




 Apache Storm是一个开源的分布式实时计算系统,用于处理无界的数据流。与Hadoop的离线计算不同,Storm专注于实时计算,数据保存在内存中,支持实时收集、计算和展示。本文介绍了Storm的概述、基础知识、集群搭建、常用API以及分组策略和并发度,通过案例展示了其在实时分析、网站性能监控等场景的应用。
Apache Storm是一个开源的分布式实时计算系统,用于处理无界的数据流。与Hadoop的离线计算不同,Storm专注于实时计算,数据保存在内存中,支持实时收集、计算和展示。本文介绍了Storm的概述、基础知识、集群搭建、常用API以及分组策略和并发度,通过案例展示了其在实时分析、网站性能监控等场景的应用。
目录
4.2.3 需求2:动态增加日志,查看控制台打印信息(tail特性)
1 Storm概述
1.1 离线计算是什么?
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据
1.2 流式计算是什么?
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
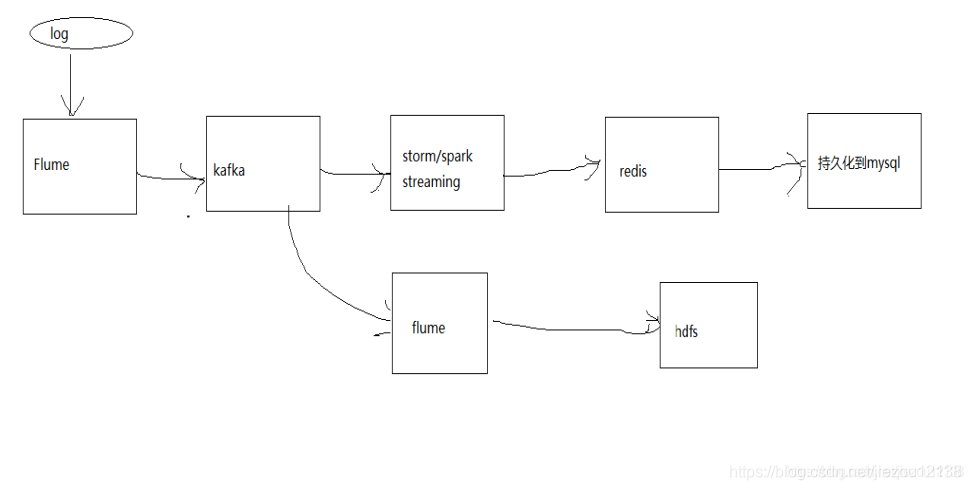
代表技术:Flume实时获取数据、Kafka实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
离线计算与实时计算最大的区别:实时收集、实时计算、实时展示
实时流处理架构
1.3 Storm是什么?
Storm是一个分布式计算框架,主要使用Clojure与Java语言编写,最初是由Nathan Marz带领Backtype公司团队创建,在Backtype公司被Twitter公司收购后进行开源。最初的版本是在2011年9月17日发行,版本号0.5.0。
2013年9月,Apache基金会开始接管并孵化Storm项目。Apache Storm是在Eclipse Public License下进行开发的,它提供给大多数企业使用。经过1年多时间,2014年9月,Storm项目成为Apache的顶级项目。
Storm是一个免费开源的分布式实时计算系统。Storm能轻松可靠地处理无界的数据流,就像Hadoop对数据进行批处理;
1.4 Storm与Hadoop的区别
1)Storm用于实时计算,Hadoop用于离线计算。
2)Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批处理(批处理)。
3)Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
1.5 Storm应用场景及行业案例
Storm用来实时计算源源不断产生的数据,如同流水线生产。
1.5.1 运用场景
Storm能用到很多场景中,包括:实时分析、在线机器学习、连续计算等。
1)推荐系统:实时推荐,根据下单或加入购物车推荐相关商品
2)金融系统:实时分析股票信息数据
3)预警系统:根据实时采集数据,判断是否到了预警阈值。
4)网站统计:实时销量、流量统计,如淘宝双11效果图
1.5.2 典型案列
1)京东-实时分析系统:实时分析用户的属性,并反馈给搜索引擎
最初,用户属性分析是通过每天在云上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
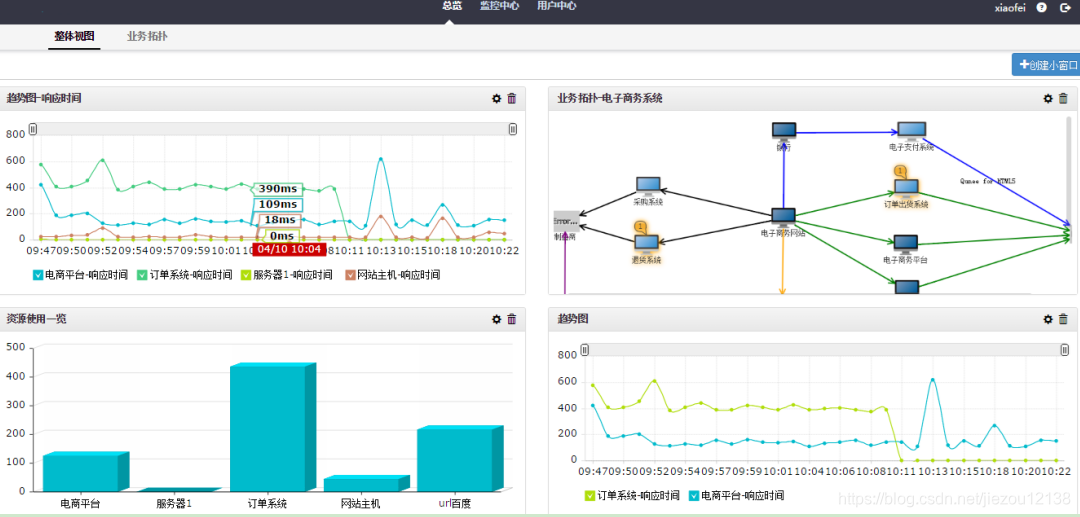
2)携程-网站性能监控:实时分析系统监控携程网的网站性能
利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
3)淘宝双十一:实时统计销售总额

2 Storm基础知识
2.1 Storm编程模型
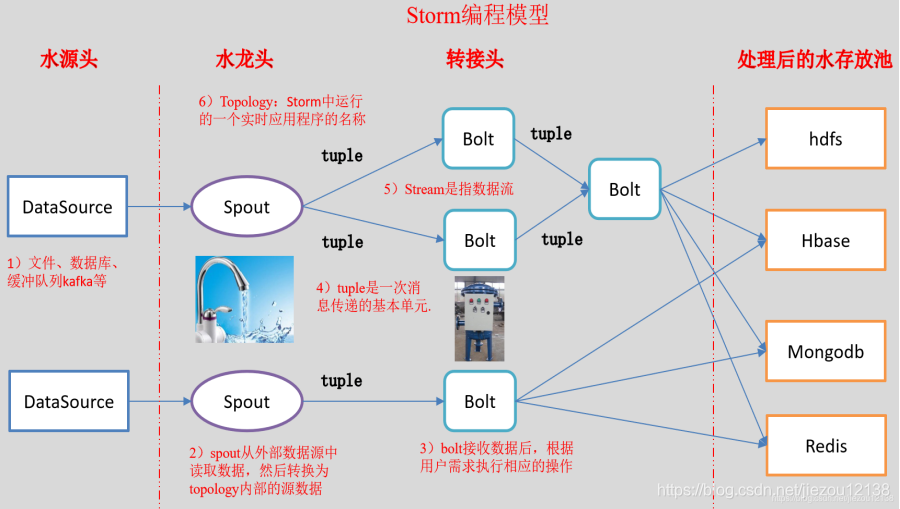
编程模型中组件介绍:
1. 元组(Tuple)
元组(Tuple),是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个value的List。
2. 流(Stream)
流是Storm的核心抽象,是一个无界的元组系列。源源不断传递的元组就组成了流,在分布式环境中并行地进行创建和处理。
3. 水龙头(Spout)
Spout是拓扑的流的来源,是一个拓扑中产生源数据流的组件。通常情况下,Spout会从外部数据源中读取数据,然后转换为拓扑内部的源数据。
Spout可以是可靠的,也可以是不可靠的。如果Storm处理元组失败,可靠的Spout能够重新发射,而不可靠的Spout就尽快忘记发出的元组。
Spout可以发出超过一个流。
Spout的主要方法是nextTuple()。NextTuple()会发出一个新的Tuple到拓扑,如果没有新的元组发出,则简单返回。
Spout的其他方法是ack()和fail()。当Storm检测到一个元组从Spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。Ack()和fail()仅被可靠的Spout调用。
IRichSpout是Spout必须实现的接口。
4. 转接头(Bolt)
在拓扑中所有处理都在Bolt中完成,Bolt是流的处理节点,从一个拓扑接收数据,然后执行进行处理的组件。Bolt可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。
Bolt是一个被动的角色,接口中有一个execute()方法,在接收到消息后会调用此方法,用户可以在其中执行自己希望的操作。
Bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个Bolt。
Bolt可以发出超过一个的流。
5. 拓扑(Topology)
拓扑(Topology)是Storm中运行的一个实时应用程序,因为各个组件间的消息流动而形成逻辑上的拓扑结构。
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑。Storm的拓扑类似于MapReduce的作业(Job)。其主要的区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
2.2 Storm核心组件
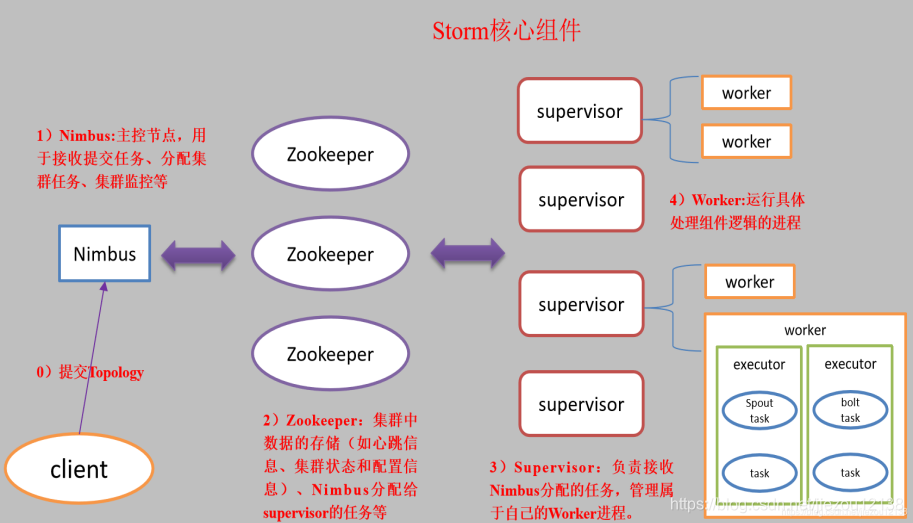
nimbus是整个集群的控管核心,负责topology的提交、运行状态监控、任务重新分配等工作。
zk就是一个管理者,监控者。
总体描述:nimbus下命令(分配任务),zk监督执行(心跳监控,worker、supurvisor的心跳都归它管),supervisor领旨(下载代码),招募人马(创建worker和线程等),worker、executor就给我干活!task就是具体要干的活。
1 主控节点与工作节点
另外一种对Storm集群中节点的说法而已:从它是M/S结构而言的,不要和上面的核心组件混着认识。
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker Node)。其中,主控节点只有一个,而工作节点可以有多个。
2 Nimbus进程与Supervisor进程
主控节点运行一个称为Nimbus的守护进程。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
3 流分组(Stream grouping)
流分组,是拓扑定义中的一部分,为每个Bolt指定应该接收哪个流作为输入。流分组定义了流/元组如何在Bolt的任务之间进行分发。Storm内置了8种流分组方式。
4 工作进程(Worker)
Worker是Spout/Bolt中运行具体处理逻辑的进程。一个worker就是一个进程,进程里面包含一个或多个线程。
5 执行器(Executor)
一个线程就是一个executor,一个线程会处理一个或多个任务。
6 任务(Task)
一个任务就是一个task。
2.3 实时流计算常见框架图

1)Flume获取数据。
2)Kafka临时保存数据。
3)Storm计算数据。
4)Redis是个内存数据库,用来保存数据
3 Storm集群搭建
3.1 环境准备
| hadoop101 | hadoop102 | hadoop103 |
| zookeeper | zookeeper | zookeeper |
| storm | storm | storm |
3.2 Storm集群搭建
(1)下载:
官方网站:http://storm.apache.org/downloads.html
网盘链接:请点这里 提取码:4aez
(2)上传并安装
1)将下载的storm安装包上传到hadoop101的/opt/software/目录下,配置完成后再进行分发
2)解压安装包到指定的目录下
[root@hadoop101 software]$ tar -zxvf apache-storm-1.1.0.tar.gz -C /opt/module/
3)在storm安装目录下创建data文件夹
[root@hadoop101 apache-storm-1.1.0]# mkdir data
4)修改conf/目录下的配置文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









