




 这篇博客主要介绍了如何实现字母异位词的分组和有效判断。在49字母异位分组问题中,通过两种不同思路,利用哈希表或遍历比较,将字母异位词归为同一组。而在242有效的字母异位词问题中,通过统计字符出现次数或排序字符串来判断两个字符串是否为字母异位词。这两个算法都涉及字符串处理和哈希映射,提高了字符串比较的效率。
这篇博客主要介绍了如何实现字母异位词的分组和有效判断。在49字母异位分组问题中,通过两种不同思路,利用哈希表或遍历比较,将字母异位词归为同一组。而在242有效的字母异位词问题中,通过统计字符出现次数或排序字符串来判断两个字符串是否为字母异位词。这两个算法都涉及字符串处理和哈希映射,提高了字符串比较的效率。
一、49字母异位分组
1.1题目
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出:
[
[“ate”,“eat”,“tea”],
[“nat”,“tan”],
[“bat”]
]
说明:
所有输入均为小写字母。
不考虑答案输出的顺序。
1.2实现
/**49: 字母异位分组**/
public class GroupAnagrams {
/**给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
* 即单词的字母组成上相同的但排列顺序不同的分为一个组,遍历每一个单词和保存结果lists中的每一个组中单词进行对比。
* 判断是不是异位的,是则加入该组,不是则说明没有与任何已经存在的组异位,自己独自建组加入lists结果集中
* 直到遍历完存在的所有组,。
**/
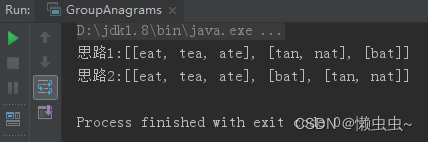
public static void main(String[] args) {
String[] strs = {"eat", "tea", "tan", "ate", "nat", "bat"};
System.out.println("思路1:"+groupAnagramsOne(strs));
System.out.println("思路2:"+groupAnagramsTwo(strs));
}
/**思路1**/
public static List<List<String>> groupAnagramsOne(String[] strs) {
List<List<String>> lists = new ArrayList<>(); // 定义保存异位结果的 lists
for (int i = 0; i <strs.length ; i++) {
boolean flag = false;// 记录是否有加入已经存在的组
for (List<String> list : lists ) {
if(isSameWords(strs[i],list.get(0))){// 判断当前组的第一个单词和遍历的单词是否异位
list.add(strs[i]);// 是异位则加入该组
flag = true;// 状态改为已加入组的状态
}
}
if(flag == false){// 没有加入组,说明没有与任何已经存在的组异位,自己独自建组加入lists
ArrayList tempList = new ArrayList();
tempList.add(strs[i]);
lists.add(tempList);
}
}
return lists; // 最终返回lists
}
public static boolean isSameWords(String words1,String words2){
if(words1.length() != words2.length()){
return false;
}
char[] w1 = words1.toCharArray();
char[] w2 = words2.toCharArray();
Arrays.sort(w1);
Arrays.sort(w2);
return String.valueOf(w1).equals(String.valueOf(w2));
}
/**思路2**/
/**用哈希表来存储结果,每一个单词先转换成字符数组,然后排序,
* 再把排序后的字符数组转换成字符串作为同类异位单词的 key ,组作为 value。
* 例如示例:[“eat”, “tea”, “tan”, “ate”, “nat”, “bat”],对于 “eat” 和 “tea” 单词他们转化求 key 都是 “aet” ,即属于同一个组。
**/
public static List<List<String>> groupAnagramsTwo(String[] strs) {
HashMap<String,List<String>> map = new HashMap();// 定义哈希表存储分组结果,key是按字母顺序排序后的单词,value是相同字母但顺序不同的单词
for (int i = 0; i <strs.length ; i++) {
char[] chars = strs[i].toCharArray();
Arrays.sort(chars);
String key = String.valueOf(chars);
if(map.containsKey(key)){// 如果这个 key 在哈希表中存在
List<String> tempList = map.get(key);//取出key对应的组
tempList.add(strs[i]);//添加相同key对应的单词即当前单词strs[i]
}else{// 如果这个 key 在哈希表中不存在 ,则要创建一个新组存放当前单词strs[i]
List<String> tempList = new ArrayList();
tempList.add(strs[i]);
map.put(key,tempList);
}
}
List<List<String>> result = map.values().stream().collect(Collectors.toList());
//List<List<String>> result = new ArrayList<>(map.values());
return result;
}
}
二、242有效的字母异位词
2.1题目
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
1
2
示例 2:
输入: s = “rat”, t = “car”
输出: false
1
2
说明:你可以假设字符串只包含小写字母。
2.2实现
/** 242.有效的字母异位词 **/
public class IsAnagram {
/** 思路1
* 定义一个数组叫做record用来上记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,
所以字符a映射为下标0,相应的字符z映射为下标25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。
这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
**/
public boolean isAnagramOne(String s, String t) {
int[] record = new int[26];
for(char c : s.toCharArray()){
record[c - 'a'] += 1;
}
for(char c : t.toCharArray()){
record[c - 'a'] -= 1;
}
for(int r: record){
if(r != 0){
return false;
}
}
return true;
}
/**思路2
* 由于两个字符串字符一样,只是顺序不一致,则可以排序后再比较
* 字符串长度要相等,然后分别对字符串排序,最后比较是否一样
**/
public boolean isAnagramTwo(String s, String t) {
if(s.length() != t.length()){
return false;
}
char[] s1 = s.toCharArray();
char[] t1 = t.toCharArray();
Arrays.sort(s1);
Arrays.sort(t1);
return new String(s1).equals(new String(t1));
}
}

















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









