spark提供了内存计算,减少了IO开销。另外Spark是基于Scala编写的,提供了交互式的编程体验。经过10年的发展,Spark成为了炙手可热的大数据处理平台,目前最新的版本是Spark3.0。本文主要是对Spark进行一个总体概览式的介绍,后续内容会对具体的细节进行展开讨论。本文的主要内容包括:
- Spark的关注度分析
- Spark的特点
- Spark的一些重要概念
- Spark组件概览
- Spark运行架构概览
- Spark编程初体验
Spark的关注热度分析
概况
下图展示了近1年内在国内关于Spark、Hadoop及Flink的搜索趋势
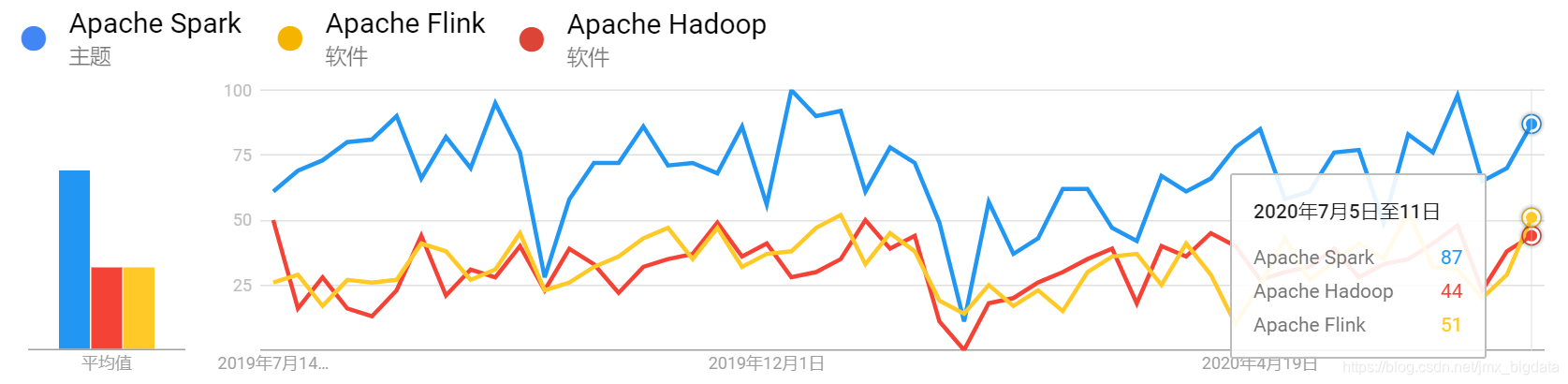
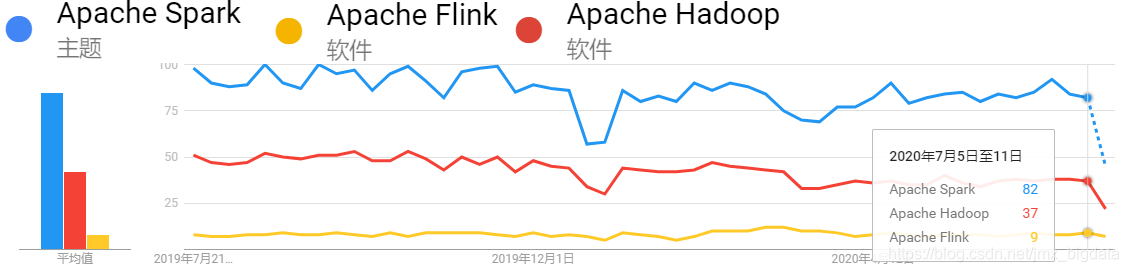
近1年内全球关于Spark、Hadoop及Flink的搜索趋势,如下:
近1年国内关于Spark、Hadoop及Flink的搜索热度区域分布情况(按Flink搜索热度降序排列):
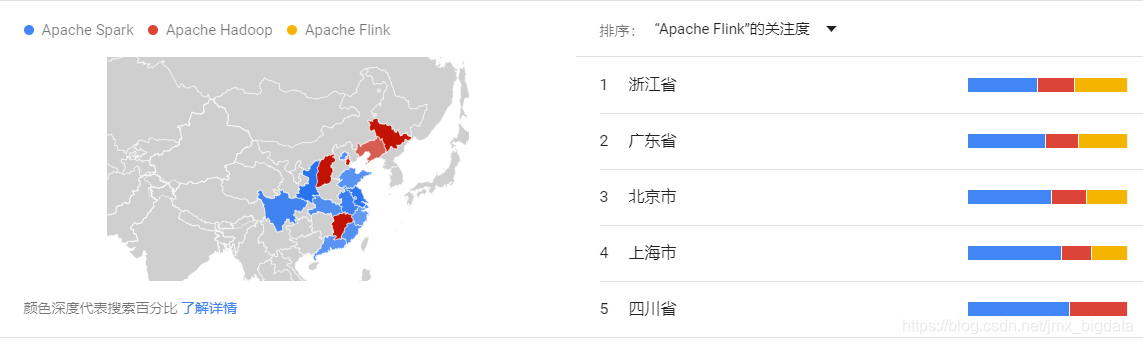
近1年全球关于Spark、Hadoop及Flink的搜索热度区域分布情况(按Flink搜索热度降序排列):

分析
从上面的4幅图可以看出,近一年无论是在国内还是全球,关于Spark的搜索热度始终是比Hadoop和Flink要高。近年来Flink发展迅猛,其在国内有阿里的背书,Flink天然的流处理特点使其成为了开发流式应用的首选框架。可以看出,虽然Flink在国内很火,但是放眼全球,热度仍然不及S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2694
2694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









