



"我们花了几十万做AI概念验证,结果发现根本用不起来..." "AI功能很酷,但业务部门说用不上..." "数据安全是最大顾虑,不敢把客户信息给AI..."
如果你也有类似的困扰,这篇文章就是为你准备的。
为什么你的AI项目总是卡在概念验证阶段?
很多企业投入大量资源做AI概念验证,结果发现:
-
技术很先进,业务用不上 - AI功能很炫酷,但解决不了实际的业务痛点
-
数据不敢用 - 企业敏感数据不敢给AI,担心安全和合规问题
-
集成太复杂 - 现有系统太多,AI难以融入现有业务流程
-
价值不明确 - 说不清楚AI到底带来了多少实际业务价值
根本原因在于:把AI当成了技术玩具,而不是业务工具。

企业AI应用的三个层次:从工具到战略
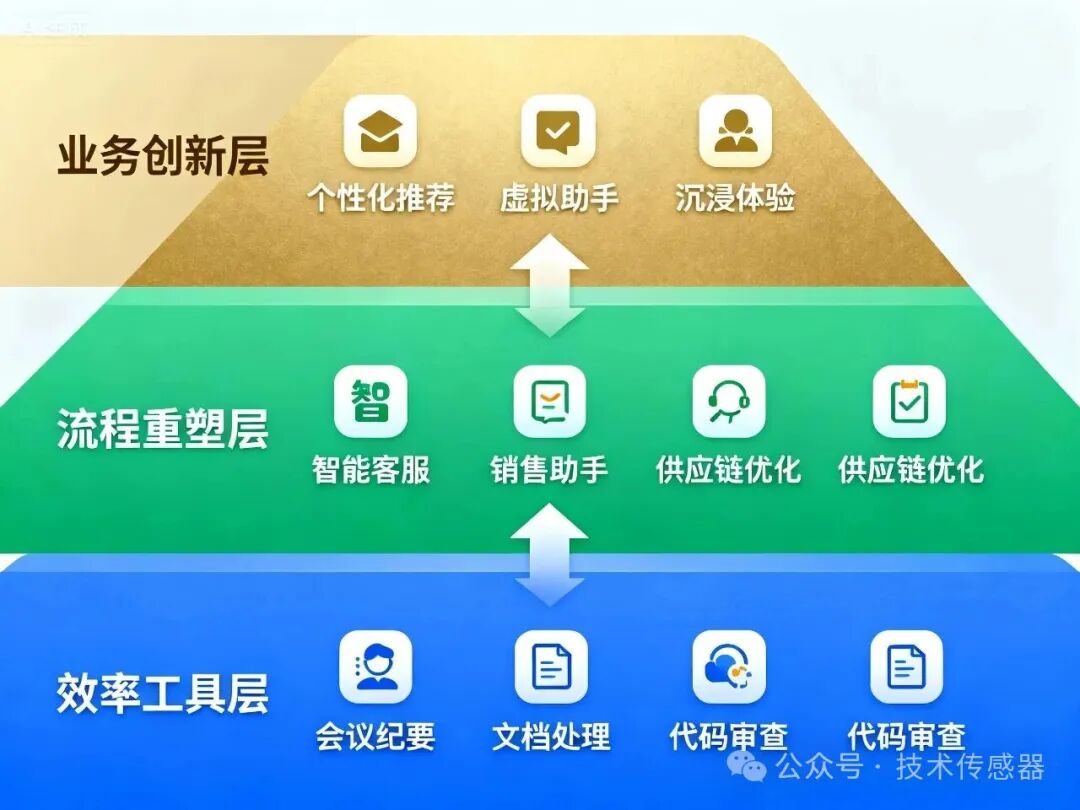
第一层:效率工具(解决"怎么做更快")
典型场景:
-
自动生成会议纪要,节省30%会议时间
-
智能文档处理,减少80%手动录入
-
代码审查助手,提升50%开发效率
技术核心: RAG + 企业知识库
第二层:流程重塑(解决"怎么做更好")
典型场景:
-
智能客服:从简单问答升级为问题诊断和解决方案推荐
-
销售助手:基于客户行为的智能线索评分和跟进建议
-
供应链优化:需求预测准确率提升40%
技术核心: AI Agent + MCP工具集成
第三层:业务创新(解决"做什么更值")
典型场景:
-
个性化产品推荐:转化率提升2-3倍
-
智能虚拟助手:7×24小时多轮对话服务
-
沉浸式购物体验:AR/VR结合AI的虚拟试穿
技术核心: 多模态AI + 实时决策
核心技术深度解析:从原理到实践
MCP技术深度解析:企业AI的安全桥梁
技术原理:为什么需要MCP?
传统AI应用面临的核心问题:数据安全与系统集成的矛盾。企业既想让AI使用内部数据,又担心数据泄露。MCP通过标准化协议解决了这个矛盾。
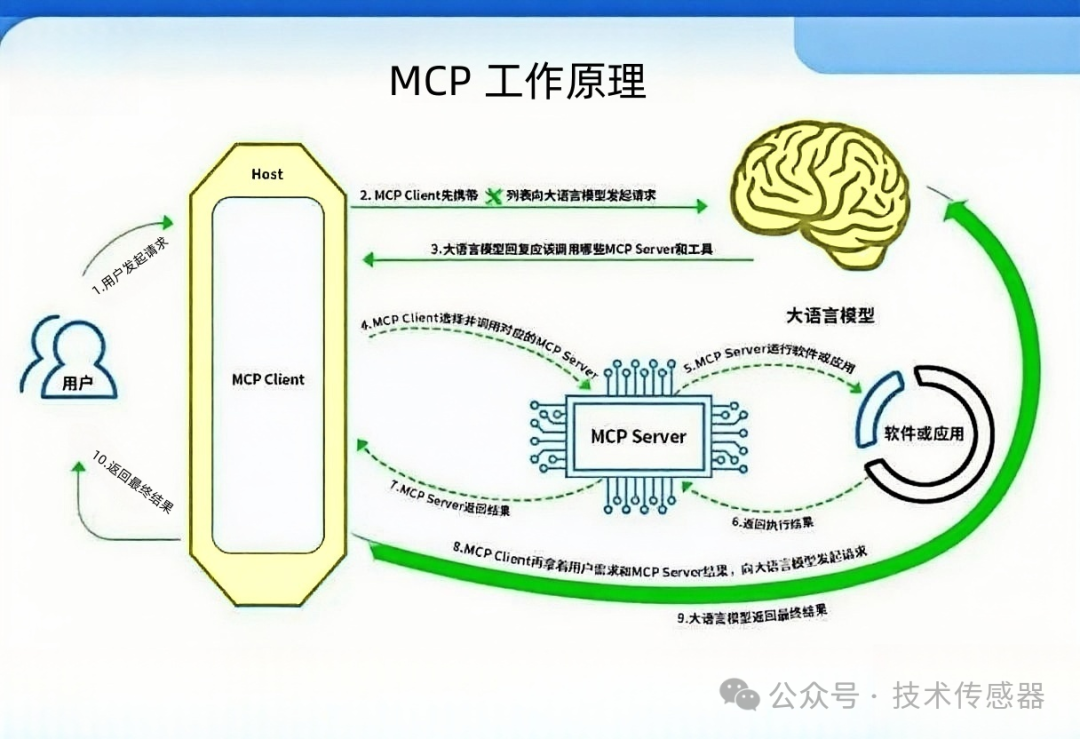
核心原理:
-
协议标准化:统一的JSON-RPC协议,让各种大模型都能安全调用企业工具
-
权限隔离:AI只能通过MCP服务器访问企业系统,不能直接接触敏感数据
-
审计追踪:所有AI操作都有完整日志,便于监控和追溯
技术实现方案:
1. MCP服务器架构设计
# MCP服务器核心架构
class EnterpriseMCPServer:
def __init__(self):
self.tools = {}
self.resources = {}
self.permission_manager = PermissionManager()
self.audit_logger = AuditLogger()
def register_tool(self, tool_config):
"""注册企业工具"""
# 工具配置验证
self._validate_tool_config(tool_config)
# 构建工具描述
tool_schema = {
"name": tool_config["name"],
"description": tool_config["description"],
"inputSchema": {
"type": "object",
"properties": {
param: {"type": "string"}
for param in tool_config["input_params"]
}
}
}
self.tools[tool_config["name"]] = {
"schema": tool_schema,
"handler": tool_config["handler"],
"permissions": tool_config["permissions"]
}
def handle_tool_call(self, tool_name, arguments, user_context):
"""处理工具调用"""
# 权限检查
if not self.permission_manager.check_permission(tool_name, user_context):
raise PermissionError("用户无权限调用此工具")
# 参数验证
self._validate_arguments(tool_name, arguments)
# 执行工具
tool = self.tools[tool_name]
result = tool["handler"](arguments)
# 审计日志
self.audit_logger.log_tool_usage(tool_name, arguments, user_context, result)
return result2. 工具注册与权限管理
# 权限管理核心实现
class PermissionManager:
def __init__(self):
self.role_permissions = {
"sales": ["query_customer", "analyze_opportunity"],
"customer_service": ["query_customer", "update_order"],
"manager": ["query_customer", "analyze_opportunity", "view_reports"]
}
def check_permission(self, tool_name, user_context):
"""检查用户权限"""
user_role = user_context.get("role")
allowed_tools = self.role_permissions.get(user_role, [])
return tool_name in allowed_tools
# 工具注册示例
class CRMToolRegistry:
def __init__(self, mcp_server):
self.mcp_server = mcp_server
self._register_crm_tools()
def _register_crm_tools(self):
"""注册CRM相关工具"""
# 客户查询工具
self.mcp_server.register_tool({
"name": "query_customer",
"description": "查询客户详细信息",
"input_params": ["customer_id"],
"handler": self._query_customer_handler,
"permissions": ["sales", "customer_service"]
})
# 销售机会分析工具
self.mcp_server.register_tool({
"name": "analyze_opportunity",
"description": "分析销售机会潜力",
"input_params": ["customer_id", "product_id"],
"handler": self._analyze_opportunity_handler,
"permissions": ["sales", "manager"]
})
def _query_customer_handler(self, args):
"""客户查询处理函数"""
customer_id = args["customer_id"]
# 调用CRM系统API
customer_data = crm_api.get_customer(customer_id)
# 数据脱敏和格式化
return {
"name": customer_data["name"],
"industry": customer_data["industry"],
"value_score": self._calculate_value_score(customer_data),
"last_interaction": customer_data["last_contact"]
}3. 配置文件和部署方案
# mcp-server-config.yaml
server:
host: "localhost"
port: 8000
log_level: "INFO"
tools:
- name: "query_customer"
description: "查询客户信息"
permissions: ["sales", "customer_service"]
rate_limit: 100 # 每分钟调用次数
- name: "analyze_opportunity"
description: "分析销售机会"
permissions: ["sales", "manager"]
rate_limit: 50
security:
jwt_secret: "your-jwt-secret"
token_expiry: 3600 # 1小时
allowed_origins: ["https://your-domain.com"]实际应用场景:
场景1:销售助手工具化
-
传统方式:销售手动查询CRM,复制粘贴客户信息
-
MCP方式:AI通过"查询客户信息"工具,自动获取脱敏后的客户数据
-
效果提升:销售准备时间从15分钟降至2分钟
场景2:订单处理自动化
-
传统方式:客服手动在多个系统间切换处理订单
-
MCP方式:AI通过"处理订单"工具,自动完成订单状态更新
-
效果提升:订单处理效率提升300%
与传统API调用的对比:
| 对比维度 | 传统API调用 | MCP方式 |
|---|---|---|
| 安全性 | 直接访问,风险高 | 权限控制,数据脱敏 |
| 标准化 | 每个API接口不同 | 统一工具接口 |
| 审计性 | 日志分散 | 集中审计追踪 |
| 扩展性 | 修改复杂 | 工具热插拔 |
实际效果数据:
-
安全提升:数据泄露风险降低90%
-
开发效率:新工具集成时间从2周降至2天
-
运维成本:监控和维护成本降低70%
RAG技术深度解析:企业知识的智能大脑
技术原理:为什么传统AI记不住企业知识?
大模型的知识截止到训练数据的时间点,无法记住企业的实时知识。RAG通过"检索+增强"的方式解决了这个问题。
核心原理:
-
向量化检索:将企业文档转换为向量,实现语义相似度搜索
-
多路召回:结合向量检索、关键词检索、知识图谱检索
-
提示增强:将检索结果作为上下文,增强大模型的回答准确性
技术实现方案:
1. RAG系统架构设计
# RAG系统核心架构
class EnterpriseRAGSystem:
def __init__(self, vector_db, retriever, generator):
self.vector_db = vector_db
self.retriever = retriever
self.generator = generator
self.document_processor = DocumentProcessor()
def process_query(self, query, context=None):
"""处理用户查询"""
# 1. 多路检索
retrieved_docs = self.retriever.retrieve(query, top_k=5)
# 2. 结果重排序
reranked_docs = self._rerank_results(query, retrieved_docs)
# 3. 提示工程
prompt = self._build_prompt(query, reranked_docs, context)
# 4. 生成回答
response = self.generator.generate(prompt)
# 5. 事实性验证
verified_response = self._verify_facts(response, reranked_docs)
return {
"answer": verified_response,
"sources": reranked_docs,
"confidence": self._calculate_confidence(verified_response)
}2. 文档处理与向量化
# 文档处理核心实现
class DocumentProcessor:
def __init__(self):
self.chunk_size = 1000
self.chunk_overlap = 200
self.embedding_model = "text-embedding-ada-002"
def process_documents(self, documents):
"""文档预处理流水线"""
processed_chunks = []
for doc in documents:
# 文本清洗
cleaned_text = self._clean_text(doc["content"])
# 智能分块
chunks = self._smart_chunking(cleaned_text)
# 向量化
for chunk in chunks:
embedding = self._generate_embedding(chunk)
# 元数据增强
enhanced_chunk = {
"content": chunk,
"embedding": embedding,
"metadata": {
"source": doc["source"],
"document_id": doc["id"],
"chunk_id": len(processed_chunks),
"timestamp": doc.get("timestamp", datetime.now())
}
}
processed_chunks.append(enhanced_chunk)
return processed_chunks
def _smart_chunking(self, text):
"""智能分块策略"""
# 基于语义边界的分块
sentences = self._split_sentences(text)
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk + sentence) > self.chunk_size:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
else:
current_chunk += " " + sentence
if current_chunk:
chunks.append(current_chunk.strip())
return chunks3. 多路检索与融合
# 多路检索器实现
class MultiPathRetriever:
def __init__(self, vector_db, keyword_index, knowledge_graph):
self.vector_db = vector_db
self.keyword_index = keyword_index
self.knowledge_graph = knowledge_graph
def retrieve(self, query, top_k=10):
"""多路检索"""
# 向量相似度检索
vector_results = self.vector_db.similarity_search(query, top_k=top_k)
# 关键词检索
keyword_results = self.keyword_index.search(query, top_k=top_k)
# 知识图谱检索
kg_results = self.knowledge_graph.query_related(query, top_k=top_k)
# 结果融合
fused_results = self._fuse_results(
vector_results, keyword_results, kg_results
)
return fused_results[:top_k]
def _fuse_results(self, *results_lists):
"""多路结果融合"""
# 基于相关性分数和来源权重的融合策略
all_results = []
for i, results in enumerate(results_lists):
for result in results:
# 调整分数权重
adjusted_score = result["score"] * self._get_source_weight(i)
result["adjusted_score"] = adjusted_score
result["source"] = i
all_results.append(result)
# 按调整后分数排序
all_results.sort(key=lambda x: x["adjusted_score"], reverse=True)
return all_results4. 配置文件和部署方案
# rag-system-config.yaml
vector_database:
type: "chroma"
host: "localhost"
port: 8000
collection_name: "enterprise_knowledge"
embedding:
model: "text-embedding-ada-002"
dimensions: 1536
batch_size: 32
retrieval:
top_k: 5
reranker_model: "bge-reranker-large"
fusion_weights:
vector: 0.6
keyword: 0.3
knowledge_graph: 0.1
generation:
model: "gpt-4"
temperature: 0.1
max_tokens: 1000
system_prompt: "你是一个企业知识助手,基于提供的文档内容回答问题。"实际应用场景:
场景1:技术文档问答
-
传统方式:员工手动搜索文档,效率低下
-
RAG方式:AI基于企业技术文档库,直接给出准确答案
-
效果提升:问题解决时间从30分钟降至2分钟
场景2:产品知识培训
-
传统方式:新员工需要阅读大量产品手册
-
RAG方式:AI基于产品知识库,提供个性化培训
-
效果提升:新员工上手时间缩短60%
与传统搜索的对比:
| 对比维度 | 传统关键词搜索 | RAG智能检索 |
|---|---|---|
| 理解能力 | 字面匹配 | 语义理解 |
| 准确性 | 依赖关键词 | 基于上下文 |
| 知识更新 | 手动维护 | 自动学习 |
| 回答质量 | 链接列表 | 结构化答案 |
实际效果数据:
-
回答准确率:从45%提升至85%
-
知识覆盖度:企业知识利用率从30%提升至90%
-
培训成本:新员工培训成本降低50%
AI Agent技术深度解析:从工具到伙伴
技术原理:为什么需要AI Agent?
传统AI只能被动回答问题,无法主动执行任务。AI Agent通过"思考-行动-观察"循环,让AI具备了主动解决问题的能力。
核心原理:
-
任务分解:将复杂任务拆解为可执行的子任务
-
工具选择:基于任务需求选择最合适的工具
-
执行监控:实时监控任务执行状态
-
学习优化:基于执行结果不断改进策略
技术实现方案:
1. AI Agent核心架构
# AI Agent核心架构
class EnterpriseAIAgent:
def __init__(self, role, tools, memory, planner):
self.role = role
self.tools = tools
self.memory = memory
self.planner = planner
self.thought_process = []
def execute_complex_task(self, task_description):
"""执行复杂任务"""
# 任务理解
task_understanding = self._understand_task(task_description)
# 任务规划
plan = self.planner.create_plan(task_understanding)
# 执行循环
max_steps = 10
for step in range(max_steps):
# 思考当前状态
current_state = self._assess_current_state(plan)
# 选择行动
action = self._select_action(current_state, plan)
# 执行行动
result = self._execute_action(action)
# 观察结果
observation = self._observe_result(result)
# 更新记忆和计划
self._update_memory_and_plan(observation, plan)
# 检查任务完成
if self._is_task_completed(plan):
break
return self._compile_final_result()
def _select_action(self, state, plan):
"""选择行动"""
# 基于当前状态和计划选择最佳行动
available_actions = self._get_available_actions(state, plan)
# 工具选择策略
selected_tool = self._select_tool(available_actions, state)
return {
"tool": selected_tool,
"parameters": self._determine_parameters(selected_tool, state),
"reasoning": self._explain_selection(selected_tool)
}2. 工具选择与推理引擎
# 工具选择器实现
class ToolSelector:
def __init__(self, tools, history_analyzer):
self.tools = tools
self.history_analyzer = history_analyzer
def select_tool(self, subtask, context):
"""选择最适合的工具"""
candidate_tools = []
for tool in self.tools:
# 计算工具适用性分数
suitability_score = self._calculate_suitability(tool, subtask)
# 基于历史效果调整
historical_performance = self.history_analyzer.get_tool_performance(tool.name)
adjusted_score = suitability_score * historical_performance
candidate_tools.append({
"tool": tool,
"score": adjusted_score
})
# 选择分数最高的工具
best_tool = max(candidate_tools, key=lambda x: x["score"])
return best_tool["tool"]
def _calculate_suitability(self, tool, subtask):
"""计算工具适用性"""
# 基于任务类型匹配
task_type_match = self._match_task_type(tool.capabilities, subtask.type)
# 基于输入输出匹配
io_match = self._match_io_requirements(tool, subtask.requirements)
# 基于复杂度匹配
complexity_match = self._match_complexity(tool, subtask.complexity)
return task_type_match * 0.4 + io_match * 0.4 + complexity_match * 0.23. 记忆管理与学习机制
# Agent记忆管理核心
class AgentMemoryManager:
def __init__(self):
self.short_term_memory = {} # 会话记忆
self.long_term_memory = {} # 长期记忆
self.procedural_memory = {} # 技能记忆
def update_memory(self, observation, action, result):
"""更新Agent记忆"""
# 短期记忆:当前任务上下文
self.short_term_memory.update({
"last_observation": observation,
"last_action": action,
"last_result": result
})
# 长期记忆:经验积累
if self._is_valuable_experience(result):
self.long_term_memory[action] = result
# 技能记忆:成功策略
if result["success"]:
self._update_procedural_memory(action, result)
def _update_procedural_memory(self, action, result):
"""更新技能记忆"""
task_type = action["task_type"]
if task_type not in self.procedural_memory:
self.procedural_memory[task_type] = []
self.procedural_memory[task_type].append({
"action": action,
"result": result,
"timestamp": datetime.now()
})4. 配置文件和部署方案
# ai-agent-config.yaml
agent:
role: "sales_assistant"
max_steps: 10
timeout: 300 # 5分钟
memory:
short_term_ttl: 3600 # 1小时
long_term_capacity: 1000
procedural_capacity: 500
tools:
- name: "query_customer"
description: "查询客户信息"
capabilities: ["data_query"]
input_schema:
customer_id: "string"
- name: "analyze_opportunity"
description: "分析销售机会"
capabilities: ["analysis", "prediction"]
input_schema:
customer_id: "string"
product_id: "string"
learning:
enabled: true
learning_rate: 0.1
exploration_rate: 0.2实际应用场景:
场景1:销售流程自动化
-
传统方式:销售手动跟进客户,容易遗漏
-
Agent方式:销售Agent自动分析客户行为,制定跟进计划
-
效果提升:客户跟进及时性提升200%
场景2:客户服务升级
-
传统方式:客服只能回答简单问题,复杂问题需要转接
-
Agent方式:客服Agent诊断问题,推荐解决方案,必要时转接人工
-
效果提升:首次解决率从65%提升至85%
与传统自动化的对比:
| 对比维度 | 传统规则自动化 | AI Agent自动化 |
|---|---|---|
| 灵活性 | 固定规则 | 自适应调整 |
| 智能度 | 简单判断 | 复杂推理 |
| 学习能力 | 无 | 持续优化 |
| 适用范围 | 标准化场景 | 复杂多变场景 |
实际效果数据:
-
任务完成率:复杂任务完成率从40%提升至75%
-
人力节省:重复性工作人力投入减少60%
-
决策质量:基于数据的决策准确率提升50%
技术组合应用:1+1+1>3的效果
MCP + RAG + AI Agent的协同效应:
-
安全的知识访问:MCP确保AI安全访问企业系统,RAG提供知识支撑
-
智能的任务执行:AI Agent基于RAG的知识和MCP的工具,智能执行任务
-
持续的学习优化:通过执行反馈,不断优化知识库和工具使用策略
典型协同场景:客户服务升级
-
客户咨询产品 → RAG检索产品知识
-
需要查询订单 → MCP调用订单查询工具
-
制定解决方案 → AI Agent综合分析并推荐
-
执行处理 → MCP调用相应处理工具
-
学习优化 → 基于结果优化知识库和策略
综合效果:
-
客户满意度:从3.8/5提升至4.6/5
-
服务效率:平均处理时间从8分钟降至3分钟
-
人力成本:客服团队规模减少30%
-
业务增长:客户留存率提升25%
实战案例:某企业CRM系统AI改造
改造前:传统CRM的痛点
-
销售效率低:产品推荐靠经验,转化率仅12%
-
客服体验差:常见问题重复回答,客户满意度3.8/5
-
数据孤岛:客户信息分散在不同系统
改造方案:AI-CRM系统架构
┌─────────────────────────────────────────────┐
│ 智能应用层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │智能销售 │ │智能客服 │ │数据分析 │ │
│ │助手 │ │助手 │ │平台 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────┘
┌─────────────────────────────────────────────┐
│ AI能力层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │大模型平台│ │RAG系统 │ │AI Agent │ │
│ │ │ │ │ │引擎 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────┐
┌─────────────────────────────────────────────┐
│ 数据服务层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │向量数据库│ │知识图谱 │ │业务数据 │ │
│ │ │ │ │ │库 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────┘技术架构搭建详解
1. 系统集成架构
# AI-CRM系统集成架构
class AICRMIntegration:
def __init__(self):
self.mcp_server = EnterpriseMCPServer()
self.rag_system = EnterpriseRAGSystem()
self.agent_engine = AgentEngine()
self.data_layer = DataServiceLayer()
# 初始化各层
self._initialize_mcp_tools()
self._initialize_rag_knowledge()
self._initialize_agents()
def _initialize_mcp_tools(self):
"""初始化MCP工具"""
# 注册CRM相关工具
crm_tools = CRMToolRegistry(self.mcp_server)
crm_tools.register_all_tools()
def _initialize_rag_knowledge(self):
"""初始化RAG知识库"""
# 加载企业知识文档
documents = self.data_layer.load_enterprise_documents()
self.rag_system.ingest_documents(documents)
def _initialize_agents(self):
"""初始化AI Agent"""
# 创建销售Agent
sales_tools = self.mcp_server.get_tools_by_permission("sales")
self.sales_agent = SalesAgent(sales_tools, self.rag_system)
# 创建客服Agent
service_tools = self.mcp_server.get_tools_by_permission("customer_service")
self.service_agent = ServiceAgent(service_tools, self.rag_system)2. 智能销售助手核心实现
# 智能销售助手核心逻辑
class SmartSalesAssistant:
def __init__(self, mcp_tools, rag_system):
self.mcp_tools = mcp_tools
self.rag_system = rag_system
self.customer_analyzer = CustomerInsightAnalyzer()
self.recommendation_engine = ProductRecommendationEngine()
def handle_sales_task(self, task_type, customer_id, context):
"""处理销售任务"""
if task_type == "customer_analysis":
return self._analyze_customer(customer_id, context)
elif task_type == "product_recommendation":
return self._recommend_products(customer_id, context)
elif task_type == "followup_plan":
return self._create_followup_plan(customer_id, context)
def _analyze_customer(self, customer_id, context):
"""客户分析"""
# 查询客户信息
customer_data = self.mcp_tools["query_customer"].execute({"customer_id": customer_id})
# 分析客户行为
insights = self.customer_analyzer.analyze_customer_behavior(customer_data)
# 检索相关知识
knowledge = self.rag_system.process_query(f"客户分析 {customer_data['industry']}")
return {
"customer_profile": customer_data,
"behavior_insights": insights,
"industry_knowledge": knowledge,
"recommendations": self._generate_recommendations(insights, knowledge)
}
def _recommend_products(self, customer_id, context):
"""产品推荐"""
# 获取客户画像
customer_profile = self._analyze_customer(customer_id, context)
# 基于画像推荐产品
recommendations = self.recommendation_engine.recommend_products(
customer_profile, context
)
# 生成推荐理由
reasoning = self._generate_recommendation_reasoning(recommendations, customer_profile)
return {
"recommendations": recommendations,
"reasoning": reasoning,
"confidence": self._calculate_confidence(recommendations)
}3. 智能客服助手核心实现
# 智能客服助手核心逻辑
class SmartCustomerService:
def __init__(self, mcp_tools, rag_system):
self.mcp_tools = mcp_tools
self.rag_system = rag_system
self.escalation_manager = EscalationManager()
def handle_customer_query(self, customer_id, query, history):
"""处理客户查询"""
# 1. 知识检索
relevant_knowledge = self.rag_system.process_query(query)
# 2. 上下文理解
context = self._build_context(customer_id, history)
# 3. 智能生成回答
response = self._generate_response(query, relevant_knowledge, context)
# 4. 路由判断
escalation = self._should_escalate(response, query)
return {
"response": response,
"escalation": escalation,
"sources": relevant_knowledge["sources"],
"confidence": relevant_knowledge["confidence"]
}
def _generate_response(self, query, knowledge, context):
"""生成回答"""
prompt = f"""
基于以下信息回答客户问题:
客户问题:{query}
上下文:{context}
相关知识:{knowledge['answer']}
请用专业、友好的语气回答,如果信息不足请说明。
"""
return self._call_llm(prompt)
def _should_escalate(self, response, query):
"""判断是否需要人工介入"""
# 基于回答质量和问题复杂度判断
confidence = response.get("confidence", 0)
complexity = self._assess_complexity(query)
return confidence < 0.7 or complexity > 0.84. 系统配置文件
# ai-crm-config.yaml
system:
name: "AI-CRM-System"
version: "1.0.0"
environment: "production"
mcp:
server_url: "http://localhost:8000"
timeout: 30
retry_attempts: 3
rag:
vector_db:
type: "chroma"
host: "localhost"
port: 8001
embedding_model: "text-embedding-ada-002"
agents:
sales:
role: "sales_assistant"
max_steps: 8
tools: ["query_customer", "analyze_opportunity", "update_lead"]
customer_service:
role: "service_assistant"
max_steps: 6
tools: ["query_customer", "update_order", "create_ticket"]
data:
databases:
crm:
type: "postgresql"
host: "localhost"
port: 5432
database: "crm_db"
vector:
type: "chroma"
host: "localhost"
port: 8001
monitoring:
enabled: true
metrics_endpoint: "/metrics"
alert_rules:
- metric: "response_time"
threshold: 5000 # 5秒
severity: "warning"改造效果:3个月后的数据对比
| 指标 | 改造前 | 改造后 | 提升幅度 |
|---|---|---|---|
| 销售转化率 | 12% | 28% | +133% |
| 平均交易金额 | ¥15,000 | ¥23,500 | +57% |
| 销售周期 | 45天 | 28天 | -38% |
| 客服首次解决率 | 65% | 85% | +31% |
| 客户满意度 | 3.8/5 | 4.6/5 | +21% |
核心代码和配置详解
1. 客户洞察分析核心逻辑
# 客户洞察分析核心实现
class CustomerInsightAnalyzer:
def analyze_customer_behavior(self, customer_data):
"""分析客户行为模式"""
# 基于购买历史、浏览行为、互动频率等数据
# 构建客户价值评分和行为偏好模型
return {
"value_score": self._calculate_value_score(customer_data),
"preference_patterns": self._extract_preference_patterns(customer_data),
"engagement_level": self._assess_engagement_level(customer_data),
"churn_risk": self._calculate_churn_risk(customer_data)
}
def _calculate_value_score(self, customer_data):
"""计算客户价值评分"""
# 基于RFM模型(最近购买、购买频率、购买金额)
recency_score = self._calculate_recency_score(customer_data["last_purchase"])
frequency_score = self._calculate_frequency_score(customer_data["purchase_history"])
monetary_score = self._calculate_monetary_score(customer_data["total_spent"])
return (recency_score * 0.3 + frequency_score * 0.3 + monetary_score * 0.4)
def _extract_preference_patterns(self, customer_data):
"""提取客户偏好模式"""
patterns = {}
# 产品类别偏好
category_preferences = self._analyze_category_preferences(customer_data["purchase_history"])
patterns["category_preferences"] = category_preferences
# 价格敏感度
price_sensitivity = self._analyze_price_sensitivity(customer_data["purchase_history"])
patterns["price_sensitivity"] = price_sensitivity
# 购买周期
purchase_cycle = self._analyze_purchase_cycle(customer_data["purchase_history"])
patterns["purchase_cycle"] = purchase_cycle
return patterns2. 产品推荐引擎核心逻辑
# 产品推荐引擎核心实现
class ProductRecommendationEngine:
def recommend_products(self, customer_profile, context):
"""基于客户画像推荐产品"""
# 多维度匹配:行业适配、预算匹配、需求契合
# 结合实时上下文(如客户当前咨询内容)
return self._multi_criteria_matching(customer_profile, context)
def _multi_criteria_matching(self, customer_profile, context):
"""多标准匹配算法"""
all_products = self._get_available_products()
scored_products = []
for product in all_products:
# 行业匹配度
industry_match = self._calculate_industry_match(product, customer_profile)
# 预算匹配度
budget_match = self._calculate_budget_match(product, customer_profile)
# 需求匹配度
need_match = self._calculate_need_match(product, customer_profile, context)
# 综合评分
total_score = (industry_match * 0.4 + budget_match * 0.3 + need_match * 0.3)
scored_products.append({
"product": product,
"score": total_score,
"breakdown": {
"industry_match": industry_match,
"budget_match": budget_match,
"need_match": need_match
}
})
# 按分数排序并返回前5个
scored_products.sort(key=lambda x: x["score"], reverse=True)
return scored_products[:5]
def _calculate_industry_match(self, product, customer_profile):
"""计算行业匹配度"""
customer_industry = customer_profile.get("industry", "")
product_industries = product.get("target_industries", [])
if customer_industry in product_industries:
return 1.0
elif any(industry in customer_industry for industry in product_industries):
return 0.7
else:
return 0.33. 部署和运维配置
# deployment-config.yaml
api_gateway:
host: "api.crm.company.com"
port: 443
ssl_enabled: true
rate_limiting:
requests_per_minute: 1000
burst_limit: 2000
services:
mcp_server:
replicas: 3
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
rag_system:
replicas: 2
resources:
requests:
memory: "2Gi"
cpu: "1"
limits:
memory: "4Gi"
cpu: "2"
agent_engine:
replicas: 4
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1"
database:
postgresql:
host: "postgresql.crm.company.com"
port: 5432
database: "crm_production"
connection_pool:
min_connections: 10
max_connections: 100
chroma:
host: "chroma.crm.company.com"
port: 8000
persist_directory: "/data/chroma"
monitoring:
prometheus:
enabled: true
scrape_interval: "15s"
grafana:
enabled: true
dashboards:
- "ai-crm-overview"
- "agent-performance"
- "rag-system-metrics"
alerting:
enabled: true
rules:
- alert: "HighResponseTime"
expr: "avg_over_time(response_time_seconds[5m]) > 5"
for: "2m"
labels:
severity: "warning"
annotations:
summary: "High response time detected"4. 性能监控和指标追踪
# 性能监控核心实现
class AICRMMetrics:
def __init__(self):
self.metrics = {}
def track_sales_metrics(self):
"""跟踪销售指标"""
return {
'conversion_rate': self._calculate_conversion_rate(),
'average_deal_size': self._calculate_average_deal_size(),
'sales_cycle_length': self._calculate_sales_cycle(),
'customer_satisfaction': self._get_customer_satisfaction(),
'agent_success_rate': self._calculate_agent_success_rate()
}
def track_customer_service_metrics(self):
"""跟踪客服指标"""
return {
'first_contact_resolution': self._calculate_fcr(),
'average_handle_time': self._calculate_aht(),
'customer_satisfaction_score': self._get_cs_score(),
'escalation_rate': self._calculate_escalation_rate(),
'rag_accuracy': self._calculate_rag_accuracy()
}
def track_ai_performance(self):
"""跟踪AI性能指标"""
return {
'response_accuracy': self._calculate_accuracy(),
'recommendation_effectiveness': self._calculate_recommendation_effectiveness(),
'system_uptime': self._get_uptime(),
'user_engagement': self._calculate_engagement(),
'tool_usage_statistics': self._get_tool_usage_stats()
}你的企业如何开始AI转型?
第一步:找准切入点(不要贪大求全)
推荐从这些场景开始:
-
企业内部知识问答(技术文档、政策制度)
-
销售话术生成和优化
-
客服常见问题自动回答
-
会议纪要自动生成
选择标准:
-
业务价值明确
-
数据相对安全
-
技术实现简单
-
效果容易衡量
第二步:技术选型指南
根据企业规模选择:
-
初创企业:云服务方案(tongyi API + 向量数据库)
-
中型企业:混合方案(本地RAG + 云端大模型)
-
大型企业:本地部署方案(tongyi/deepseek等 + Chroma)
关键考量因素:
-
数据安全要求
-
技术团队能力
-
预算限制
-
性能要求
第三步:团队能力建设
需要哪些角色?
-
AI产品经理:理解业务,设计解决方案
-
提示词工程师:优化AI表现
-
数据工程师:处理企业数据
-
业务专家:验证AI输出
培养路径:
-
内部培训 + 外部专家指导
-
小项目实践 + 经验总结
-
建立AI应用最佳实践
第四步:风险控制
常见风险及应对:
-
数据安全:数据脱敏 + 权限控制 + 审计日志
-
算法偏见:定期检测 + 人工审核
-
系统可靠性:故障降级 + 人工兜底
-
合规要求:法律顾问审核 + 合规检查
未来展望:AI将如何重塑企业运营
技术趋势
-
多模态融合:文本、图像、语音的深度结合
-
自主性提升:从执行指令到主动发现问题
-
个性化增强:基于用户行为的深度定制
-
实时化处理:毫秒级响应的智能决策
业务影响
-
人机协作新模式:AI成为业务伙伴而非工具
-
组织架构重构:传统岗位转型,新岗位涌现
-
商业模式创新:基于AI的新产品和服务
-
竞争优势重塑:数据驱动的核心竞争力
立即行动:你的AI转型路线图
本周可以做什么?
-
识别1-2个高价值场景 - 哪个业务痛点最需要AI解决?
-
评估现有数据基础 - 有哪些数据可以用于AI训练?
-
组建小型试点团队 - 找3-5个对AI感兴趣的同事
-
选择技术方案 - 基于企业现状选择合适的技术栈
下个月的目标?
-
完成第一个试点项目 - 用AI解决一个具体业务问题
-
建立初步效果评估 - 量化AI带来的业务价值
-
制定扩展计划 - 基于试点经验规划下一步
-
培养内部能力 - 让更多同事了解和使用AI
半年后的期待?
-
AI成为业务标配 - 多个业务环节都有AI参与
-
建立AI治理体系 - 完善的安全、合规、运维机制
-
形成数据飞轮 - 更多数据 → 更好AI → 更多价值
-
培养AI文化 - 全员拥抱AI,主动寻找应用场景
常见问题解答
Q:我们没有技术团队,能做AI转型吗?A:完全可以。现在有很多低代码AI平台和SaaS服务,让业务人员也能快速上手。关键是先从小场景开始,积累经验。
Q:数据安全怎么保证?A:通过MCP等技术,可以实现数据不出企业、权限精细控制、操作全程审计。从低敏感度数据开始,逐步建立信任。
Q:投入产出比如何?A:从效率提升场景开始,通常3-6个月就能看到明显回报。关键是选择高价值、易实现的场景。
Q:需要多少预算?A:从小几万到几十万不等,取决于场景复杂度和技术方案。建议从低成本试点开始,验证价值后再扩大投入。
行动起来吧! AI转型不是技术竞赛,而是业务升级。从今天开始,选择一个你最想解决的业务问题,用AI来试试看。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









