



秒杀架构要把用户体验放在第一位,把数据安全当作底线,这样设计出来的系统,才能真正扛住“双11”的流量洪峰,也才能在面试中“打动面试官”。
今天咱们再来聊个面试场景题中的热门话题 — 秒杀架构如何扛住百万流量。
其实搭建秒杀架构不难,难的是:当瞬时流量远超日常 10-100 倍,如何在快速响应与系统稳定之间找到平衡?
下面就跟随牛哥一起看下 "一个又快又稳的秒杀架构,是怎么搭出来的”。
先拆需求,别上来就谈技术
面试时被问到秒杀架构,面试官第一个想知道的就是:你能不能把模糊的高并发拆解成可落地的具体指标?
其实拆解并不难,我们分成两个维度切入 — 从用户视角拆业务,从技术视角定指标。
1. 从用户视角拆业务
从用户点击 “立即抢购” 到收到成功短信,整个过程能拆成 6 个关键环节:
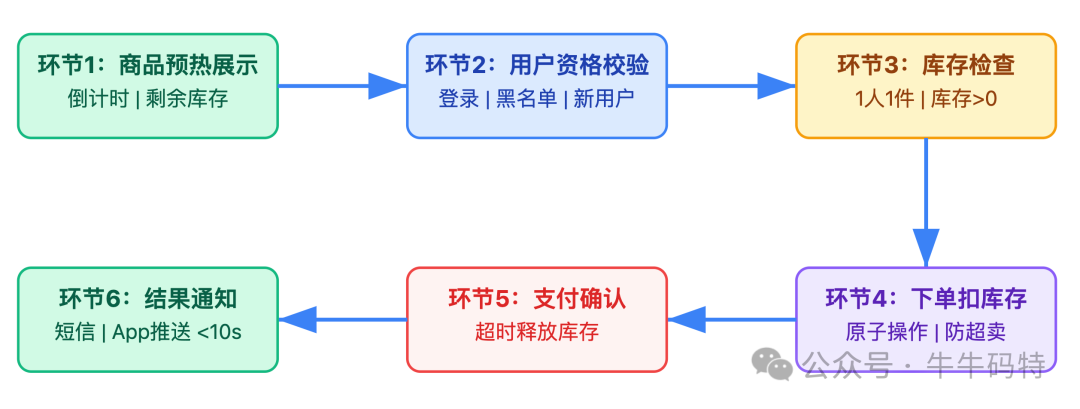
以上每个环节环环相扣:资格没通过,就不用查库存;库存不够,就不用创建订单。只有把流程拆细了,才能知道哪里该加拦截、哪里该做异步。
2. 从技术视角定指标
聊完用户视角,再来看看技术视角。就像医生看病要测体温,系统设计也得有健康指标:
2.1 并发能力指标
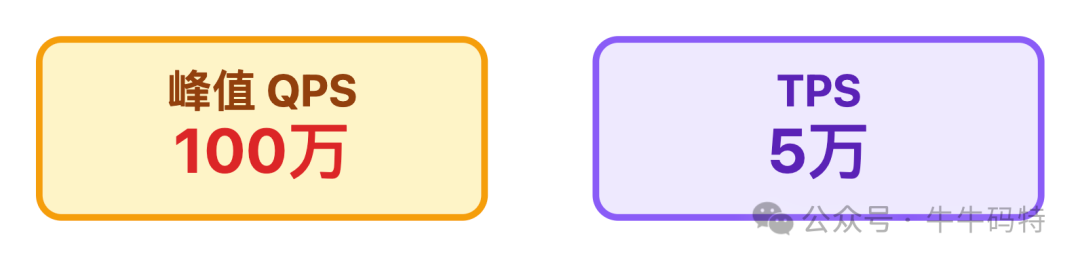
双 11 级别的秒杀,峰值 QPS 得扛住 100 万,核心 TPS 至少得 5 万,不然点击就卡顿。
2.2 稳定性指标
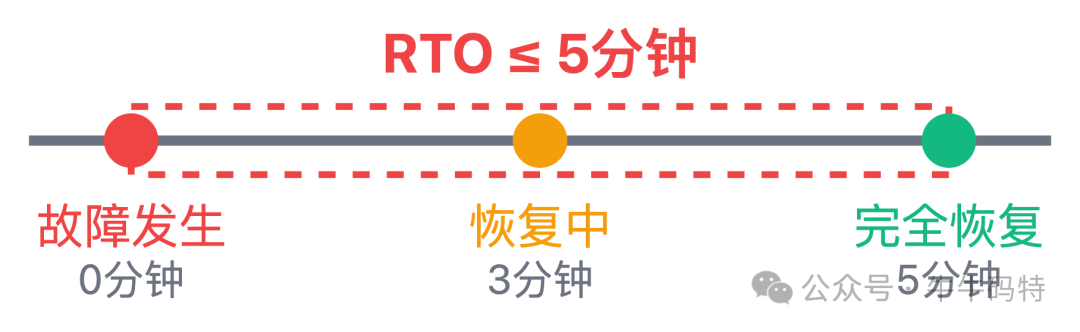
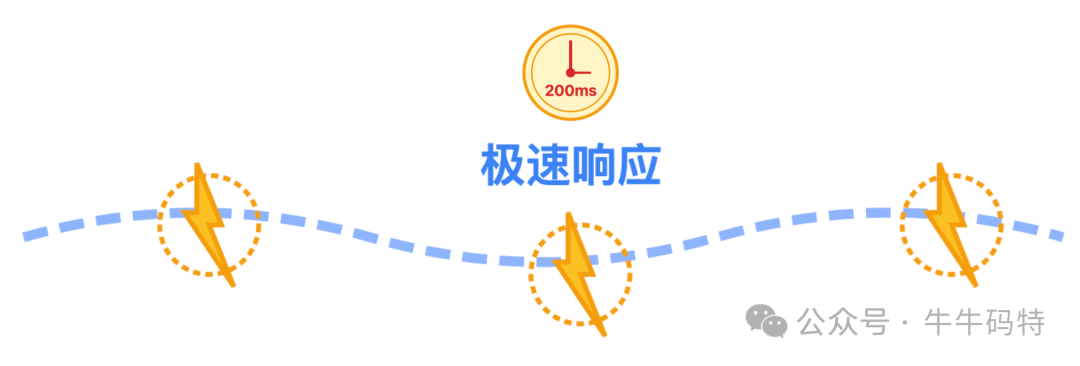
用户点抢购后,99% 的请求得在 200ms 内有回应。而且秒杀这种核心场景,故障恢复时间RTO必须 ≤ 5分钟,毕竟不能让用户干等半小时吧?
2.3 数据一致性指标
库存得 100% 准确,超卖 1 件都可能引发大量投诉。支付和订单状态也得同步快,延迟不能超 10 秒。
2.4 安全指标
防刷量得拦住 99% 以上的脚本,不然黄牛 10 秒就抢光 5000 件库存。黑名单用户必须 100% 拦住,绝对不能让他们再参与。

以上四个指标为秒杀类系统搭建了技术层面的健康衡量标准,后续设计也要以这些量化指标为基准。
架构搭建:秒杀系统的四层骨架
需求明确后,就可以搭架构了。接入层、流量削峰层、业务逻辑层、数据层这四层,每层各司其职,缺一不可。
1. 接入层:先把垃圾流量拦在门外
用户的请求第一个到的就是接入层,这里要是没拦住无效流量,后面的数据库、业务服务很快就会垮。
那该怎么选接入层的技术方案?
通常选用 「CDN + APISIX 网关」 组合。因为CDN能扛静态资源流量,APISIX 比 Nginx 更灵活,适合秒杀这种需要频繁调整规则的场景。

下面就来拆解这个组合:
1.1 CDN 加速
首先是静态资源全量加速,商品图、活动文案、倒计时动画这些静态内容,全扔到阿里云CDN。在北京访问,就从北京的 CDN 节点拿数据,在上海访问,就从上海的 CDN 节点拿数据,就近响应。
其次是设计地域路由,华北用户优先走华北网关、华东用户走华东网关,避免跨地域传输带来的延迟损耗。
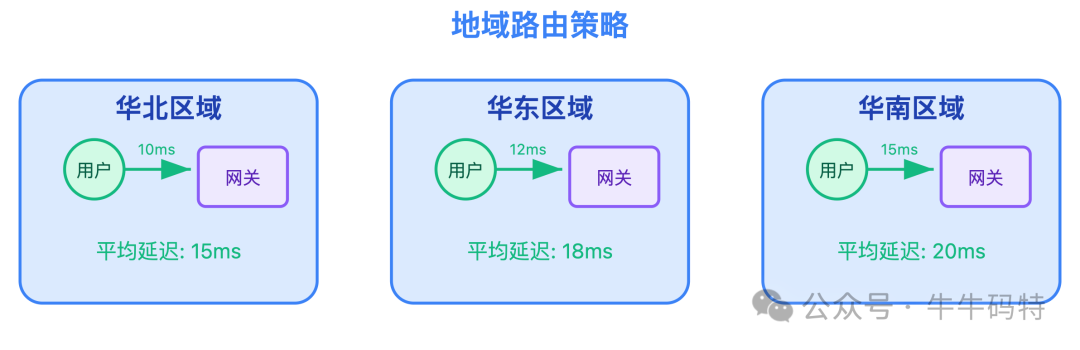
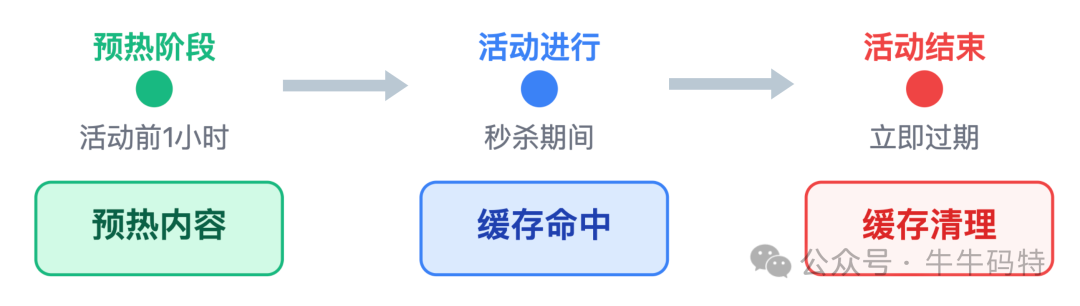
除此,还要注意 CDN 缓存的时效性:秒杀开始前 1 小时,先提前将商品详情页等静态页面 “预热” 到全国 CDN 节点,确保活动开启时用户能瞬间加载;活动结束后,立即给页面设置缓存过期,避免用户后续访问时看到旧的库存信息。
1.2 APISIX 精细化限流
用 APISIX 的令牌桶插件,可根据不同维度精准控制流量,避免 “一刀切” 式限流影响正常用户体验。
比如单 IP 每秒最多发 5 个请求,单用户 1 分钟最多点 10 次,没登录的直接拦住。

2. 流量削峰层:把"流量尖峰"压平
秒杀流量就像海啸,前 10 秒可能集中迸发 80% 的请求,直接打给业务系统,数据库肯定扛不住。
这一层的作用就是「缓冲 + 排队」,把 "10 秒 100 万请求" 变成 "10 分钟 100 万请求",让系统慢慢处理。

主要通过以下三个手段实现:
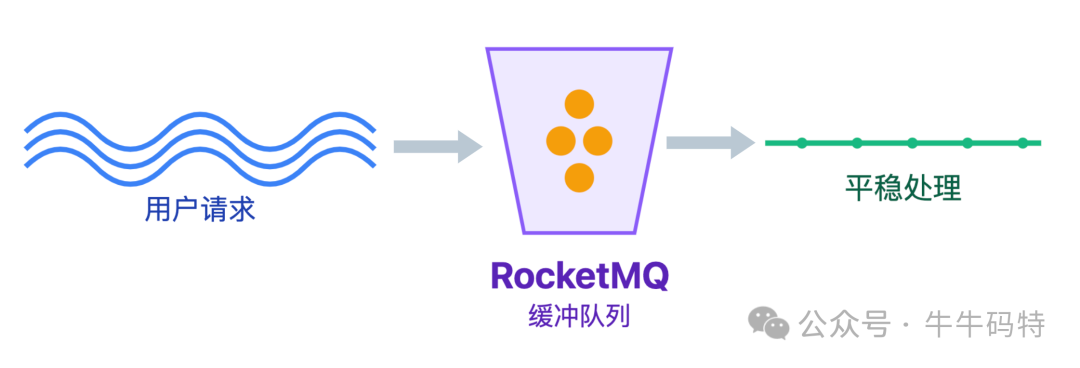
2.1 消息队列缓冲:流量的第一道减压阀
用户下单后的请求先丢进 RocketMQ,业务服务按自己的能力慢慢消费。
这里为什么选RocketMQ 而不是 Kafka?
因为它支持事务消息,能保证下单和扣库存同步,还能处理失败的请求,比 Kafka 更适合业务场景。但要注意,消息入队≠秒杀成功,必须告诉用户 "正在排队,别着急"。
2.2 用户排队机制:让等待可视化
光有 MQ 缓冲还不够,得让用户知道自己排在哪?要等多久?
排队机制用Redis的List结构做排队队列,用户请求进来时,会按以下步骤处理排队逻辑:
1)加入排队队列
# 将用户ID加入商品的排队队列
LPUSH seckill:queue:{productId} {userId}
2) 查询排队位置
# 查询当前队列长度(用户排队位置)
LLEN seckill:queue:{productId}
3) 反馈排队状态
计算预估等待时间,返回给前端 "当前排第 58 位,预计等待 2 分钟" 的提示。
这种明确的排队反馈能让用户知晓等待状态,有效减少因焦虑导致的重复刷新行为,可降低 30% 的无效请求。
2.3 MQ 积压处理:超预期时的应急方案
最后 MQ 积压也是个大问题,需要提前制定规则。例如制定如下规则:
平时消费组只开 1 个,要是单个 MQ 分区积压超 10 万条,就立刻加 2 个临时消费组,专门分流处理下单这类核心请求。

同时暂停 "秒杀成功通知" 这类非核心消费,把所有资源让给核心流程。
3. 业务逻辑层:高效处理核心流程
业务逻辑层堪称整个秒杀系统的“大脑”,既要处理核心业务逻辑,又得兼顾速度、准确性和稳定性。
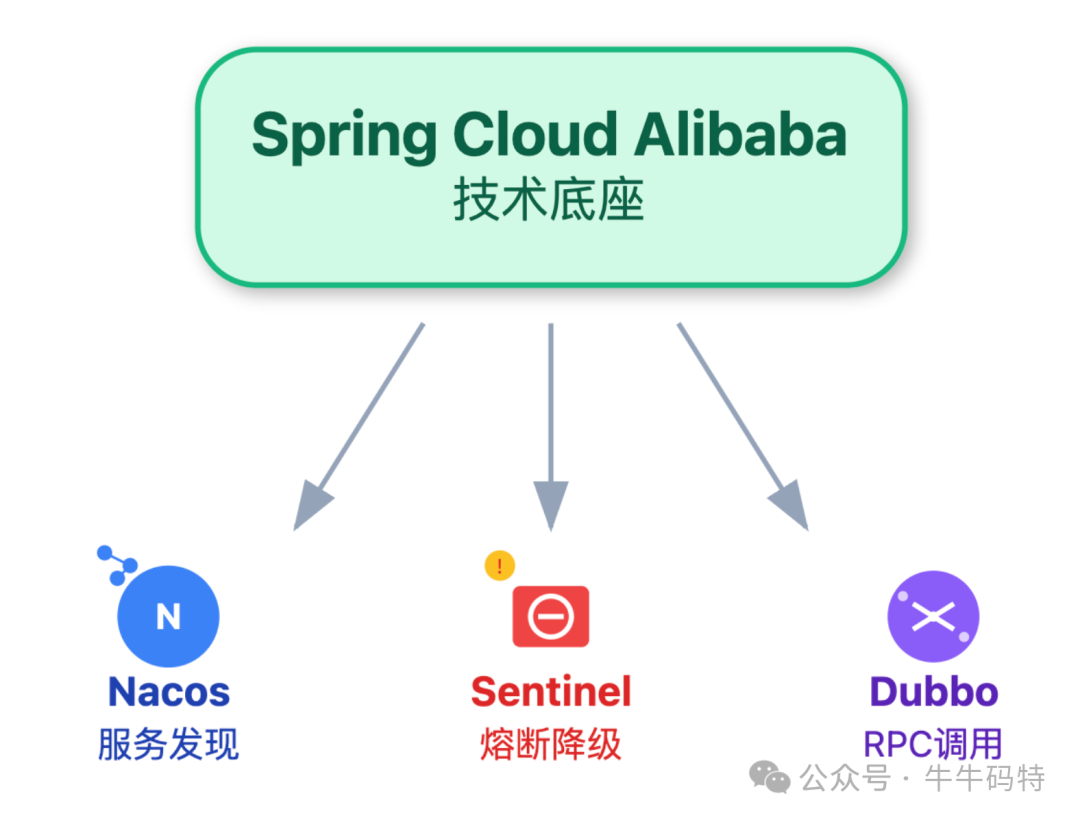
我们选择 Spring Cloud Alibaba 作为技术底座,这套生态把Nacos服务发现、Sentinel熔断降级、Dubbo RPC调用等核心能力都打包整合了,省去了自己拼凑组件的麻烦;
再搭配 Caffeine 本地缓存,存储用户等级、资格状态这类高频访问的小数据。
具体怎么设计呢?
首先是服务独立拆分 — 我们把秒杀业务拆成三个微服务。各自独立部署、单独扩容:
- 第一个是资格校验服务:专门负责检查用户是否登录、是否在黑名单、是否已经参与过秒杀;
- 第二个库存扣减服务:专注处理Redis预扣库存和MySQL最终确认扣减的逻辑;
- 第三个订单生成服务:负责创建订单、对接支付渠道等后续流程。

这样拆分的好处很明显:就算订单服务临时出问题,资格校验和库存扣减服务还能正常工作,不会出现 "一挂全挂" 的连锁故障。
其次是内存快速校验:把用户等级、历史购买记录等资格校验规则,全放进 Caffeine 本地缓存。
缓存的 Key 设计成「用户ID + 商品ID」,value 直接存「是否有资格」的值,过期时间设为30分钟。
缓存代码示例:
// 使用Caffeine更新本地缓存(用户秒杀资格)
caffeineCache.put(
"user:12345:product:67890:qualification"
, true); // true表示用户12345对商品67890有秒杀资格
// 从Caffeine缓存查询用户秒杀资格
booleanhasQualification= caffeineCache.getIfPresent(
"user:12345:product:67890:qualification"
);
查询时先查本地缓存,查不到再按 "Redis→数据库" 的顺序校验,三级缓存下来,平均耗时大大提升。
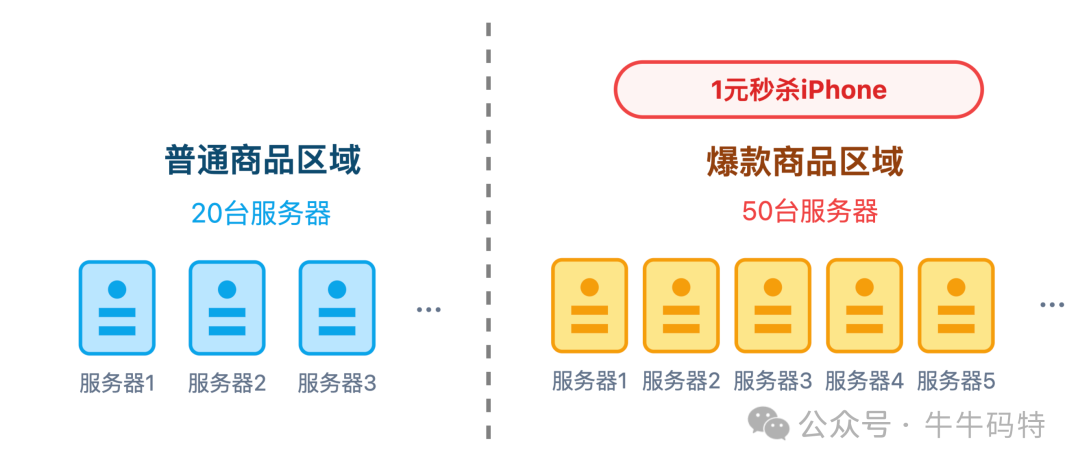
最后是热点隔离:像 1 元秒杀手机这种爆款商品,请求流量大,必须单独处理。
比如其他商品用 20 台服务器支撑,爆款就配 50 台,让热门请求和普通请求分开处理,避免一个商品拖垮整个系统。
4. 数据层:支撑高读写
数据层是“弹药库”,既要扛住高读写,又不能出错。这一层用 Redis Cluster 存热数据,MySQL 存冷数据,Sharding-JDBC 做分库分表,分工明确。
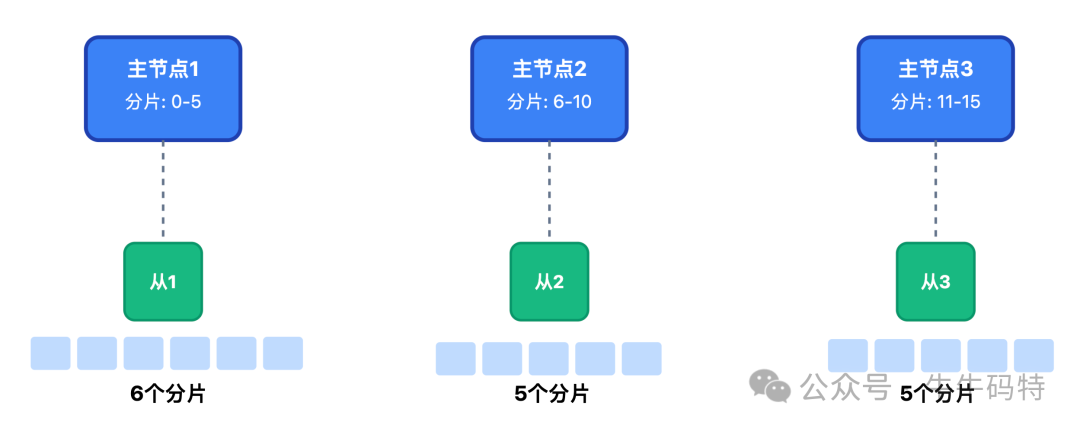
4.1 Redis 存热数据
实时库存、用户排队位置、资格校验结果全放Redis。用 3 主 3 从、16 个分片的架构,单个分片 QPS 能到 5 万,16 个就是 80 万,足够扛秒杀。
4.2 MySQL 存冷数据
MySQL 存订单、支付记录这些要长久保存的数据,用 Sharding-JDBC 按商品 ID 哈希分为 8 个库,每个库再分 16 张表,总共 128 张表。
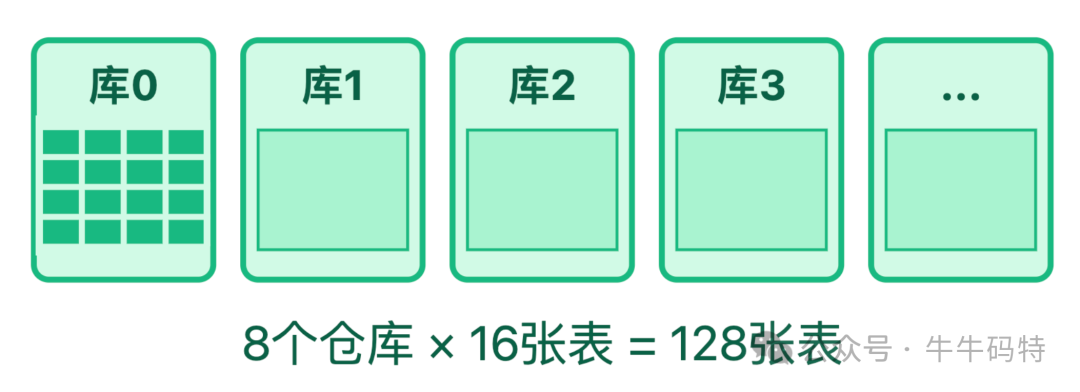
这样单表数据量能控制在 50 万以内,要是不分表,单表超 1000 万就慢了,查询速度提升 5 倍。
4.3 读写分离
MySQL 主库只负责创订单、扣库存等写操作,从库负责查订单、查支付状态等读操作。用 Sharding-JDBC 的插件,读请求自动分给从库,主库压力能降 40%。
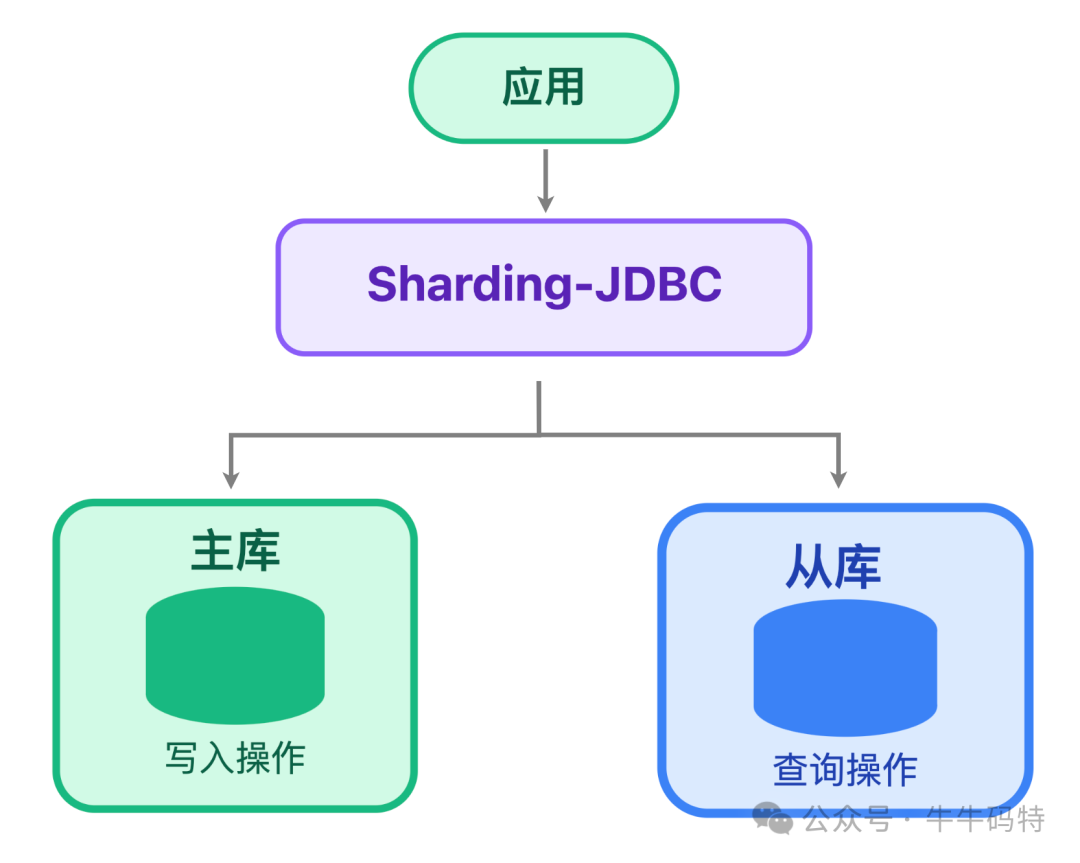
但主从同步有 1-3 秒延迟,你刚下单可能查不到订单,所以得提示 “订单创建中,10 秒后再查"。
通过这四层配合,既扛住了高并发,又保证了数据准确与用户体验。
关键细节:这些坑一定要避开
架构搭好了,还得填“细节坑”。秒杀出问题,往往不是架构不对,而是细节没处理好,以下几个细节不仅是面试高频考点,也是线上事故的重灾区。
细节1:防超卖
面试官常问:“怎么保证绝对不超卖?” 这问题看似简单,实则藏着并发编程的“魔鬼细节”。
超卖的根源是多个线程同时读库存、扣库存,导致数据不一致。
解决方案是选择 「Redis预扣+MySQL乐观锁」。
1.1 Redis 预扣库存
秒杀开始前,先把库存加载到Redis;用户下单时,再用Lua脚本原子扣减库存,避免并发问题。
Lua 脚本示例:
-- 1. 秒杀开始前加载库存到Redis
-- KEYS[1] = "seckill:stock:{productId}"(库存Key)
-- ARGV[1] = 初始库存数量(如1000)
redis.call("HSET", KEYS[1], "available", ARGV[1])
-- 2. 用户下单时原子扣减库存(与加载使用相同的KEYS[1])
-- KEYS[1] = "seckill:stock:{productId}"(库存Key)
-- ARGV[2] = 购买数量(如1)
local available = redis.call("HGET", KEYS[1], "available")
ifnot available ortonumber(available) < tonumber(ARGV[2]) then
return0-- 库存不足,返回0
end
redis.call("HINCRBY", KEYS[1], "available", -tonumber(ARGV[2])) -- 扣减库存
return1-- 扣减成功,返回1
为什么用Lua脚本?因为它能保证多个Redis命令的原子性执行,避免中间被其他请求打断。这是防超卖的第一道防线。
1.2 MySQL 乐观锁最终确认
Redis扣减成功后,得落库才算数。库存表设计时加个version字段,扣减时对比版本号:
SQL 示例:
-- 扣减逻辑:仅当版本号匹配、库存充足时才更新,同时版本号自增
UPDATE seckill_stock
SET
available_stock = available_stock -1,
version = version +1
WHERE
product_id = #{productId}
AND available_stock >=1-- 确保库存足够
AND version = #{version}; -- 乐观锁版本匹配
执行后看影响行数:
- 若影响行数 = 1 表示 MySQL 库存扣减成功,流程正常推进;
- 若影响行数 = 0 表示其他请求已抢先扣减库存,需回滚 Redis 库存:
细节2:缓存优化
缓存是秒杀的性能引擎,但用不好就成定时炸弹。最常见的缓存问题有:穿透、击穿和雪崩,下面讲讲怎么解决。
2.1 缓存穿透
缓存穿透表现为:
当用户请求不存在的商品ID 时,缓存与数据库均无数据,请求会持续穿透到数据库。
可以通过拦截无效请求解决缓存穿透,核心手段是「布隆过滤器 + 缓存空值」双重拦截:
- 布隆过滤器前置过滤:秒杀开始前,将所有参与秒杀的商品ID加载到布隆过滤器。请求进来时先过过滤器,若商品ID不存在,直接返回 "商品不存在",从源头拦截无效请求;
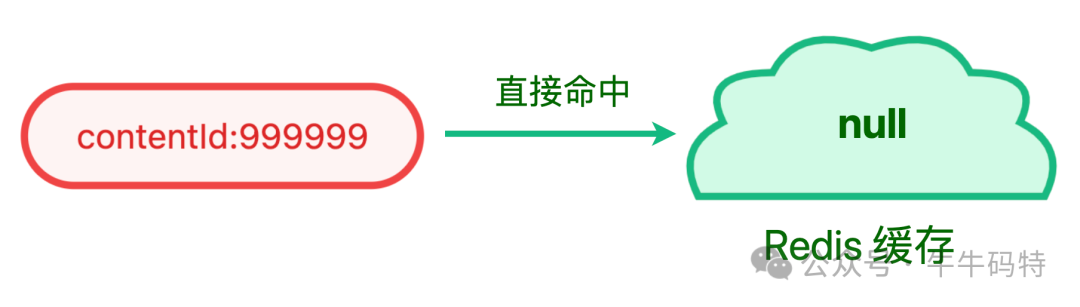
- 缓存空值兜底:考虑到布隆过滤器有约 0.1% 的误判率,所以要缓存空值兜底,如缓存 productId = 999999 的值为 null,并设置1分钟过期时间,避免同类无效请求在 1 分钟内反复穿透数据库,同时也减少 Redis 空值缓存的资源占用
2.2 缓存击穿
缓存击穿表现为:
某个爆款商品的缓存 key 突然过期,数十万请求会瞬间涌向数据库。
我们要做的就是 "守护" 热点key,用「分布式互斥锁 + 热点Key永不过期」应对:
- 分布式锁控制查询:借助 Redisson 实现可靠的分布式锁,第一个请求拿到锁后查询数据库并更新缓存,这时候其他请求处于等待的状态,避免多个请求并发查库。Java 代码示例:
RLocklock= redissonClient.getLock("lock:product:" + productId);
try {
// 5秒内尝试获取锁,拿到锁后30秒自动释放(防止死锁)
if (lock.tryLock(5, 30, TimeUnit.SECONDS)) {
Productproduct= productMapper.selectById(productId);
// 更新缓存,设置1小时过期(仅非热点Key用,热点Key后续特殊处理)
redisTemplate.opsForValue().set("product:" + productId, product, 1, TimeUnit.HOURS);
return product;
} else {
// 未拿到锁,重试读取缓存(等待其他请求更新后再查)
return redisTemplate.opsForValue().get("product:" + productId);
}
} finally {
// 确保锁释放,避免内存泄漏
if (lock.isHeldByCurrentThread()) lock.unlock();
}
- 热点Key永不过期:对爆款商品这类热点Key,代码层不设置主动过期时间,而是用定时任务每30分钟异步查询数据库更新缓存,从根本上避免过期瞬间的流量冲击。
2.3 缓存雪崩
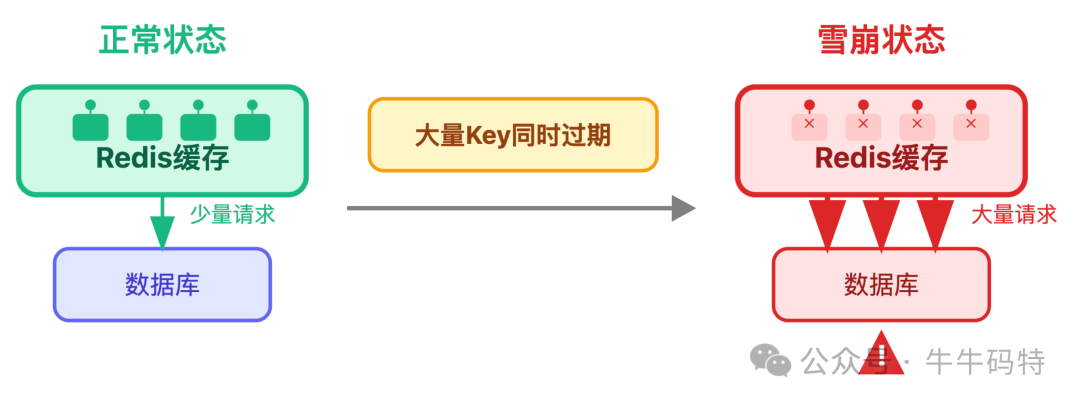
缓存雪崩则表现为:
大量商品缓存 key 在同一时间过期,数据库会被集中请求压垮。
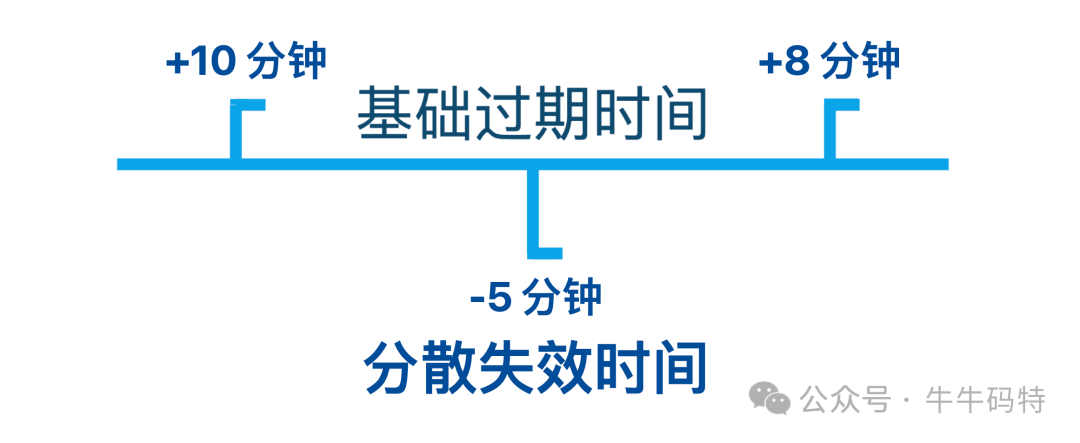
为了避免大量请求同时间过期,我们通过「过期时间随机化 + 本地缓存兜底」化解:
- 过期时间随机化:给每个缓存的基础过期时间加上 ± 10分钟的随机值,让缓存失效时间分散,避免集中过期;
- 本地缓存兜底:即便 Redis 缓存过期,通过应用本地的 Caffeine 缓存兜底,仍能直接返回数据,无需请求 Redis。
细节3:分布一致性
分布式系统里,绝对一致是不可能的,网络延迟、节点故障都会导致数据暂时对不上,关键是要 「最终一致」,别出现 “付了钱没订单”“扣了库存没下单” 的情况。
为实现这一目标,我们主要通过轻量化 TCC 事务、消息队列最终一致、实时对账任务三种方案分层保障
3.1 轻量化 TCC 事务:保障短事务
秒杀下单是典型的短事务,流程简单、执行时间短,用轻量化的 TCC(Try-Confirm-Cancel)事务再合适不过:
- Try 阶段:不直接修改核心数据,只做资格校验和预扣 Redis 库存
- Confirm 阶段:若 Try 阶段无问题,正式执行核心操作 — 从 MySQL 中扣减实际库存,同时生成订单数据
- Cancel 阶段:若 Try 阶段后出现异常,如用户支付超时、库存不足,则执行回滚操作 — 回滚 Redis 库存、删排队记录。
不过 TCC 的难点在于要写很多补偿代码,比如 Cancel 失败了要设置重试确保最终回滚。
3.2 消息队列:应对断连情况
秒杀高峰期可能出现服务断连,此时单靠 TCC 难以保障数据一致,需借助 RocketMQ 的事务消息能力,确保订单创建与库存扣减的最终同步:
订单创建后,先发一条事务消息到 RocketMQ,库存服务读取消息后执行「扣库存」操作。要是扣库存失败,消息会自动重试 3 次,3次都失败后就进入死信队列,人工处理。
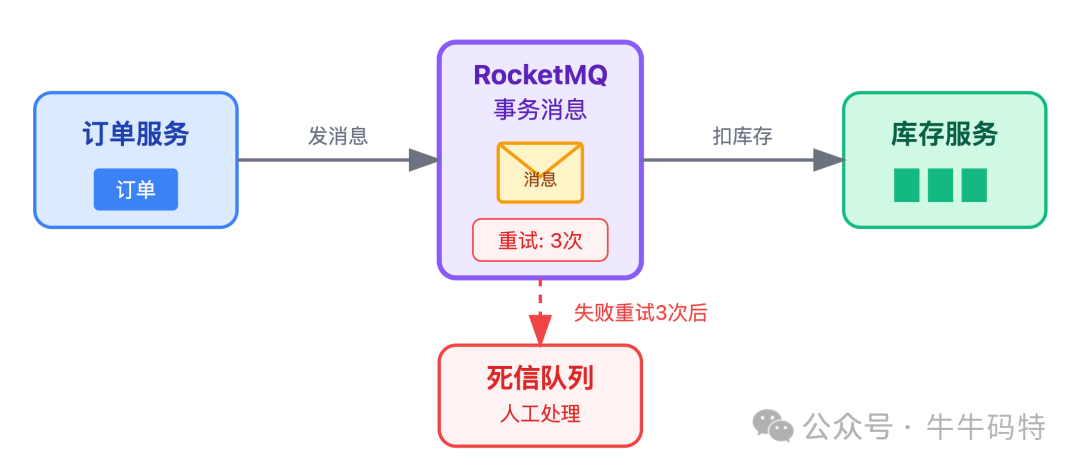
这样能确保「订单创建」 和 「库存扣减」 要么都成功,要么都失败,不会出现数据不一致。
3.3 实时对账任务:最后一道防线
即使有 TCC 和事务消息,仍可能因极端场景出现 「Redis 库存与 MySQL 库存不一致」 的情况。因此需要一套实时对账任务,修正数据偏差:
每分钟触发一次对账任务,对比 Redis 与 MySQL 的库存差异:
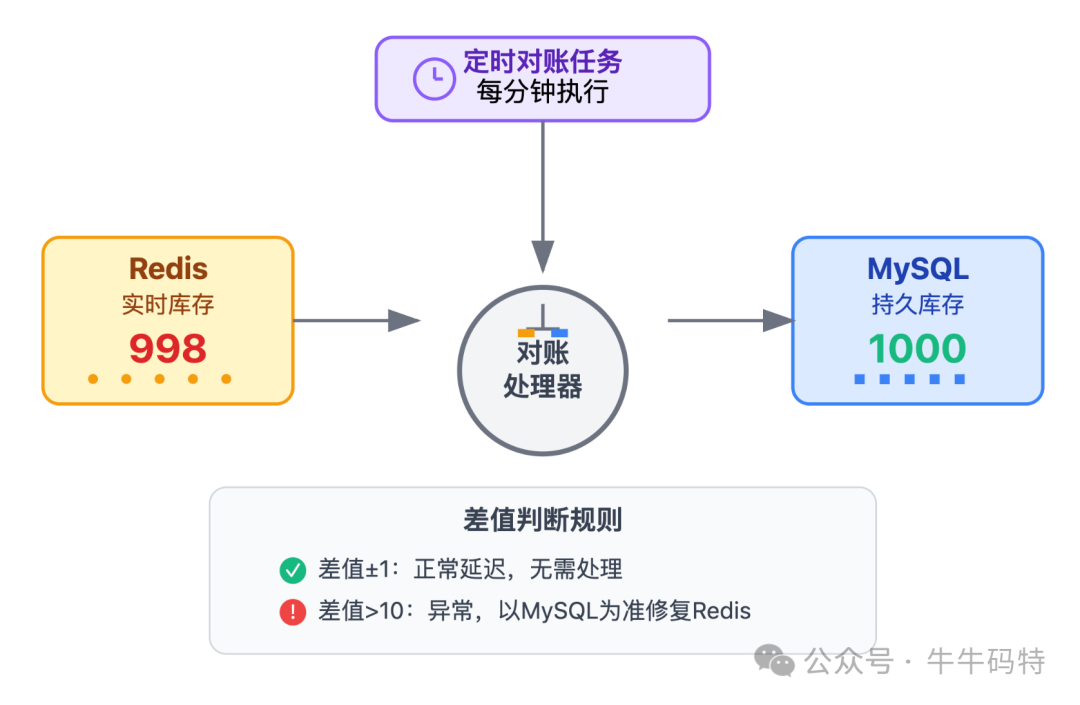
- 若差值在合理范围(如±1),视为正常延迟,无需处理;
- 若差值超过10,则以 MySQL 数据为准修复 Redis 库存,确保双端数据最终一致。
优化方向
优化不是炫技,而是解决用户痛点、降低成本,"让用户抢得爽、让公司少花钱" 这才是优化的价值,我们从三个优化方向切入:
优化1:无效请求提前过滤
秒杀场景下,90%的请求都是无效的,比如重复点击、没资格、库存不足,提前过滤能“减负增效”。因此需要在接入层、应用层各加过滤规则:
|
过滤阶段 |
规则示例 |
过滤效果 |
|
接入层 |
单IP每秒>5请求、User-Agent异常(脚本标识) |
挡掉30%无效请求 |
|
应用层 |
未登录用户、黑名单用户、已秒杀用户 |
挡掉50%无效请求 |
以「已秒杀用户过滤」 为例,我们用 Redis 的 Set 结构记录参与过的用户,用户每次下单前,先通过SISMEMBER命令判断是否在 Set 中,若存在,直接返回 "您已参与过本次秒杀",仅这一条规则就能让重复下单请求降低 80%。
优化2:异步处理提速
用户下单后,发短信、推App通知、更新用户积分,这些操作用户不关心实时性,完全可以异步处理。
我们用 RocketMQ 的普通消息队列(非事务消息),下单成功后直接向 RocketMQ 发送一条普通消息,后台服务根据自身处理能力逐步消费。
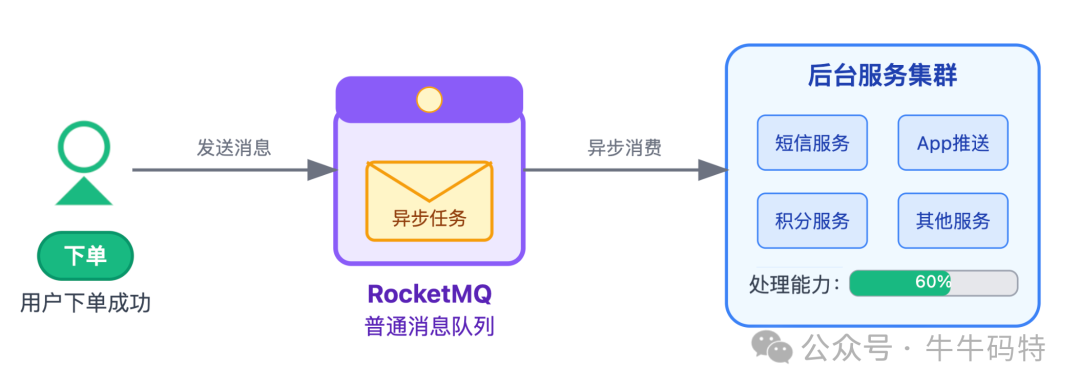
优化3:跟着流量弹性扩容
云时代了,还手动扩容就太原始了。用 K8s 的 HPA 自动扩缩容,资源跟着流量变:秒杀前 10 分钟,HPA 会自动扩到 10 个实例;活动结束 5 分钟,CPU 降下来了,又缩回 2 个。
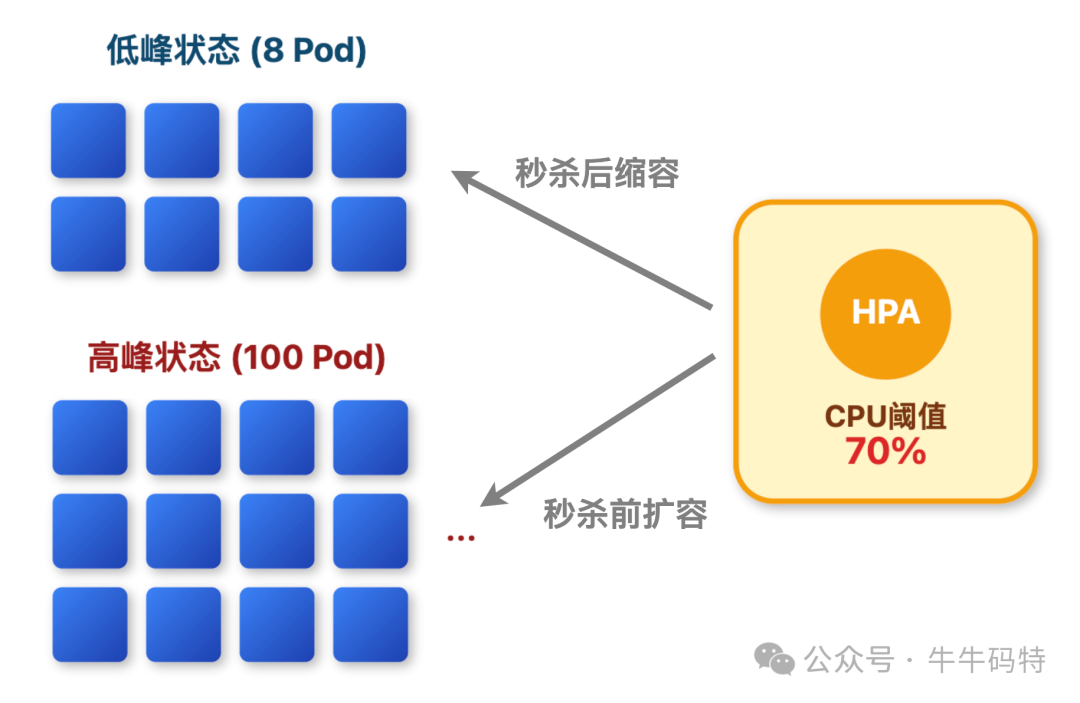
既保证性能,又不浪费资源,每月能省 40% 的服务器成本。
除此以外,监控和容灾也必不可少,“三分技术,七分运维”。因此需要通过全链路监控、混沌工程演练、降级预案三者结合筑牢系统稳定性。
总结:秒杀架构的设计心法
回顾整个秒杀架构设计,我提炼出了四个核心原则:
1. 流量拦截要“前置”:CDN挡静态、网关限流量、排队筛用户,把无效请求挡在越上游越好,别让它们“走到数据库门口才被拦下”。
2. 数据一致是“底线”:Redis原子扣减、MySQL乐观锁、TCC事务、实时对账,这四重保障缺一不可,超卖1件,对用户来说就是“整个活动不可信”。
3. 监控容灾“不偷懒”:全链路监控、混沌演练、降级预案,这三件事做扎实了,线上出问题也能兜底。
4. 持续优化“不停步”:没有“一劳永逸”的秒杀系统,流量变了、业务变了,架构就得跟着变。去年的方案今年可能就不适用,持续迭代,才能真正做好秒杀。
最后想说,秒杀架构要把用户体验放在第一位,把数据安全当作底线,这样设计出来的系统,才能真正扛住“双11”的流量洪峰,也才能在面试中“打动面试官”。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









