




 本文详细探讨了为何需要分布式锁及其特点,重点介绍了使用MySQL和Redis实现分布式锁的方法,包括MySQL的lock()、tryLock()、unlock()以及Redis的setnx和Redission实现。分析了两者的优缺点,指出MySQL实现较为繁琐,Redis性能较好,且可通过RedLock提高可靠性。
本文详细探讨了为何需要分布式锁及其特点,重点介绍了使用MySQL和Redis实现分布式锁的方法,包括MySQL的lock()、tryLock()、unlock()以及Redis的setnx和Redission实现。分析了两者的优缺点,指出MySQL实现较为繁琐,Redis性能较好,且可通过RedLock提高可靠性。
MySQL和Redis实现分布式锁
在Java中synchronized关键字和ReentrantLock可重入锁在我们的代码中是经常见的,一般我们用其在多线程环境中控制对资源的并发访问,但是随着分布式的快速发展,本地的加锁往往不能满足我们的需要,在我们的分布式环境中上面加锁的方法就会失去作用。
1. 为何需要分布式锁
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
2. 分布式锁的一些特点
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件: 1互斥性。在任意时刻,只有一个客户端能持有锁。 2不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。 3具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。 4解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
3. 常见的分布式锁
我们了解了一些特点之后,我们一般实现分布式锁有以下几个方式:
- MySql
- Zk
- Redis
- 自研分布式锁:如谷歌的Chubby。
下面介绍一下使用MySQL和Redis实现的分布式锁。
4. Mysql实现分布式锁
首先来说一下Mysql分布式锁的实现原理,相对来说这个比较容易理解,毕竟数据库和我们开发人员在平时的开发中息息相关。对于分布式锁我们可以创建一个锁表:
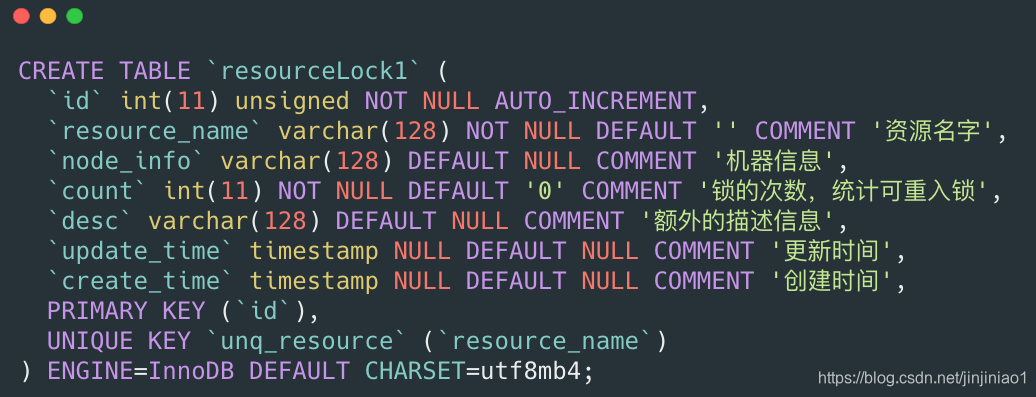
前面我们所说的lock(),trylock(long timeout),trylock()这几个方法可以用下面的伪代码实现。
4.1 lock()
lock一般是阻塞式的获
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









