




 本文深入探讨C语言的关键特性,包括const、volatile关键字的作用与应用场景,全局变量、静态变量与局部变量的区别及其内存布局,以及常见排序算法的实现原理。同时介绍了时间复杂度与空间复杂度的概念,并对类型转换和指针的高级用法进行了详细解析。
本文深入探讨C语言的关键特性,包括const、volatile关键字的作用与应用场景,全局变量、静态变量与局部变量的区别及其内存布局,以及常见排序算法的实现原理。同时介绍了时间复杂度与空间复杂度的概念,并对类型转换和指针的高级用法进行了详细解析。
1. const
它限定一个变量不允许被改变。使用const在一定程度上可以提高程序的安全性和可靠性。
const int a; // a 代表一个常整型数
int const a; // a 代表一个常整型数
const int *a; // a 代表一个指向常整型数的指针,即a的值是可变的,但是*a是不能变的,函数的一些形参经常会用到
int * const a; // a 代表一个常指针,即a的值是不可变的,但是*a是可变的
int const * a const; // a代表的是一个指向常整型数的常指针
主要看const修饰的是什么?
1)const + 类型
说明const修饰的是类型,想让类型为常量,也就是这个类型的值为常量。
例如const int *a; 本来是定义一个指针变量,指针变量所指向的值为int类型。const修饰int 类型,那也就是说这个int 类型的值为常量,也就是说指针指向的值为常量。
2)const + 变量
说明const修改的变量,想让这个变量为常量。
例如int *const a; 本来是定义一个指针变量,指针变量所指向的值为int 类型。const修饰变量,那就是说这个指针变量为常量,不可变。指针所指向的int类型的值是可变的。
详细的可以查看 这里
2. volatile
由于内存访问速度远不及CPU处理速度,为提高机器整体性能,
1)在硬件上: 引入硬件高速缓存Cache,加速对内存的访问。另外在现代CPU中指令的执行并不一定严格按照顺序执行,没有相关性的指令可以乱序执行,以充分利用CPU的指令流水线,提高执行速度。
2)软件一级的优化:一种是在编写代码时由程序员优化,另一种是由编译器进行优化。编译器优化常用的方法有:将内存变量缓存到寄存器。
由于访问寄存器要比访问内存单元快的多,编译器在存取变量时,为提高存取速度,编译器优化有时会先把变量读取到一个寄存器中;以后再取变量值时就直接从寄存器中取值。但在很多情况下会读取到脏数据,严重影响程序的运行效果。
C语言书籍这样定义volatile关键字:volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,告诉编译器对该变量不做优化,都会直接从变量内存地址中读取数据,从而可以提供对特殊地址的稳定访问。
如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)
一般说来,volatile用在如下的几个地方:
1) 中断服务程序中修改的供其它程序检测的变量,需要加volatile;
当变量在触发某中断程序中修改,而编译器判断主函数里面没有修改该变量,因此可能只执行一次从内存到某寄存器的读操作,而后每次只会从该寄存器中读取变量副本,使得中断程序的操作被短路。
2) 多任务环境下各任务间共享的标志,应该加volatile;
在本次线程内, 当读取一个变量时,编译器优化时有时会先把变量读取到一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当内存变量或寄存器变量在因别的线程等而改变了值,该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致 。
3) 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
假设要对一个设备进行初始化,此设备的某一个寄存器为0xff800000。for(i=0;i< 10;i++) *output = i;前面循环半天都是废话,对最后的结果毫无影响,因为最终只是将output这个指针赋值为9,省略了对该硬件IO端口反复读的操作。
gcc -O0 -O1 -O2 -O3 四级优化选项及每级分别做什么优化
3. 全局变量、静态变量、局部变量
g++ 环境:
g++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
带着问题了解下上述变量:
- 全局变量和静态变量分别在内存哪个区域?已初始化和未初始化有区别吗?
- 全局变量和静态变量初始化为0是不是就在__data段中了?
- 局部变量在内存哪个区域?已初始化和未初始化有区别吗?
- 全局变量、静态变量和局部变量的默认值都是0吗?
- const修饰的变量在内存中位置会有不同吗?
源码如下:
#include <unistd.h>
int global_init_a = 1;
char global_init_b = 'a';
int global_uninit_a;
char global_uninit_b;
int global_init_c = 0;
const int global_init_d = 1;
const int global_init_e = 0;
static int static_init_a = 1;
static int static_uninit_a;
static int static_init_b = 0;
const static int static_init_d = 1;
const static int static_init_e = 0;
int main(){
static int local_static_init_a = 2;
static char local_static_init_b = 'b';
static int local_static_init_c = 0;
static int local_static_uninit_a;
static char local_static_uninit_b;
const static int static_init_d = 1;
const static int static_init_e = 0;
int local_init_c = 1;
int local_uninit_c;
int local_init_d = 0;
return 0;
}编译后来看下符号表:
test.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 test.cpp
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l d .rodata 0000000000000000 .rodata
0000000000000000 l O .rodata 0000000000000004 _ZL13global_init_d
0000000000000004 l O .rodata 0000000000000004 _ZL13global_init_e
0000000000000008 l O .data 0000000000000004 _ZL13static_init_a
000000000000000c l O .bss 0000000000000004 _ZL15static_uninit_a
0000000000000010 l O .bss 0000000000000004 _ZL13static_init_b
0000000000000008 l O .rodata 0000000000000004 _ZL13static_init_d
000000000000000c l O .rodata 0000000000000004 _ZL13static_init_e
000000000000000c l O .data 0000000000000004 _ZZ4mainE19local_static_init_a
0000000000000010 l O .data 0000000000000001 _ZZ4mainE19local_static_init_b
0000000000000014 l O .bss 0000000000000004 _ZZ4mainE19local_static_init_c
0000000000000018 l O .bss 0000000000000004 _ZZ4mainE21local_static_uninit_a
000000000000001c l O .bss 0000000000000001 _ZZ4mainE21local_static_uninit_b
0000000000000010 l O .rodata 0000000000000004 _ZZ4mainE13static_init_d
0000000000000014 l O .rodata 0000000000000004 _ZZ4mainE13static_init_e
0000000000000000 l d .debug_info 0000000000000000 .debug_info
0000000000000000 l d .debug_abbrev 0000000000000000 .debug_abbrev
0000000000000000 l d .debug_aranges 0000000000000000 .debug_aranges
0000000000000000 l d .debug_line 0000000000000000 .debug_line
0000000000000000 l d .debug_str 0000000000000000 .debug_str
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
0000000000000000 g O .data 0000000000000004 global_init_a
0000000000000004 g O .data 0000000000000001 global_init_b
0000000000000000 g O .bss 0000000000000004 global_uninit_a
0000000000000004 g O .bss 0000000000000001 global_uninit_b
0000000000000008 g O .bss 0000000000000004 global_init_c
0000000000000000 g F .text 0000000000000019 main
这里再来回答上面的问题:
Q1. 全局变量和静态变量分别在内存哪个区域?已初始化和未初始化有区别吗?
全局变量和静态变量初始化和非初始化的变量是在不同的字段中,例如 .data .bss .rodata段。
初始化的变量位于.data 段(初始化为0 在.bss 段,看Q2解释),未初始化的变量位于 .bss 段。
Q2. 全局变量和静态变量初始化为0是不是就在__data段中了?
不在,如 Q1中解释,初始化为0 的变量位于 .bss 段。
Q3. 局部变量在内存哪个区域?已初始化和未初始化有区别吗?
局部静态变量同全局静态变量。
局部临时变量不管是否初始化,应该位于栈中。
Q4. 全局变量、静态变量和局部变量的默认值都是0吗?
全局变量、静态变量的默认值为0,局部变量默认值不确定。
为什么全局变量和静态变量默认值是0,而局部变量不确定?其实很容易理解。全局变量和静态变量存储在bss 段,装载时内存地址已知,填充 0 开销不太大,且全局变量和静态变量作用于整个程序生命周期,对其进行初始化也是有价值的。反观局部变量,局部变量数量众多,生命周期短,存储在栈中且内存地址不能事先确定,如果每次都对局部变量填充 0 初始化,不仅消耗资源,且收益较小,得不偿失。
Q5.const修饰的变量在内存中位置会有不同吗?
const 修饰的变量位于 .rodata 段。
4. 排序
排序方式最常用的有:冒泡排序、直接插入排序、选择排序、快速排序、希尔排序,当然还有堆排序、归并排序等
这里我总结一下算法,实例在另一篇博文总结:
排序都以从小到大排序,数组长度为n:
4.1 冒泡排序
冒泡顾名思义就是要冒出来,相邻的两个元素进行比较,找到小的那个元素,让它冒出来,大的那个元素则沉下去,一直比较到最后将最大的那个元素放到第n个元素的位置;
然后继续上面步骤,找到第2个最大的数,放到n-1个元素的位置;
以此类推,一直到最后一个元素,当然最后一个元素肯定就是最小的,也是放到第1个元素所在的位置。
冒泡排序是稳定的,时间复杂度是n的平方(O(n2))。
4.2 快速排序
快速排序是对冒泡排序的一种本质改进;它的基本思想是通过一趟扫描后,使得排序序列的长度能大幅度地减少。在冒泡排序中,一次扫描只能确保最大数值的数移到正确位
置,而待排序序列的长度可能只减少1;
快速排序通过一趟扫描,就能确保某个数(基准值,通常我们选第一个)的左边各数都比它小,右边各数都比它大。然后又用同样的方法(递归)处理它左右两边的数,直到基
准点的左右只有一个元素为止;
最理想情况算法时间复杂度O(nlog2n),最坏O(n2)
4.3 选择排序
从第2个元素开始,分别与第一个元素比较,如果比第一个元素小,那么就交换,这样得到的第一个元素应该是最小的;
重复上一步,从第3个元素开始,分别与第2个元素比较,如果比第一个元素小,那么就交换,这样得到的第2个元素应该是最小的;
以此类推。
选择排序是不稳定的,时间复杂度是n的平方(O(n2))
4.4 直接插入排序
一般不明确前面顺序的话,就从第2个元素开始插入;
插入的时候,后面的元素就需要后移,所以,目前元素是j,那么就需要与j-1比较,如果比j-1小,就交换。也就是说插入到j-1的位置,原来j-1位置的元素就后移到j的位置;
重复上面步骤,一直到j元素的值不比j-1小;
然后再将j+1元素往直前j个元素里面插;
重复将j+2元素往里面插,一直到第n个元素。
直接插入排序也是稳定的,时间复杂度是n的平方(O(n2))
4.5 希尔排序
在直接插入排序算法中,每次插入一个数,使有序序列只增加1个节点,并且对插入下一个数没有提供任何帮助。如果比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比较就可能消除多个元素交换。D.L.shell于1959年在以他名字命名的排序算法中实现了这一思想。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
5. 时间复杂度和空间复杂度
算法(Algorithm)是指用来操作数据、解决程序问题的一组方法。对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,但在过程中消耗的资源和时间却会有很大的区别。
- 时间维度:是指执行当前算法所消耗的时间,我们通常用「时间复杂度」来描述。
- 空间维度:是指执行当前算法需要占用多少内存空间,我们通常用「空间复杂度」来描述。
5.1 时间复杂度
在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。
相同大小的不同输入值仍可能造成算法的运行时间不同,因此我们通常使用算法的最坏情况复杂度,记为T(n),定义为任何大小的输入n所需的最大运行时间。
时间复杂度的公式是: T(n) = O( f(n) ),其中f(n) 表示每行代码执行次数之和,而 O 表示正比例关系,这个公式的全称是:算法的渐进时间复杂度。
for(i=1; i<=n; ++i)
{
j = i;
j++;
}上面的例子,假设每行代码的执行时间都是一样的,我们用 1颗粒时间 来表示,那么这个例子的第一行耗时是1个颗粒时间,第三行的执行时间是 n个颗粒时间,第四行的执行时间也是 n个颗粒时间(第二行和第五行是符号,暂时忽略),那么总时间就是 1颗粒时间 + n颗粒时间 + n颗粒时间 ,即 (1+2n)个颗粒时间,即: T(n) = (1+2n)*颗粒时间,从这个结果可以看出,这个算法的耗时是随着n的变化而变化,因此,我们可以简化的将这个算法的时间复杂度表示为:T(n) = O(n)
常见的时间复杂度量级有:更多的参考百度
- 常数阶O(1)
- 对数阶O(logN)
- 线性阶O(n)
- 线性对数阶O(nlogN)
- 平方阶O(n²)
- 立方阶O(n³)
- K次方阶O(n^k)
- 指数阶(2^n)
5.1.1 常数阶 O(1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是O(1),如:
int i = 1;
int j = 2;
++i;
j++;
int m = i + j;上述代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用O(1)来表示它的时间复杂度。
5.1.2 线性阶O(n)
for(i=1; i<=n; ++i)
{
j = i;
j++;
}for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度。
5.1.3 对数阶O(logN)
int i = 1;
while(i<n)
{
i = i * 2;
}在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。我们试着求解一下,假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 
也就是说当循环  次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(logn)
次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(logn)
5.1.4 线性对数阶O(nlogN)
for(m=1; m<n; m++)
{
i = 1;
while(i<n)
{
i = i * 2;
}
}线性对数阶O(nlogN) 其实非常容易理解,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)。
5.1.5 平方阶O(n²)
for(x=1; i<=n; x++)
{
for(i=1; i<=n; i++)
{
j = i;
j++;
}
}这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(n*n),即 O(n²)
如果将其中一层循环的n改成m,即:
for(x=1; i<=m; x++)
{
for(i=1; i<=n; i++)
{
j = i;
j++;
}
}数据结构的复杂度:
| 数据结构 | 连接 | 查找 | 插入 | 删除 |
|---|---|---|---|---|
| 数组 | 1 | n | n | n |
| 栈 | n | n | 1 | 1 |
| 队列 | n | n | 1 | 1 |
| 链表 | n | n | 1 | 1 |
| 哈希表 | - | n | n | n |
| 二分查找树 | n | n | n | n |
| B树 | log(n) | log(n) | log(n) | log(n) |
| 红黑树 | log(n) | log(n) | log(n) | log(n) |
| AVL树 | log(n) | log(n) | log(n) | log(n) |
数组排序的复杂度:
| 名称 | 最优 | 平均 | 最坏 | 内存 | 稳定 |
|---|---|---|---|---|---|
| 冒泡排序 | n | n^2 | n^2 | 1 | Yes |
| 插入排序 | n | n^2 | n^2 | 1 | Yes |
| 选择排序 | n^2 | n^2 | n^2 | 1 | No |
| 堆排序 | n log(n) | n log(n) | n log(n) | 1 | No |
| 归并排序 | n log(n) | n log(n) | n log(n) | n | Yes |
| 快速排序 | n log(n) | n log(n) | n^2 | log(n) | No |
| 希尔排序 | n log(n) | 取决于差距序列 | n (log(n))^2 | 1 | No |
5.2 空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。比如直接插入排序的时间复杂度是O(n^2),空间复杂度是O(1) 。而一般的递归算法就要有O(n)的空间复杂度了,因为每次递归都要存储返回信息。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量。
常见的空间复杂度量级有:O(1)、O(n)、O(n²)
5.2.1 O(1)
如果算法执行所需要的临时空间不随着某个变量n的大小而变化,即此算法空间复杂度为一个常量,可表示为 O(1)
int i = 1;
int j = 2;
++i;
j++;
int m = i + j;代码中的 i、j、m 所分配的空间都不随着处理数据量变化,因此它的空间复杂度 S(n) = O(1)
5.2.2 O(n)
如归并排序
6. 类型转换
类型转换场合分:
- 自动转换;
- 赋值转换;
- 强制转换;
6.1 自动转换
自动转换的优先级:
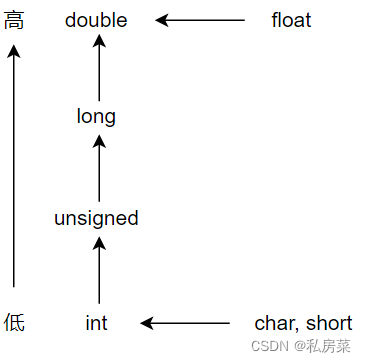
当自动转换时,有一下几点:
- char、short 自动转换成 int 类型;
- flat 自动转换成 double 类型;
- 不同类型运算,会将低等级自动转换成高等级的类型,例如,int 类型和double 类型的数运算,会将int 类型自动转换成 double 类型再进行运算;
char c = 'A';
int i = 10;
float x = 1.2;
double y = 2.5;若表达式为:
i + c + x * y;- step1,先进行 i + c,此时需要将 c 自动转换为 int 类型,进行求和运算,结果为 int 类型;
- step2,将 x 自动转换为 double 类型,与 y 进行乘运算,结果为 double 类型;
- step3,因为 step1 结果为 int 类型,step2 结果为 double 类型,需要将step1 的结果自动转换成 double 类型,进行求和运算,结果为 double 类型;
6.2 赋值转换
如果赋值运算符两侧的类型不一致,但都是数值型或字符型时,在赋值时要进行类型转换。转换的基本原则如下:
- 将整型数据赋给单、双精度变量时,数值不变,但以浮点数形式存储到变量中;
- 将实型数据(包括单、双精度)赋给整型变量时,舍弃实数的小数部分。如x为整型变量,执行“x=4.25”时,取值为x=4;
- 同类型的短数据赋值给长变量,自动转换是正确的,例如,char和short型数据给int型变量赋值;
- 同类型的长数据给短变量赋值可能出错。例如,当 unsigned int型的值超过了 int 变量的取值范围,赋值会出错;
例如:unsigned int 变量给 int 变量赋值出错
#include <stdio.h>
#include<windows.h>
void main()
{
unsigned int s = 4294967294 ; //将很大的无符号整型数赋给变量s
int a;
a=s; //将s的值赋给变量a
printf("%12d\n",a); //输出变量a的值
system("pause");
}
输出结果为 -2,对于变量 s 来说是无符号整型数,最大的取值可以到 4294967295,最高位为 1,但对于有符号整型数来说,最大值为 2147483647,所以此时的 4294967294 赋值给有符号位变量 a 时,会看成是符号位为1,其它位为 2147483646,即 -2;
6.3 强制转换
强制类型转换的一般形式为:
(类型名)(表达式)7. 寄存器运算
#define set_reg(addr,val) Wr(addr, val)
#define get_reg(addr) Rd(addr)
#define set_bits(addr,val,start,len) Wr(addr, (Rd(addr)&(~(((1L<<(len))-1)<<start)))|((val&((1L<<(len))-1))<<start))
#define get_bits(addr,start,len) (Rd(addr)>>(start)) & ((1L<<(len))-1)
#define set_bit(addr,val,index) set_bits(addr,val,start,1)
#define get_bit(addr,index) get_bits(addr,index,1)8. 指针
1)指针,其实完全可以看做一个地址。
2)指针变量,说明这个指针是可变的,就相当于int a,a也是个变量,只不过a的值是个整型,而指针变量代表的是可变的地址。
定义的时候怎么表示指针?就用到了符号“*”,int *p;说明p是个指针变量,地址p里面放的是一个整型数。
3)指针变量使用跟普通变量一个,例如int a;a = 4;a只能赋值一个整型数。int *p;p = (int *)0x12345;或p = &a;
如果需要获取地址p所指的值,同样用到符号“*”。p = &a;那么*p就是a的值也就是4。
4)指针表示一维数组,a[i] 就是*(p+i)
5)指针表示二维数组,a[i][j]就是*(*(p+i) + j)
6)指针函数,即返回值是指针的函数。函数指针,即指向函数的指针
9. 去除字符串两端空格
char *s_trim(char *str)
{
char *s = str;
char *copied, *tail = NULL;
if(str == NULL || *str = '\0')
return str;
if((str[0] != ' ') && (str[strlen(str)-1] != ' '))
return str;
for(copied = str; *str; str++){
if(*str != ' ' && *str != '\t' && *str != '\r' && *str != '\n'){
*copied++ = *str;
tail = copied;
}
else{
if(tail)
*copied++ = *str;
}
}
if(tail)
*tail = 0;
else
*copied = 0;
return s;
}10. 获取文件大小
#include <sys/stat.h>
int FileSize(const char* fname)
{
struct stat statbuf;
if(stat(fname,&statbuf)==0)
return statbuf.st_size;
return -1;
}11. 读取目录下的文件
//测试读取目录下文件
#define TEST_FILE_PATH "./"
#define TEST_FILE_MAX_PATH_LENGTH 64
#define TEST_FILE_MAX_NAME_LENGTH 64
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <dirent.h>
#include <unistd.h>
int getPlayFileList(char fileNames[][TEST_FILE_MAX_NAME_LENGTH], const int maxCount)
{
if (!fileNames || maxCount <= 0) {
printf("getPlayFileList failed for invalid paramter.\n");
return -1;
}
DIR *dir;
struct dirent *ptr;
int fileIndex = 0;
if ((dir=opendir(TEST_FILE_PATH)) == NULL) {
printf("open dir %s failed.\n", TEST_FILE_PATH);
return -1;
}
while ((ptr=readdir(dir)) != NULL) {
if (strcmp(ptr->d_name,".") == 0 //过滤当前目录
|| strcmp(ptr->d_name,"..") == 0 //过滤前一级目录
|| ptr->d_type == 4 //过滤掉目录文件
|| ptr->d_type == 10) { //过滤掉链接文件
continue;
} else {
if (fileIndex >= maxCount) {
break;
}
strncpy(fileNames[fileIndex], ptr->d_name, ptr->d_reclen < TEST_FILE_MAX_NAME_LENGTH ? ptr->d_reclen : TEST_FILE_MAX_NAME_LENGTH);
++fileIndex;
}
}
closedir(dir);
return fileIndex;
}
int main()
{
char fileName[10][TEST_FILE_MAX_NAME_LENGTH];
memset(fileName, sizeof(fileName), 0);
printf("size of fileName: %lu\n", sizeof(fileName));
int cnt = getPlayFileList(fileName, 10);
for (int i = 0; i < cnt; ++i) {
printf("[%d]: %s\n", i, fileName[i]);
}
return 0;
}其中过滤的那个if case 只是用来参考的,里面过滤d_type == 4就可以把 . 和 .. 两个目录过滤了。
其中核心的主要是目录的数据结构:
#include <dirent.h>
struct dirent
{
long d_ino; //inode number 索引节点号
off_t d_off; //offset to this dirent 在目录文件中的偏移
unsigned short d_reclen; //length of this d_name 文件名长
unsigned char d_type; //the type of d_name 文件类型
char d_name [NAME_MAX+1]; //file name (null-terminated) 文件名,最长255字符
}12. 大端字节序和小端字节序
硬件架构决定了系统的字节序方式。例如,x86 架构是小端系统,而 PowerPC 和 SPARC 等架构通常是大端系统。在网络通信中,由于存在小端和大端系统的差异,需要在数据传输时进行字节序的转换,以确保数据在不同系统之间正确解释。
什么是大端字节序?什么是小端字节序?
通俗一点就是一个数有高、低位字节,例如0x1234567,那么0x01 位于高位字节数,0x67位于低位字节数,读取(或排列)的时候先读到的是高位字节的数,那就是大字节序;读取(或排列)的时候先读取的是低位字节的数,那就是小字节序。
人们习惯按照大字节序读取、写,例如上面说的0x1234567,就是按照大字节序排列的。
而,计算机存储中
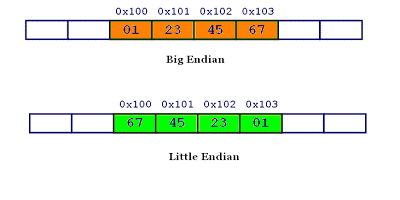
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
计算机中存储如下:
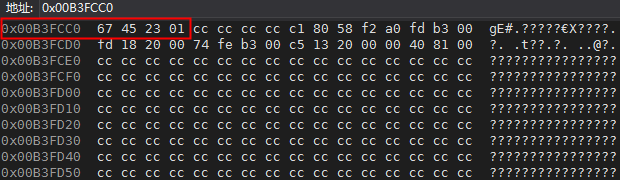
计算机中先读取低位字节的数,也就是说计算机内部处理中都是小字节序
13. float和double类型的数在内存中的存储
float 为4个字节,在内存中存放的组成部分:

共分三个部分:
- Sign(1bit):表示浮点数是正数还是负数。0表示正数,1表示负数
- Exponent(8bits):指数部分。类似于科学技术法中的M*10^N中的N,只不过这里是以2为底数而不是10。需要注意的是,这部分中是以2^7-1即127,也即01111111代表2^0,转换时需要根据127作偏移调整。*10000000代表2^1,10000001代表2^2...实际上就是Exponent - 127 = log2 (2^n)。*回忆科学记数法,nE0等于其本身,即不进/退小数位,nEx则进/退x位.
- Mantissa(23bits):基数部分。浮点数具体数值的实际表示。
以10.23 为例,转换过程为:
step 1: 改写整数部分 10 的二进制位1010
step 2:改写小数部分 一直乘以2,直到没有小数为止。
0.23 * 2 = 0.46 0
0.46 * 2 = 0.92 0
0.92 * 2 = 1.84 1
0.84 * 2 = 1.68 1
0.68 * 2 = 1.36 1
0.36 * 2 = 0.72 0
......
......
即 .001110...
step 3:规格化
1010.001110 经过规格化后,只需要保留一位整数,即1.010001110... * 2^3,经过规格化后,整数位可以去掉,因为2^3次方,相对127偏移为正,即最后为0.010001110... * 2^3
step 4:填充
因为是正数,sign 为0
2^3 即3次方,相对127偏移即为130,即exponent为1000 0010
mantissa 为生下来的尾数,即010001110...
step 5:内存中
最后内存中的数为010000010010001110...
double 为8个字节,内存中存放组成部分为:

注意Exponent 同float,在2^11 - 1 = 1023 上做偏移,例如10.23 这个数,Exponent 为1023 + 3 = 1026
14. 夹值(clamp)
在C++17 中的std 中有了clamp函数的定义,对于c 来说,比较简单:
#define min(a, b) (((a) < (b)) ? (a) : (b))
#define max(a, b) (((a) > (b)) ? (a) : (b))
static int clamp(int low, int high, int value) {
return max(min(value, high), low);
}15. printf 中使用 * 进行占位
之前有人提问到如何使用一个变量,动态控制一个float 变量输出时候的精度,后来还想了很久,没想到printf 中就有这样的用法:
#include <stdio.h>
int main()
{
float a = 1.23;
int b = 4;
printf("%.*f\n", b, a);
return 0;
}printf 中可以使用 %.*f 来占位,例如这个例子中*来占位,具体多少通过变量 b 控制。
也可以改成:
printf("%*.*f\n", 10, b, a);这里使用了常量10控制输出的总位数,其实就等价与:
printf("%10.4f", a);16. 素数
int is_prime(int n)
{
if(n <= 3)
return n > 1;
for(int i = 2; i * i <= n; i++)
if(n%i == 0)
return 0;
return 1;
}17. 确定一个数是否为2的幂
bool is_power_of_2(unsigned long n)
{
return (n != 0 && ((n & (n - 1)) == 0));
}如果是2 的幂,那么减去1之后,最高位的1变为0,其他的低位变成1,与运算之后肯定为0.
99. 其他
Learn the C++ language from its basics up to its most advanced features :
GCC
The GNU Compiler Collection includes front ends for C, C++, Objective-C, Fortran, Ada, Go, and D, as well as libraries for these languages (libstdc++,...). GCC was originally written as the compiler for the GNU operating system. The GNU system was developed to be 100% free software, free in the sense that it respects the user's freedom.
GCC, the GNU Compiler Collection- GNU Project
简单用法,直接下载code:blocks ,全套开发资料就包含了
中文电子书
GitHub - justjavac/free-programming-books-zh_CN: 免费的计算机编程类中文书籍,欢迎投稿
C++参考资料汇总
https://github.com/fffaraz/awesome-cpp
Compiler
List of C or C++ compilers
- 8cc - A Small C Compiler.
- c - Compile and execute C "scripts" in one go! [MIT]
- Clang - A C compiler for LLVM. Supports C++11/14/1z C11. Developed by LLVM Team. [NCSA]
- GCC - GNU Compiler Collection. Supports C++11/14/1z C11 and OpenMP. [GNU GPL3]
- PCC - A very old C compiler. Supports C99.
- Intel C++ Compiler - Developed by Intel.
- LLVM - Collection of modular and reusable compiler and toolchain technologies.
- Microsoft Visual C++ - MSVC, developed by Microsoft.
- Open WatCom - Watcom C, C++, and Fortran cross compilers and tools. [Sybase Open Watcom Public License]
- Oracle Solaris Studio - C, C++ and Fortran compiler for SPARC and x86. Supports C++11. Available on Linux and Solaris. [OTN Developer License]
- TCC - Tiny C Compiler. [LGPL]
Integrated Development Environment
List of C or C++ nominal IDEs.
- Anjuta DevStudio - The GNOME IDE. [GPL3]
- AppCode - an IDE for Objective-C, C, C++, and JavaScript development built on JetBrains’ IntelliJ IDEA platform.
- Cevelop - Cross-platform C and C++ IDE based on Eclipse CDT with additional plug-ins.
- CLion - Cross-platform C and C++ IDE from JetBrains.
- Code::Blocks - A free C, C++ and Fortran IDE.
- CodeLite - Another cross-plaform, free C and C++ IDE. [GPL2 with an exception for plugins]
- color_coded - A vim plugin for libclang-based highlighting. [MIT]
- Dev-C++ - A portable C/C++/C++11 IDE.
- Eclipse CDT - A fully functional C and C++ IDE based on the Eclipse platform.
- Geany - Small, fast, cross-platform IDE. [GPL]
- IBM VisualAge - A family of computer integrated development environments from IBM.
- Irony-mode - A C/C++ minor mode for Emacs powered by libclang.
- juCi++ - Cross-platform, lightweight C++ IDE with libclang integration. [MIT]
- KDevelop - A free, open source IDE.
- Microsoft Visual Studio - An IDE from Microsoft.
- NetBeans - An IDE for developing primarily with Java, but also with other languages, in particular PHP, C/C++, and HTML5.
- Qt Creator ⚡️ - A cross-platform C++, JavaScript and QML IDE which is part of the SDK for Qt.
- rtags - A c/c++ client/server indexer with for integration with emacs based on clang.
- Xcode - Developed by Apple.
- YouCompleteMe - YouCompleteMe is a fast, as-you-type, fuzzy-search code completion engine for Vim.
- cquery - A C++ code completion engine for vscode, emacs, vim, etc.



















 4223
4223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











