



 文章详细阐述了MySQL中的索引机制,包括为何使用B+Tree作为主要索引结构,对比了哈希表和其他树型结构的优缺点。讨论了聚簇索引和非聚簇索引的概念,以及回表、索引覆盖和最左匹配原则。此外,还介绍了事务的ACID特性、锁和MVCC多版本并发控制的实现原理。
文章详细阐述了MySQL中的索引机制,包括为何使用B+Tree作为主要索引结构,对比了哈希表和其他树型结构的优缺点。讨论了聚簇索引和非聚簇索引的概念,以及回表、索引覆盖和最左匹配原则。此外,还介绍了事务的ACID特性、锁和MVCC多版本并发控制的实现原理。
Msql高级
索引
索引和世界的数据都是存储在磁盘的,只不过在进行数据读取的时候会优先把索引加载到内存中。
为什么使用B+Tree
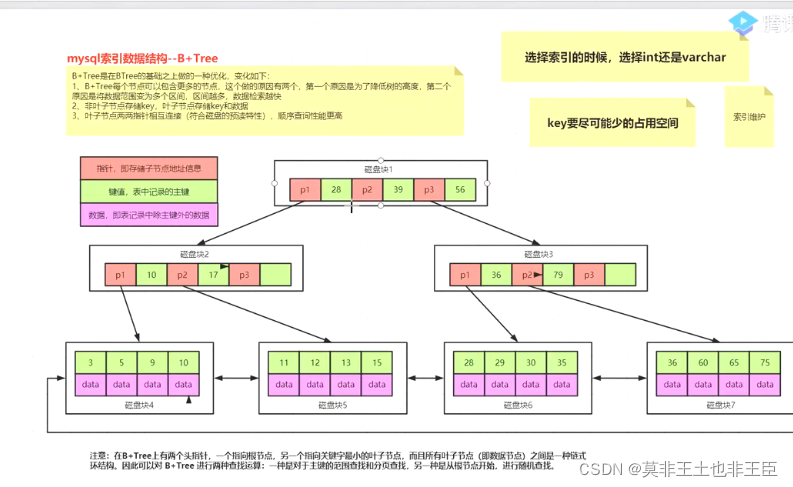
一般情况下3到4层的b+tree足以支撑千万级别的数据量存储。尽可能让k占用少的存储空间
- hash表:需要比较好的hash算法,如果算法不好的话,会导致hash碰撞,hash冲突,导致数据散列不均匀;范围查找效率比较低。
- 二叉树、BST、AVL、红黑树之间都有且尽有两个节点; BST、AVL、红黑树都是有序的; AVL、红黑树都是平衡的。这些树数据量大的时候会导致树变得非常高,加大读取速度,影响效率
select count(*) as cnt,let(city,8) as pref from citydemo group by pref order by cnt desc limit 10;
show index from citydemo; //显示索引
alert table citydemo add key(city(7)); //创建索引
hyperloglog
数据结构
- 设计原则
- 优化
- 失效
回表
表:id\name\age\gender
主键:id
name普通索引
id是聚簇索引,name对应的索引的B+tree上的叶子节点存储的就是id值
select * from table where name='zhangsan'
先根据name B+tree匹配到对应的叶子节点,查询到对应行记录的id值,再根据id去id的B+Tree中检索整行记录,这个过程就称之为回表,要尽量避免回表操作。
索引覆盖
表:id\name\age\gender
主键:id
name普通索引
id是聚簇索引,name对应的索引的B+tree上的叶子节点存储的就是id值
select id,name from table where name='zhangsan'
根据name B+tree匹配到对应的叶子节点,能获取到id的属性值,索引的叶子节点中包含了查询的所有列,此时不需要回表,这个过程叫做索引覆盖,using index 的提示信息推荐使用,在某些场景中可以考虑将要查询的所有列都变成组合索引,会变成索引覆盖,加快查询效率
最左匹配
创建索引的时候可以选择多个列来共同组成索引,此时叫做组合索引或者联合索引,要遵循最左匹配原则
id\name\age\gender
id主键,name,age组合索引
select * from table where name =‘zhangsna’ and age=‘12’
select * from table where name = ‘zhangsan’
select * from table where age=‘12’
select * from table where age=‘12’ and name =‘zhangsna’
索引下推
select * from table where name=‘zhangsan’ and age=‘12’
没有索引下推之前:
先更具name从存储引擎中拉取数据到server层,然后在server层中对age进行数据过滤;
有了索引下推以后:
根据name和age两个条件来做数据筛选,将筛选之后的结果返回给server层
聚簇索引
聚簇索引和非聚簇索引
数据跟索引存储在一起的叫做聚簇索引,没有存储在一起的叫非聚簇索引
innodb存储引擎在进行数据插入的时候,数据必须要跟耨一个索引列存储在一起,这个索引列可以是主键,如果没有主键,选择唯一键,如果没有唯一键,选择6字节的rowid来进行存储。
innodb中既有聚簇索引也有非聚簇索引
myisam是非聚簇索引
事务
ACID四个特性原理,
锁
mvcc 多版本控制
为了解决并发读写效率,
当前读:读取的是数据的最新版本总是读取到最新版本;select …lock in share mode;select …from update;delete,inert
快照读:读取的是历史版本的记录;select…
隔离级别:读未提交;读已提交(RC);可重复读(RR默认隔离级别);串行化
RC:可以读取最新结果
RR:不可以读取到最新记录结果
MVCC实现原理
- 隐藏字段:每一行记录都包含几个用户看不见的字段;DB_TRX_ID(创建或修改最后一次修改改记录的事务id);DB_ROW_ID(隐藏主键);DB_ROW_PTR(回滚指针)配合undolog使用
- undolog:回滚日志,保存的是历史数据版本。
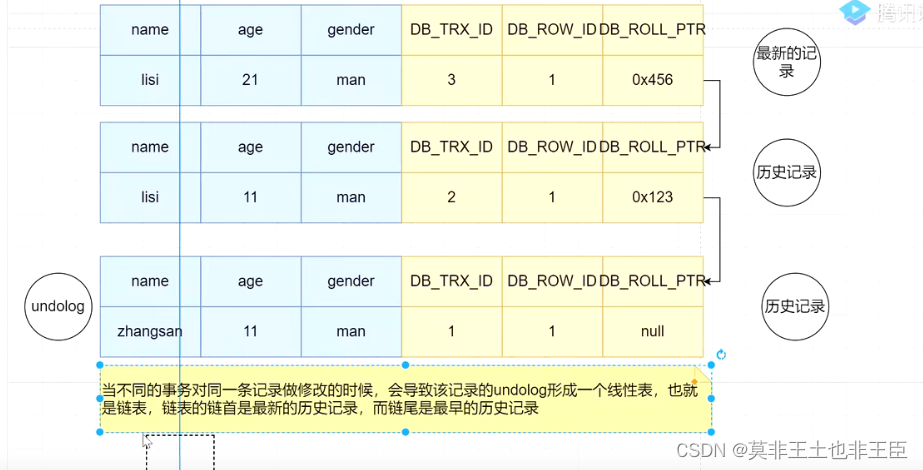
- readview快照读:事务在未经快照读取的时候产生的读视图。trx_list:系统活跃的事务id;up_limit_id:列表中事务最小的id;low_limit_id:系统尚未分配的下一个事务id。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









