




传统多智能体系统需联合训练多个模型,成本高昂。本文介绍的MLPO框架另辟蹊径——仅训练一个"领导者"协调未训练的智能体团队,不仅推理效率提升,甚至在单模型部署时也超越传统方法。这项研究为高效、可扩展的协作智能提供了全新思路。

大家好,我是肆〇柒。大语言模型(LLM)在翻译、问答等任务中展现了卓越能力,但其在事实准确性与复杂推理上仍存在显著缺陷。为弥补这一短板,多智能体(Multi-Agent)范式被研究者提出:通过多个LLM协同工作(如辩论、验证、纠错),利用集体智慧超越单一模型的局限。这一思路已被证明有效,例如通过多模型辩论提升事实性。
然而,现有方法面临严峻挑战。首先,计算成本高昂。像ACC-Collab和SCoRe这类方法需要联合训练多个模型,其训练开销与模型数量呈线性甚至更高增长,难以扩展。其次,部署缺乏灵活性。大多数方案要求所有智能体在推理时必须在线,这不仅增加了延迟,也限制了在资源受限场景下的应用。最后,许多方法(如多智能体辩论)依赖于"涌现行为",即假设通用大模型天生具备协作能力,而未对其进行显式训练与优化,其协作效果不稳定且不可控。
这引出了一个根本性的矛盾:
- 一方面,显式训练多个模型(如ACC-Collab)能有效提升协作性能,但计算成本高昂,难以扩展;
- 另一方面,不训练模型(如MAD)虽然成本低,但协作效果依赖于涌现,性能上限有限且不可控。
因此,一个更根本的问题是:我们能否找到一种方法,既拥有显式训练带来的性能提升,又避免训练多个模型的高昂成本?
由字节跳动Seed提出的MLPO(Multi-agent guided Leader Policy Optimization)框架,正是对这一问题的有力回答。它提出了一种分层、高效且灵活的协作推理新范式,其核心在于训练一个"领导者"来协调一群"未训练的智能体"。
方法论:MLPO框架
整体架构:分层多智能体系统
MLPO的核心思想是构建一个分层的多智能体系统,其结构简洁而高效:一个领导者(Leader) + K个未训练的智能体(Agents)。
- 领导者(Leader):这是系统中唯一被训练的模型。它的核心职责是接收来自智能体团队的多样化响应,对其进行批判性评估、聚合与综合,最终生成一个高质量的结构化答案。
- 智能体团队(Agent Team):由K个现成的、未经训练的LLM(如论文中使用的Llama 3.1、Gemma2、Qwen2.5)组成。它们的角色是作为"思想贡献者",提供多样化的初步解决方案。
这一设计带来了两大核心优势。首先是训练效率的革命性提升。传统的多智能体训练方法需要同步优化多个大模型,计算成本极高。而MLPO仅需优化一个领导者模型,其余智能体保持冻结,这使得训练过程变得轻量且可扩展。其次是部署的极致灵活性。训练完成的领导者具备双重身份:它既可以作为一个强大的独立模型进行零样本(zero-shot)推理,无需任何智能体参与;也可以在需要更高精度时,与智能体团队协同工作,实现性能的进一步跃升。
推理流程:迭代式反馈与精炼
MLPO的推理过程是一个精心设计的T轮迭代循环(如下图所示),形成了一个领导者与智能体团队之间的闭环反馈系统。
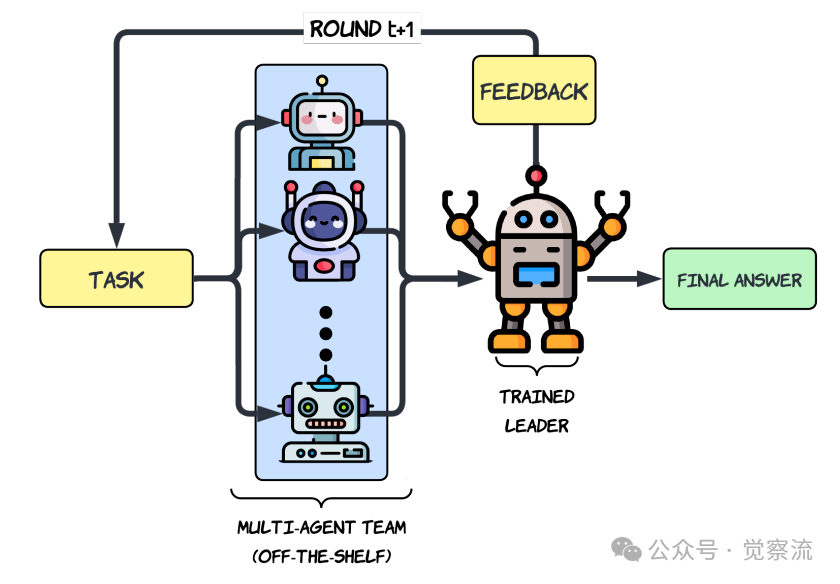
分层多智能体推理架构概览
- 初始生成(Round 0):对于给定任务 ,K个智能体模型并行地、独立地生成各自的初步解决方案 。
- 领导者聚合(Leader Aggregation):领导者模型 接收任务 和所有智能体的初步响应 ,生成一个结构化的输出 。该输出被强制分为两个部分:
<think>标签内的详细推理链,和<answer>标签内的最终答案。 - 智能体修订(Agent Revision):在后续轮次(),每个智能体会基于原始任务 、自身的上一轮答案 以及领导者的上一轮输出 ,来修订和改进自己的答案,即 。
- 循环精炼:领导者再次聚合更新后的智能体答案,生成新的 。这个过程循环往复,直到第 轮结束,最终答案从领导者最后一次输出中提取。
这一流程的关键设计在于其结构化输出和闭环反馈机制。结构化输出强制领导者分离思考与结论,便于监督学习和优势估计。闭环反馈则使领导者不仅是被动的"聚合器",更扮演了主动的"导师"角色,其输出为智能体提供了改进方向,从而引导整个团队向更优解收敛。
为实现上述结构化输出,领导者和智能体均采用精心设计的提示词(Prompt)。领导者被明确要求先进行详细的"思考"(<think>),再给出"答案"(<an
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









