




25 微服务缓存设计模式——Cache-Aside、Read-Through、Write-Behind,分布式锁 Redlock 争议与 Redisson 实现
(接上文《24 微服务缓存:从本地 LRU 到 Redis 集群》)
25.1 三种经典缓存模式
在上一节我们把 Redis 集群搭好、把序列化协议定了,但“有缓存”不等于“缓存好用”。工程上真正决定命中率、一致性、故障面的是“谁来写、谁来读、什么时候回源”。业界把最常见的三种套路抽象成 Cache-Aside、Read-Through、Write-Behind(也叫 Write-Back)。它们不是“要么 A 要么 B”的单选题,而是可以在不同业务域混用的战术组合。
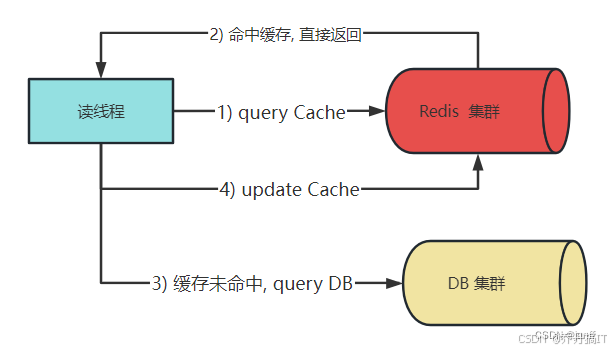
25.1.1 Cache-Aside(旁路缓存)
角色划分:
- 应用代码 = Cache Client + DB Client
- Redis 完全被动,不知道 DB 的存在
读写时序:
- 读:先读 Redis → miss → 读 DB → 回写 Redis → 返回给用户
- 写:先写 DB → 成功后再删缓存(或发消息异步删)
优点:
- 实现简单,不依赖 Redis 特殊指令
- 缓存层可随意替换(Memcache、Caffeine 都行)
致命缺陷:
- 并发读写存在“中间态窗口”:A 写 DB 成功、删缓存;B 在 A 删之前刚好 cache miss,把旧值拉回缓存,导致后续读都脏
- 双写(DB+Cache)在应用代码里硬编码,事务边界容易漏
缓解方案:
- 延迟双删:写完 DB 后先删一次,再发延迟消息 500ms 后再删一次
- 版本号 + 增量回源:缓存里存“数据版本”,回源时比较版本,低则抛弃
- 直接放弃强一致,用“过期时间”兜底,接受秒级不一致
25.1.2 Read-Through(通读缓存)
角色划分:
- 应用只和缓存打交道
- Cache Provider 里注册一个 CacheLoader,miss 时自动回源
Redis 本身没有 Loader 机制,需要上层框架(Spring Cache、Redisson ReadThroughMapping、RedisLabs 的 RedisGears)来做胶水层。
伪代码:
RMap<String, Order> orderMap = redisson.getMap("order",
MapOptions.<String, Order>defaults()
.loader(orderId -> orderRepo.selectById(orderId)));
Order o = orderMap.get("123"); // miss 时框架会回调 loader
优点:
- 业务代码 0 回源逻辑,符合“单一职责”
- 缓存侧可做“批量回源”“级联回源”优化
缺点:
- 首次 miss 的 RT 包含 DB 耗时,毛刺明显
- 缓存层引入业务 schema,替换缓存产品成本升高
25.1.3 Write-Behind(写回缓存)
角色划分:
- 应用只写缓存,不写 DB
- 缓存层把变更刷盘异步化、批量合并
实现要点:
- 写缓存时同时写一份“待同步队列”(Redis Stream、Disruptor、MySQL binlog)
- 后台线程按时间或数量攒批后写 DB
- 刷盘成功再删除队列,失败重试直到超过阈值报警
优点:
- 写性能 ≈ 纯内存,轻松抗 10w+ TPS
- 合并热点写,DB 压力降 1~2 数量级
缺点:
- 数据丢失窗口:宕机时队列里未刷盘的数据就丢了
- 与 Read-Through 混用时,如果缓存淘汰策略不当,可能把“还没刷盘”的数据踢掉,导致永久丢失
- 必须引入“顺序号”或“binlog 位点”做幂等,否则重试时 duplicate key 会把 DB 写炸
适用场景:
- 计数器、点赞、秒杀库存这种“可丢、可合并”的业务
- 对 RT 极其敏感、但能接受秒级不一致的场景
25.2 分布式锁:Redlock 争议与工程落地
缓存除了“存数据”,还常被顺手当成“分布式锁”。但 Redis 主从异步复制 + fail-over 会导致“同一把锁被两个节点同时拿到”,于是 Redis 作者 Salvatore 在 2015 年提出 Redlock 算法:
- 客户端拿到当前时间 T1
- 依次向 5 个独立 master 节点用 Lua 脚本抢锁(SET key uuid NX PX 30000)
- 当且仅当“多数节点(>=3)成功”且“耗时 < 锁有效时间”才算抢锁成功
- 释放时向所有节点发 DEL,仅当 value 是自己 uuid 时才删
争议点:
- Martin Kleppmann 发文《How to do distributed locking》直指 Redlock 对“系统时钟假设”太强:GC 停顿、NTP 跳变会把步骤 3 的“耗时”计算整失效
- Redis 作者反击:Redlock 不依赖绝对时钟,只需要“单调时钟”即可;GC 停顿超过 TTL 属于“业务层自己设置 TTL 不合理”,不是算法问题
- 结论:Redlock 不是“银弹”,在跨机房、容器化、NTP 不稳定的场景下,确实会出现“双主”
25.3 Redisson 的“看门狗”实现
Redisson 没有重复造 Redlock,而是把 Redlock 作为“MultiLock”的一种组合用法,日常更推荐“单机 + 看门狗”模式:
- 加锁:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
- 用 Hash 结构存“重入次数”,value=uuid:threadId
- TTL 默认 30s
- 看门狗:
- 业务线程拿到锁后,Redisson 启动一个 Netty 定时任务,每 10s 续期一次(pexpire 到 30s)
- 只要业务线程还存活(持有锁的 channel 没断开),就自动续
- 一旦业务 crash,channel 关闭,续期任务随之取消,30s 后锁自动释放
- 红锁(MultiLock):
RLock lock1 = redisson1.getLock("lock");
RLock lock2 = redisson2.getLock("lock");
RLock lock3 = redisson3.getLock("lock");
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
lock.lock(); // 内部就是按 Redlock 算法依次加锁
- 读写锁:
Redisson 还实现了 Redis 版的 ReadWriteLock,读锁完全可重入、写锁排他,通过 Hash+Semaphore 机制实现,适合“读多写少”的缓存重建场景。
25.4 综合选型建议
- 并发量 < 1k/s、允许秒级不一致:Cache-Aside + 过期时间 足矣
- 并发量高、读毛刺敏感:读域用 Read-Through,热点 key 加本地 Caffeine 二级缓存
- 写量高、可丢数:Write-Behind + 队列持久化(Kafka)+ 定期对账
- 分布式锁:
– 同机房、主从延迟 < 1ms:Redisson 单机锁 + 看门狗
– 跨机房、容灾级别高:Redlock(5 独立 master)(能接受极端场景双主风险)或直接用 etcd/zk 的 CP 锁
25.5 小结
缓存模式没有“best”,只有“least worst”。先把读写路径画成时序图,把“不一致窗口”圈出来,再决定用哪种模式;分布式锁能不用就不用,必须用时就接受“锁失效”的兜底方案(幂等、幂重、对账)。下一节我们将进入“缓存与数据库的最终一致性”实战:基于 Canal + Kafka 的异步消息链路透传,以及“缓存击穿、雪崩、穿透”的三板斧防护。
更多技术文章见公众号: 大城市小农民



















 3473
3473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











