



当你被 Agent 的行为所困扰时,记住,问题很可能出在缺失的工具、模糊的提示或不足的上下文,而不是模型本身的局限性。
随着 AI Agent 技术的兴起,许多开发者都投入到构建智能体的浪潮中,但很快就会发现,让 Agent 稳定、可靠地工作远非想象中容易。它们时而产生幻觉,时而偏离轨道,时而做出一些令人费解的“愚蠢”行为。最近,来自 app.build 的 Arseni Kravchenko 分享了他们在构建生产级 AI Agent 过程中总结出的六大核心工程原则。这些原则摒弃了虚无缥缈的“提示词黑魔法”,回归到坚实的软件工程基础。对于正在或计划使用 Go 构建 AI Agent 的开发者来说,这是一份宝贵的实践指南。

原则一:投资你的系统提示 (System Prompt)
许多人对“提示词工程”持怀疑态度,认为它充满了“我奶奶快不行了,请帮帮我”之类的奇技淫巧。然而,作者指出,现代 LLM 真正需要的是直接、详细、清晰且无矛盾的上下文,而非情感操控。
对于开发者而言,你要做的就是不要耍小聪明,要把系统提示当作给 Agent 的API 文档来写。
当你为 Agent 提供一个通过 os/exec 调用的工具时,不要只告诉它工具的名字。在系统提示中清晰地说明:
- 工具的完整命令是什么。
- 每个参数的含义、类型和格式。
- 预期的输出格式以及如何解析它。
- 前置条件和错误情况。
一个详尽的系统提示是 Agent 可靠行为的基石。
原则二:拆分上下文 (Split the Context)
“上下文工程”是比“提示词工程”更重要的概念。巨大的、单一的上下文不仅成本高、延迟大,还会导致模型出现“注意力衰减”,忽略掉关键信息。
作者建议大家:默认只提供最少必要知识,并通过工具让 Agent 在需要时主动获取更多上下文。
与其在初始提示中塞入整个项目的源代码,不如:
- 提供文件列表:在提示中只给出项目的文件树结构。
- 提供
read_file工具:让 Agent 在需要时,通过调用这个工具来读取特定文件的内容。 - 上下文压缩:在 Agent 的反馈循环中,主动使用工具(甚至另一个 LLM)来压缩和总结日志、工具输出等动态信息,避免上下文无限膨胀。

如上图所示,将一个庞大的任务分解为多个具有专注上下文的、可编排的子任务,是构建高效 Agent 的关键。
原则三:精心设计你的工具 (Design Tools Carefully)
工具是 AI Agent 的核心。设计给 Agent 用的工具,比设计给人用的 API 更具挑战性,因为 LLM 不会“读心术”,它们会毫不留情地滥用你留下的任何漏洞。
作者建议:把你的 Agent 当成一个聪明但容易分心的初级开发者,为它设计 API:
- 保持粒度一致:工具(函数)应该有相似的抽象层次。不要混用一个
read_byte和一个deploy_to_kubernetes。 - 限制数量和参数:一个典型的工程 Agent 通常只有不到 10 个核心工具,每个工具只有 1-3 个严格类型的参数。
- 追求幂等性:尽可能让工具是幂等的,这可以极大地简化 Agent 的状态管理和错误恢复逻辑。
- 清晰、无歧义、无冗余:确保没有两个工具的功能是重叠的,这会让 LLM 感到困惑。
原则四:设计一个反馈循环 (Design a Feedback Loop)
一个没有验证和反馈的 Agent 是不可靠的。优秀的 Agent 系统总是将 LLM 的创造力与传统软件的严格性结合起来,形成一个“演员-评论家”(Actor-Critic)模型:让 LLM Actor 自由创造,让严格的 Critic 程序来验证。
对于开发者来说,这是一个天然的优势领域!
- Actor (LLM):负责生成代码、配置文件或执行计划。
- Critic:负责执行一系列自动化验证:
- 代码能否编译通过?
- 代码能否通过测试?
- 代码是否符合静态检查规范?
- 领域特定不变量:例如,如果 Agent 修改了订单系统,是否依然满足“订单总价等于所有商品价格之和”这个业务规则?
这个反馈循环不仅能过滤掉错误的输出,更是 Agent 学习和改进的基础。
原则五:用 LLM 驱动错误分析
当 Agent 失败时,手动排查海量的日志是不现实的。我们可以构建一个“meta Agent”来解决这个问题,即让另一个 LLM 来分析失败 Agent 的日志,找出问题的根源。
流程:
- 建立一个基线版本的 Agent。
- 部署多个实例并收集它们的执行轨迹和日志。
- 将失败的日志喂给一个具有更大上下文窗口(如 Gemini 1.5 Pro)的 LLM进行分析。
- 根据 LLM 的分析洞察,改进基线 Agent 的系统提示、工具或上下文管理。
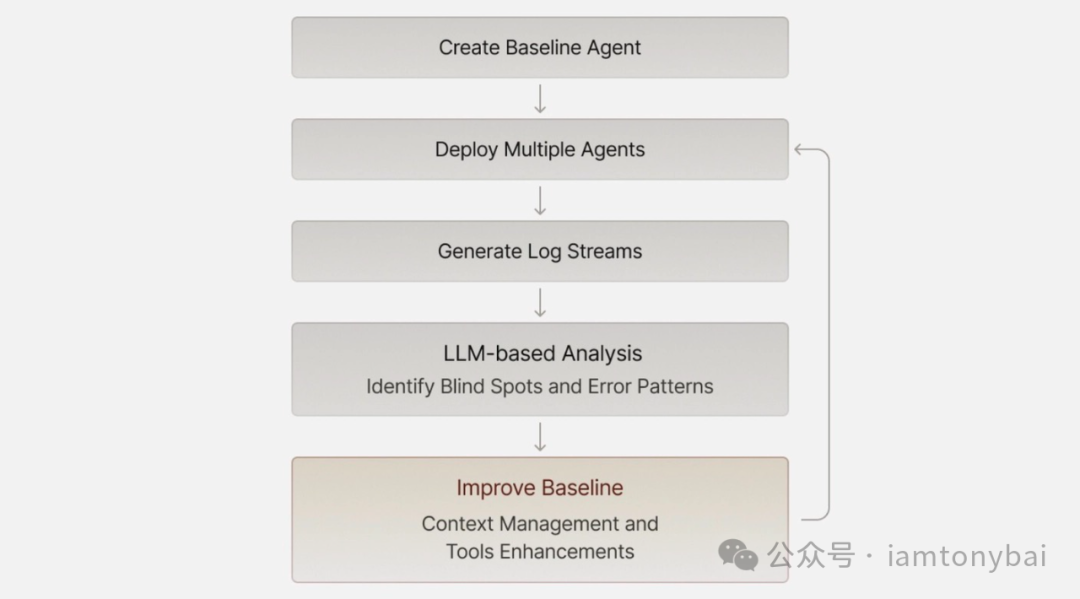
这个元循环能高效地发现我们自己可能忽略的系统性问题。
原则六:令人沮丧的行为是系统问题的信号
当 Agent 做出一些“愚蠢”的行为,比如忽略你的明确指令,或者用一种奇怪的方式绕过问题时,我们的第一反应通常是“这个模型真笨”。
但作者建议:先调试你自己的系统,再怪罪模型。
作者分享了一个亲身经历:他明确要求 Agent 使用一个集成工具来获取数据,但 Agent 却固执地使用模拟的随机数据。在愤怒地检查日志后,他发现自己忘了给 Agent 配置正确的 API 密钥。Agent 尝试调用工具,连续失败,最后只能选择一个它能走的通的、但却是错误的路径。
因此,当你的 Agent 行为异常时,请检查一下:
- 工具是否缺失? 它是否需要一个
write_file的能力而你没有提供? - 提示是否模糊? 你是否清晰地解释了工具的用法和边界?
- 上下文是否充分? 它是否因为缺少必要信息(比如一个 API 密钥或文件权限)而无法执行任务?
小结
构建有效的 AI Agent,关键不在于寻找一个能解决所有问题的“银弹”提示或高级框架。它回归到了系统设计和严谨的软件工程。
作为开发者,我们应该聚焦于:
- 清晰的指令(通过系统提示)
- 精简的上下文管理(通过工具和压缩)
- 健壮的工具接口(简单、幂等、无歧义)
- 自动化的验证循环(编译、测试、静态检查)
当你被 Agent 的行为所困扰时,记住,问题很可能出在缺失的工具、模糊的提示或不足的上下文,而不是模型本身的局限性。将错误分析视为开发过程中的一等公民,我们的目标不是构建一个从不犯错的完美 Agent,而是构建一个可靠的、可恢复的、能够优雅地失败并被我们迭代改进的Agent
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









