






目录
一、索引失效的总结:
1,运算符(比较运算符,逻辑运算符)
| mysql运算符 | 可能引起索引失效 | 说明 |
| 算术运算符 | 加减乘除 | |
| 比较运算符 | 不等于 !,大于 >,小于 < in,not in,null ,like | |
| 逻辑运算符 | or | 用 or 必有全索引 |
| 位运算符 |
2,函数
3,联合索引
(组合索引如果不按照索引的顺序进行查找,比如直接使用第三个位置上的索引而忽略第一二个位置上的索引时,则会进行全表查询)
二、数据库索引type解读
type显示查询使用了何种类型,从走好到最差依次是下面顺序
A : system :表示只有一行记录,这是const类型的特例,平时不会出现,这个可以忽略不计。
B : const : 表示通过索引一次就找到了,const用于表示primary key或者unique索引。因为只匹配一行数据,所以很快。
C : eq_ref :唯一性索引扫描,对应每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
D : ref :非唯一索引扫描,返回匹配某个单独值的所有行;本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到很多个符合条件的行,所以他应该属于查找和扫描的混合体。
E : range :只检索给定范围的值,使用一个索引选择行。key列显示使用了那个索引,一般就是在where语句中出现了between、<、>、in等的查询。这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
F : index :Full Index Scan,index与All的区别为index类型只遍历索引树。这通常比All快,因为索引文件通常比数据文件少。也就是说虽然All和Index都是读全表,但index是从索引里面读,而all是从硬盘里面读。
G : all :Full Table Scan,将遍历全表找到匹配的行。
一般来说,得保证查询至少达到range级别,最好达到ref级别。
三、索引不一定失效
可能因为mysql这个东西太复杂,感觉sql优化都快成玄学了。网上流传了很多“奇技淫巧”,让人真假难辨。我觉得可能是过去mysql优化不是很好时,大家有一些优化的技巧,但随着mysql更新优化,现在已经成为过时甚至错误的做法。但这些说法还在流传,造成了我这样的新手的困惑。
1. or 不一定索引失效
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引;

2. like 不一定索引失效
一般like %aa% ,%aa失效,aa%不失效;
但若必须两边都模糊呢?只有当这个作为模糊查询的条件字段(例子中的name)以及所想要查询出来的数据字段(例子中的 name& email & phone)都在索引列上时,才能真正使用索引;
多一个不是索引的字段就失效;


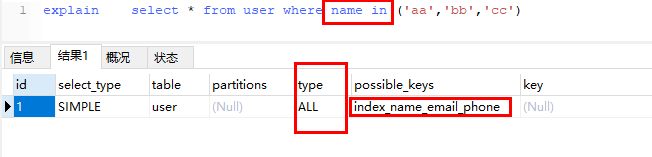
3. in,not in 不一定索引失效
in 的字段单独是索引,【复合索引 in +select *】 不行,【复合索引 in + select 索引字段】可以;


4. 【复合索引】 不一定索引失效
①复合索引全值匹配最好。
②最左前缀匹配原则。③在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
④在选择组合索引的时候,尽量选择可以能够包含当前query中的where子句中更多字段的索引。如果是组合索引的话,如果不按照索引的顺序进行查找,比如直接使用第三个位置上的索引而忽略第一二个位置上的索引时,则会进行全表查询;
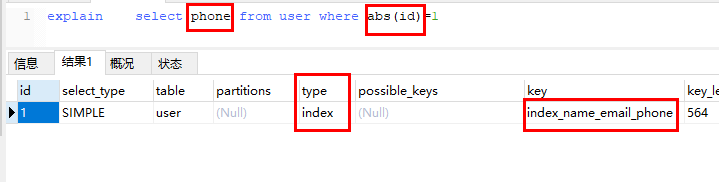
5.【函数】 不一定索引失效

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









