




 本文深入探讨Hadoop的I/O操作,包括数据完整性的检验和修复,如HDFS的校验和机制,以及LocalFileSystem和ChecksumFileSystem的使用。此外,讨论了压缩的优势,如减少存储空间和加速传输,强调了可切分压缩格式在MapReduce中的重要性,并介绍了Hadoop中的不同压缩Codec,如bzip2和LZO。文章还涵盖了在MapReduce作业中使用压缩的配置方法。最后,文章提及序列化的重要性,特别是Writable接口及其在进程间通信和永久存储中的应用。
本文深入探讨Hadoop的I/O操作,包括数据完整性的检验和修复,如HDFS的校验和机制,以及LocalFileSystem和ChecksumFileSystem的使用。此外,讨论了压缩的优势,如减少存储空间和加速传输,强调了可切分压缩格式在MapReduce中的重要性,并介绍了Hadoop中的不同压缩Codec,如bzip2和LZO。文章还涵盖了在MapReduce作业中使用压缩的配置方法。最后,文章提及序列化的重要性,特别是Writable接口及其在进程间通信和永久存储中的应用。
第五章 Hadoop的I/O操作
- 数据完整性
检测数据是否损坏的常见措施是在数据第一次引入系统时计算检验和并在数据通过一个不可靠的通道进行传输时,再次计算检验和,这样就能发现数据是否损坏。
⓵HDFS的数据完整性
HDFS会对写入的所有数据计算检验和,并在读取数据时验证检验和。HDFS存储着每个数据块的复本,因此它可以通过数据复本来修复损坏的数据块,进而得到一个新的、完好无损的复本。
⓶LocalFileSystem
Hadoop的LocalFileSystem执行客户端的检验和验证。我们也可以仅用校验和计算,特别是在底层文件系统本身就支持校验和的时候。如果想针对一些读操作禁用校验和,这个方案非常有用。FileSystem fs = new RawLocalFileSystem();
⓷ChecksumFileSystem
LocalFileSystem通过ChecksumFileSystem来完成自己的任务,有了这个类,向其他无校验和系统加入校验和就非常简单。
FileSystem rawFs = ...
FileSystem checksumdFs = new ChecksumFileSystem(rawFs);
- 压缩
文件压缩有两大好处:减少存储文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输。可切分压缩格式尤其适合MapReduce。bzip2可以切分,LZO文件已经在预处理过程被索引了,那么LZO文件是可切分的。
⓵Codec
Codec是压缩——解压缩算法的一种实现。一个CompressionCodec接口的实现代表一个Codec。
➊通过CompressionCodec对数据流进行压缩和解压缩。如果要对写入输出数据流的数据进行压缩,可用createOutputStream(OutputStream out),新建一个CompressionOutputStream对象。对输入数据流中读取的数据进行解压缩的时候,则调用createInputStream(InputStream in)获取CompressionInputStream。CompressionOutputStream和CompressionInputStream能够重制其底层的压缩或解压缩方法,对于某些将部分数据流压缩为单独数据块的应用,这个能力是非常重要的。
➋通过CompressionCodecFactory推断CompressionCodec:通过使用其getCodec()方法,CompressionCodecFactory提供了一种可以将文件扩展名映射到一个CompressionCodec方法,该方法取文件的Path对象作为参数。
➌原生类库:为了提高性能,最好使用“原生”类库来实现压缩和解压缩。
➍CodecPool:如果使用的是原生代码库并且需要在应用中执行大量压缩和解压缩操作,可以考虑使用CodecPool。
⓶压缩和输入分片:在考虑如何压缩将由MapReduce处理的数据时,理解这些压缩格式是否支持切分是非常重要的。
⓷在MapReduce中使用压缩
要想压缩MapReduce作业的输出,应在作业配置过程中将mapreduce.output.fileoutputformat.compress属性设为true,将mapreduce.output.fileoutputformat.compress.codec属性设置为打算使用的压缩codec的类名。
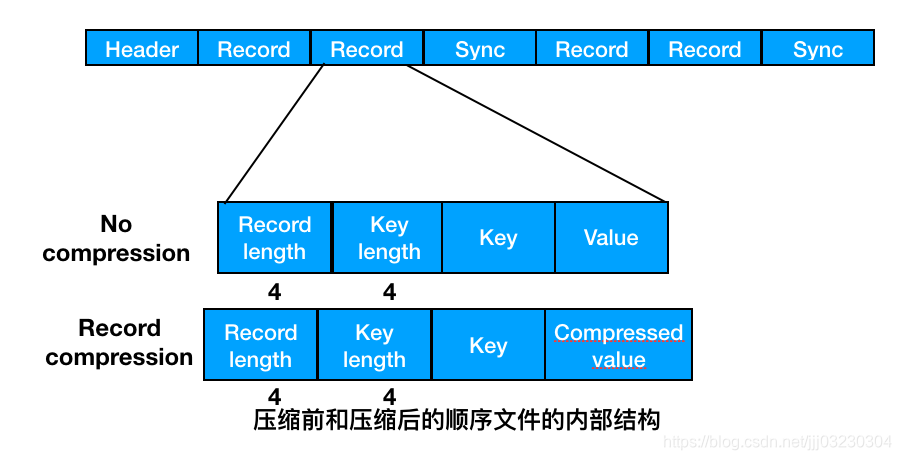
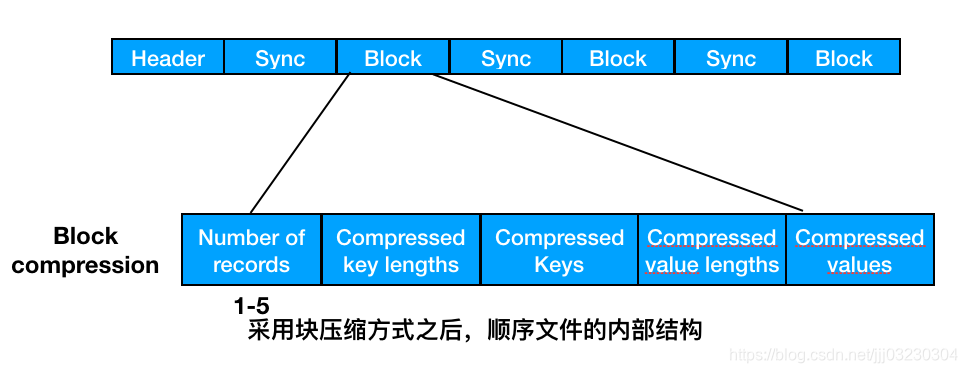
如果为输出生成顺序文件,可以设置mapreduce.output.fileoutputformat.compress.type属性来控制限制使用压缩格式。默认值是RECORD,即针对每条记录进行压缩。如果将其改为BLOCK,将针对一组记录进行压缩,这是推荐的压缩策略,因为它的压缩效率更高。由于map任务的输出需要写到磁盘并通过网络传输到reduce节点,所以通过使用LZO、LZ4或者Snappy这样的快速压缩方式,是可以获得性能提升的。
- 序列化
序列化是指将结构化对象转化为字节流以便在网络上传输或写到磁盘进行永久存储的过程。反序列化是指将字节流转回结构化对象的逆过程。序列化用于分布式数据处理的两大领域:进程间通信和永久存储。Hadoop使用的是自己的序列化Writable,它绝对紧凑速度快,但不容易用Java以外的语言进行扩展或使用。
⓵Writable接口
Writable接口定义了两个方法:一个将其状态写入DataOutput二进制流,另一个从DataInput二进制流读取状态。
writable.write(dataOutputStream);
writable.readFields(dataInputStream);
➊WritableComparable接口和Comparator:
IntWritable实现原始的WritableComparable接口,该接口继承自org.apache.hadoop.io.Writable接口和java.lang.Comparable接口。
public interface WritableComparable<T> extends Writable,Comparable<T>{}
对MapReduce来说,类型比较非常重要,因为中间有个基于键的排序阶段。
Hadoop提供的一个优化接口是继承自Java Comparator的RawComparator接口。该接口允许其实现直接比较数据流中的记录,无需先把数据流反序列化为对象,这样便避免了新建对象的额外开销。
⓶Writable类
➊Java基本类型的Writable封装器:对整数进行编码时,有两种选择,即定长格式和变长格式(IntWritable、VIntWritable)。定长格式编码很适合数值在整个值域空间中分布非常均匀的情况,例如使用精心设计的哈希函数。然而,大多数数值变量的分布都不均匀,一般而言变长格式会更节省空间。
➋Text类型:Text是针对UTF-8序列的Writable类。
➀索引:由于着重使用标准的UTF-8编码,因此Text类和Java String类之间存在一定的差别。对Text类的索引是根据编码后字节序列中的位置实现的,并非字符串中的Unicode字符,也不是Java Char的编码单元(如String)。对于ASCII字符串,这三个索引位置的概念是一致的。
➁Unicode:
➂迭代:将Text对象转换为java.nio.ByteBuffer对象,然后利用缓冲区对Text对象反复调用bytesToCodePoint()静态方法。该方法能够获取下一代码的位置。当bytesToCodePoint()返回-1时,则检测到字符串的末尾。
public class TextIterator{
public static void main(String[] args){
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
ByteBuffer buf = ByteBuffer.wrap(t.getBytes(),0,t.getLength());
int cp;
while(buf.hasRemaining()&&(cp = Text.bytesToCodePoint(buf))!=-1){
System.out.println(Integer.toHexString(cp));
}
}
}
//运行这个程序,打印出字符串中四个字符的编码点(code point):
% hadoop TextIterator
41
df
6771
10400
➃可变性:与String相比,Text的另一个区别在于它是可变的(与所有Hadoop的Writable实现相似,NullWritable除外,它是单实例对象)。可以通过调用其中一个set()方法来重用Text实例。例如:
Text t = new Text("hadoop");
t.set("pig");
assertThat(t.getLength(),is(3));
assertThat(t.getBytes().length,is(3));
//在某些情况下,getBytes()方法返回的字节数组可能比getLength()函数返回的长度更长,
//以上代码说明了在调用getBytes()之前为什么始终都要调用getLength()方法,
//因为可以由此知道字节数组中多少字符是有效的。
➄对String重新排序:Text类并不像java.lang.String类那样有丰富的字符串操作API。所以,在多数情况下需要将Text对象转换成String对象。这一转换通常通过调用toString()方法来实现:
assertThat(new Text("hadoop").toString(),is("hadoop"));
➌BytesWritable:BytesWritable是对二进制数据数组的封装。它的序列化格式为一个指定所含数据字节数的整数域(4字节),后跟数据内容本身。
BytesWritable b = new BytesWritable(new byte[]{3,5});
byte[] bytes = serialize(b);
assertThat(StringUtils.byteHexString(bytes),is("000000020305"));
//BytesWritable是可变的,其值可以通过set()方法进行修改。和Text相似
//BytesWritable类的getBytes()方法返回的字节数数组长度(容量)可能无法体现
//BytesWritable所存储数据的实际大小。可以通过getLength()方法来确定BytesWritable大小。
b.setCapacity(11);
assertThat(b.getLength(),is(2));
assertThat(b.getBytes().length,is(11));
➍NullWritable:NullWritable是Writable的特殊类型,它的序列化长度为0.它并不从数据流中读取数据,也不写入数据。它充当占位符。NullWritable也可以用作在SequenceFile中的键。它是一个不可变的单实例类型,通过调用NullWritable.get()方法可以获取这个实例。
➎ObjectWritable和GenericWritable:ObjectWritable是对Java基本类型的一个通用封装。它在Hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。当一个字段中包含多个类型时,ObjectWritable非常有用。如果封装的类型数量比较少并且能够提前知道,那么可以通过使用静态类型的数组,并使用对序列化后的类型的引用加入位置索引来提高性能。GenericWritable类采取的就是这种方式,所以你得在继承的子类中指定支持什么类型。
➏Writable集合类:org.apache.hadoop.io软件包中共有6个Writable集合类,分别是ArrayWritable、ArrayPrimitiveWritable、TwoDArrayWritable、MapWritable、SortedMapWritable以及EnumMapWritable。ArrayWritable和TwoDArrayWritable是对Writable的数组和二维数组的实现。ArrayWritable或TwoDArrayWritable中所有的元素必须是同一类的实例(在构造函数中指定),如下所示:
ArrayWritable writable = new ArrayWritable(Text.class);
如果Writable根据类型来定义,例如SequenceFile的键和值,或更多时候作为MapReduce的输入,则需要继承ArrayWritable并设置静态类型:
public class TextArrayWritable extends ArrayWritable{
public TextArrayWritable(){
super(Text.class);
}
}
ArrayPrimitiveWritable是对Java基本数组类型的一个封装。MapWritable和SortedMapWritable分别实现了java.util.Map<Writable,Writable>和java.util.SortedMap<WritableComparable,Writable>。对于单类型的Writable列表,使用ArrayWritable就足够了,但如果需要把不同的Writable类型存储在单个列表中,可以用GenericWritable将元素封装在一个ArrayWritable中。另一个可选方案是,可以借鉴MapWritable的思路写一个通用的ListWritable。
⓷实现定制的Writable集合
有了定制的Writable类型,就可以完全控制二进制表示和排序顺序。由于Writable是MapReduce数据路径的核心,所以调整二进制表示能对性能产生显著效果。
➊位提高速度实现一个RawComparator
➋定制的Comparator
⓸序列化框架:可以使用任何类型,只要能有一种机制对每个类型进行类型二进制表示的来回转换就可以。
- 基于文件的数据结构
⓵关于SequenceFile:纯文本不适合记录二进制类型的数据。在这种情况下,Hadoop的SequenceFile类非常适合,为二进制
键值对提供了一个持久数据结构。SequenceFile也可以作为小文件的容器。HDFS和MapReduce是针对大文件优化的,所以通过SequenceFile类型将小文件包装起来,可以获得更高效率的存储和处理。
➊SequenceFile的写操作
通过createWriter()静态方法可以创建SequenceFile对象,并返回SequenceFile.writer实例。存储在SequenceFile中的键值并不一定需要是Writable类型。只要能被Serialization序列化和反序列化,任何类型都可以。一旦拥有SequenceFile.writer实例,就可以通过append()方法在文件末尾附加键值对。写完后,可以调用close()方法。
➋SequenceFile的读操作
从头到尾读取顺序文件不外乎创建SequenceFile.Reader实例后反复调用next()方法迭代读取记录。读取的是哪条记录与你使用的序列化框架相关。如果使用的是Writable类型,那么通过键值作为参数的next()方法可以将数据流中的下一条键值对读入变量中:
public boolean next(Writable key,Writable value);
所谓同步点,是指数据读取迷路后能够再一次读取与记录边界同步的数据流中的某个位置,例如,在数据流中由于搜索而跑到任意位置后可采取此动作。同步点是由SequenceFile.Writer记录的,后者在顺序文件写入过程中插入一个特殊项以便每隔几条记录便有一个同步标识。同步点始终位于记录的边界处。在顺序文件中搜索给定位置有两种方法。第一种是调用seek()方法,该方法将读指针指向文件中指定的位置。第二种方法通过同步点查找记录边界。SequenceFile.Reader对象的sync()方法可以将读取位置定位到position之后的下一个同步点。如果position之后没有同步了,那么当前读取位置将指向文件末尾。这样,我们对数据流中的任意位置调用sync()方法(不一定是一个记录的边界)而且可以重新定位下一个同步点并继续向后读取。SequenceFile.Writable对象有一个sync()方法,该方法可以在数据流的当前位置插入一个同步点。
⓶关于MapFile
MapFile是已经排过序的SequenceFile,它有索引,所以可以按键查找。MapFile提供了一个用于读写的与SequenceFile非常类似的接口。当使用MapFile.Writer进行写操作时,map条目必须顺序添加,否则会抛出IOException异常。
➊MapFile的变种
➀SetFile:是一个特殊的MapFile,用于存储Writable键的集合。键必须按照排好的顺序添加。
➁ArrayFile:ArrayFile的键是一个整型,用于表示数组中元素的索引,而值是一个Writable值。
➂BloomMapFile:提供了get()方法的一个高性能实现,对稀疏文件特别有用。
⓷其他文件格式和面向列的格式
一般来说,面向列的存储格式对于那些只访问表中一小部分列的查询比较有效。相反,面向行的存储格式适合同时处理一行中很多列的情况。面向列的格式不适合流的写操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









