




 博主接到爬虫任务,尝试从网页提取论文链接。页面采用JS动态跳转,技术难点在于获取链接。先从审查元素的network切入找到含链接的data.js文件,后尝试用正则表达式、Java、find_all函数等方法提取链接,最终用C语言成功。但爬取网页时因链接失效失败。
博主接到爬虫任务,尝试从网页提取论文链接。页面采用JS动态跳转,技术难点在于获取链接。先从审查元素的network切入找到含链接的data.js文件,后尝试用正则表达式、Java、find_all函数等方法提取链接,最终用C语言成功。但爬取网页时因链接失效失败。
今天老师给了个爬虫的任务,我信誓蛋蛋的接下来了,觉得嗨呀不就是这么点事嘛和我上次爬hdu的题目一样小case,好的,用网页的审查元素尝试了一下找了一下链接的位置,才发现没这么简单。
1. 页面链接跳转采用js动态跳转
js的特点就是在开发工具项中是无法看到跳转的链接的,不像html,还有很明了的href标签,如图—— 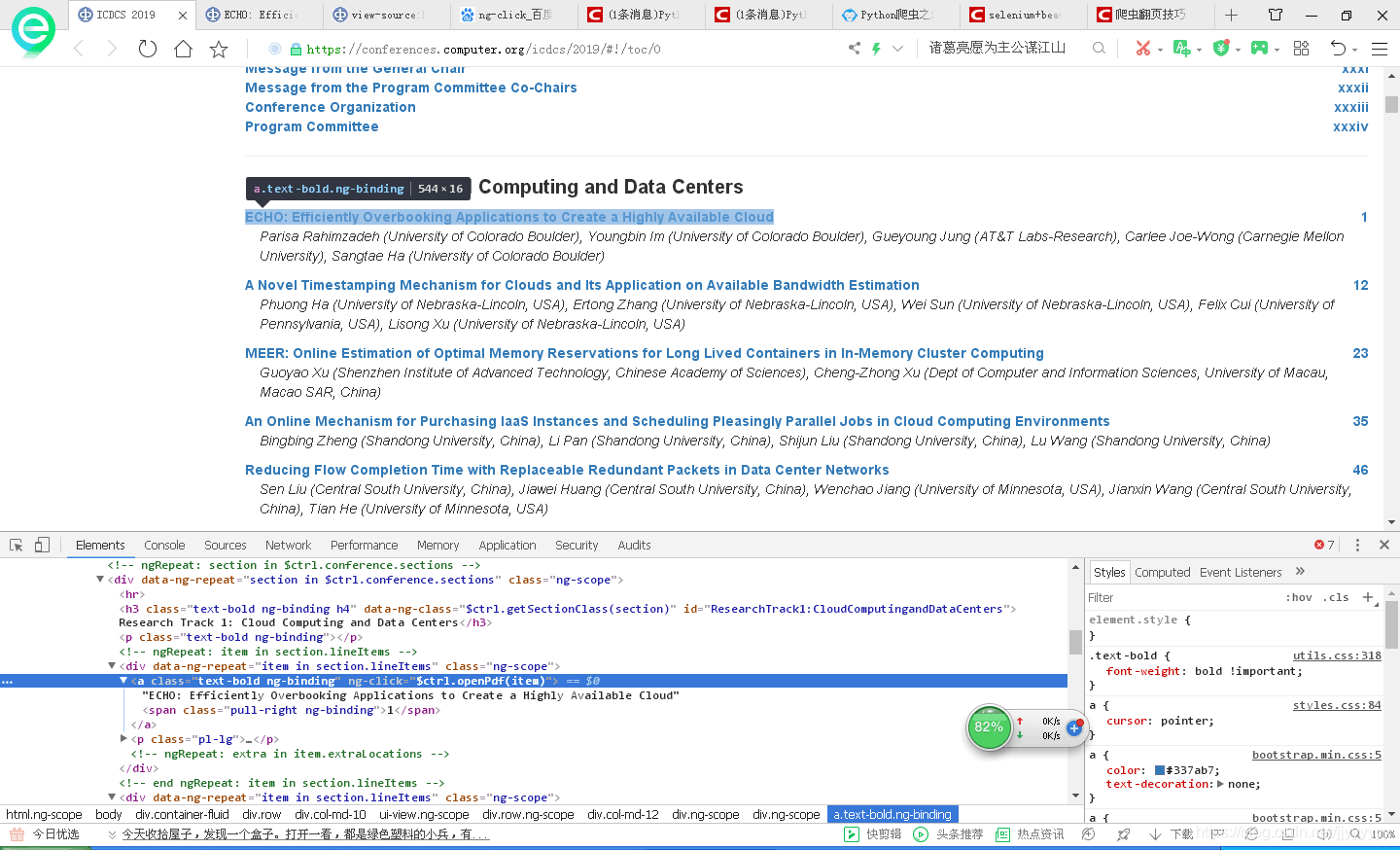
所以捏,技术难点就是采取适合js的方法,获取每一个论文的链接。
首先,感谢CCTV啊不对感谢这位博主给我的大力支持 博客链接 这里面说了种方法就是从审查元素里面的network这个部分切入,其中含了所有的js文件,其中有一个文件叫data.js这里面包含了所有链接,如图——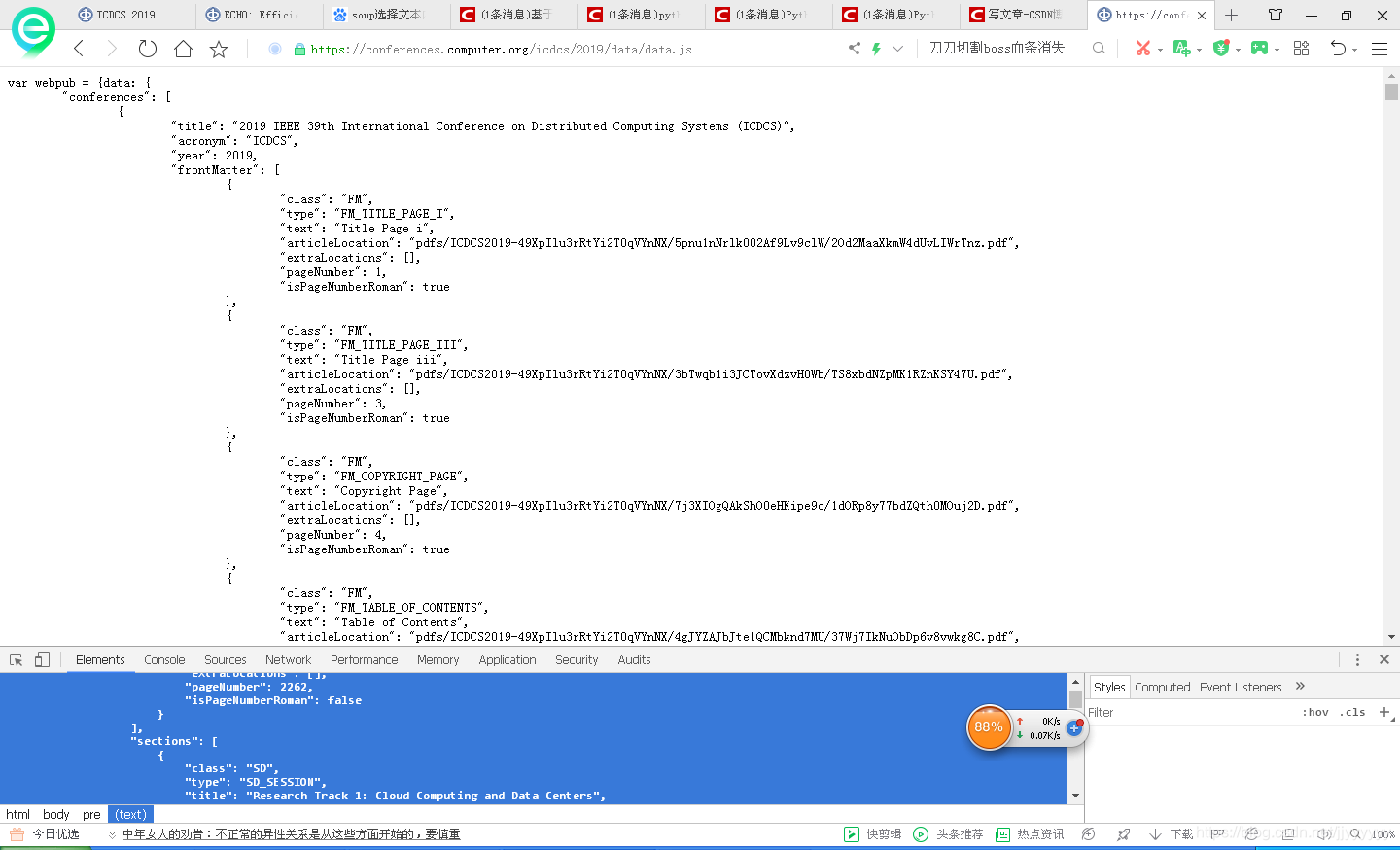
于是,现在的问题变成了如何在这个文件中提取出自己所想要的链接
2.提取论文链接
其实可以观察到,上面那个网页的文本形式和字典类型特别像,so,离成功其实只有一步之遥~老师建议我可以去看看正则表达式或者是find把链接给弄出来,但是这个太长了表达式写起来很麻烦。而今我们所需要解析的网页 https://conferences.computer.org/icdcs/2019/data/data.js 细心会发现这是一个js网页,所以可以试着用解析js的方法去解决,而在这方面,Java似乎很方便—— 第一次尝试所参考的博客 咳咳失败,Java弄起来有点复杂了。
第二次尝试——直接试find_all函数结果…re库的这种方法好像不大支持这种模糊搜索
第三次尝试——字符串匹配,后面怒了,这不就应该是找个字符串的事情吗,然后用C语言提取出来了——
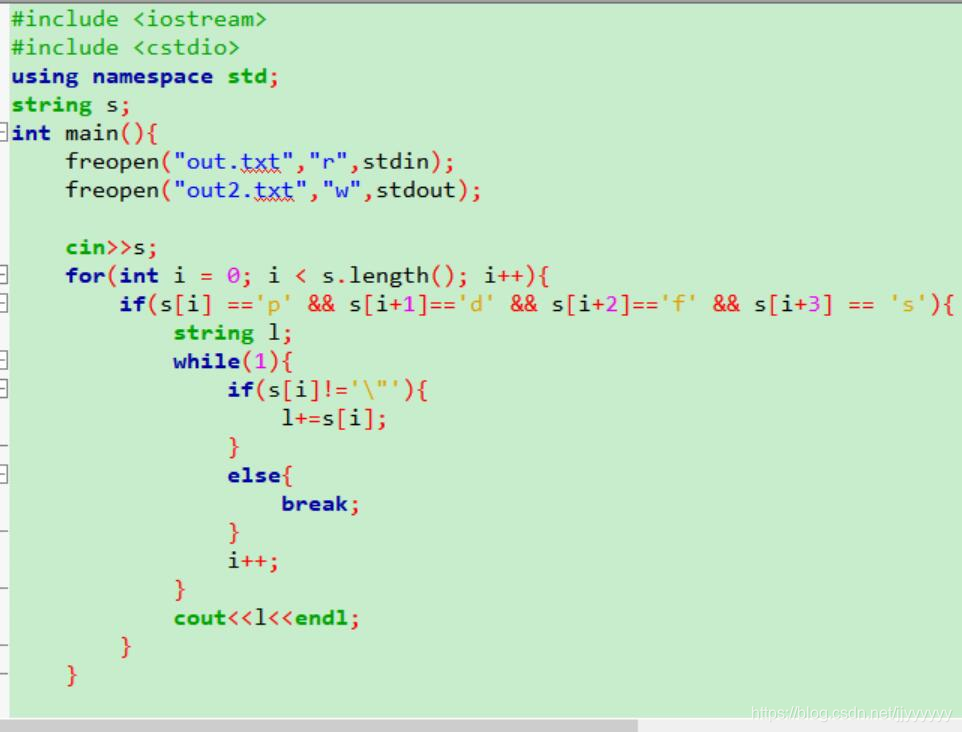
emmm,生活总是这么柳暗花明~
于是就把所有的链接都提取出来了——

3. 爬取网页
最后链接也知道了那么就直接爬取就可以了——
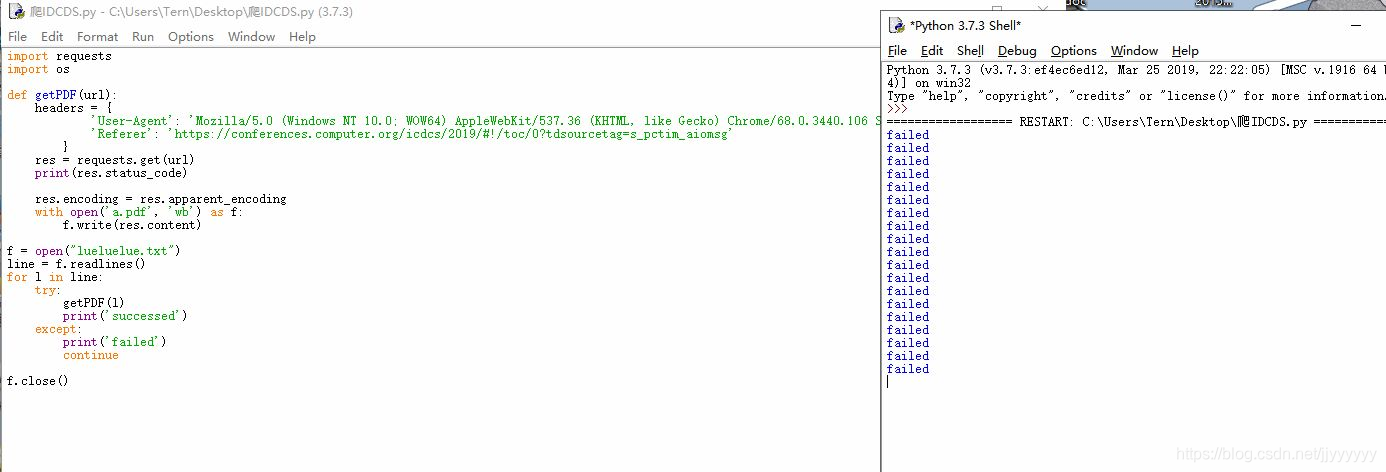
咳咳,不过应该是链接已经失效的原因,爬取的时候一直都是fail了。
这个故事告诉我,js网页是魔鬼啊不对,其实是自己的技术还大大的不过关,平时要多练习!!!

















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









