




 本文详细介绍了SparkStreaming的基础知识,包括其与Storm的区别、初始设置、DStream的操作以及核心概念如transformation和action算子。此外,文章还探讨了SparkStreaming在Kafka环境下的整合,包括配置、代码实现和实际应用案例,帮助读者深入理解SparkStreaming在实时数据处理中的应用。
本文详细介绍了SparkStreaming的基础知识,包括其与Storm的区别、初始设置、DStream的操作以及核心概念如transformation和action算子。此外,文章还探讨了SparkStreaming在Kafka环境下的整合,包括配置、代码实现和实际应用案例,帮助读者深入理解SparkStreaming在实时数据处理中的应用。
目录
2.4 DStream中的transformation和action算子
2.5 Driver HA(Standalone或者Mesos)
1 什么是SparkStreaming
1.1 SparkStreaming简介、
官网:http://spark.apache.org/streaming/

特点:
- 便于使用
- 容错
- spark集成
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。

和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。

DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
Discretized Stream or DStream 是 Spark Streaming 提供的基本抽象. 它代表了一个连续的数据流, 无论是从 source(数据源)接收到的输入数据流, 还是通过转换输入流所产生的处理过的数据流. 在内部, 一个 DStream 被表示为一系列连续的 RDDs, 在一个 DStream 中的每个 RDD 包含来自一定的时间间隔的数据,所以说应用与DStream的任何操作转化在底层来说都是对于RDDs的操作:如下图所示.

1.2 SparkStreaming与Storm的区别
- Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
- Storm 的事务机制要比SparkStreaming的要完善。
- Storm支持动态资源调度。(spark1.2开始和之后也支持)
- SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
2 SparkStreaming初始
2.1 官方自带的WordCount程序
[root@hadoop103 ~]# nc -lk 9999
-bash: nc: command not found //如果出现这个提示
[root@hadoop103 ~]# yum -y install nc //安装即可

然后在另一台节点上监听hadoop103节点的9999端口,运行下面spark自带的WordCount程序
$SPARK_HOME/bin/run-example streaming.NetworkWordCount hadoop103 9999

注意:如果虚拟机的cores 只有一个,sparkstreaming的程序就不能读取数据,详解往下面看
2.2 IDEA编程
操作SparkStreaming首先导入下面的依赖
<!-- 导入SparkStreaming的依赖 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.2.0</version> </dependency>
// 配置日志的显示级别,
Logger.getLogger("org").setLevel(Level.ERROR) //具体日志信息问题:请点这里def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
val ssc: StreamingContext = new StreamingContext(sc,Seconds(2)) //Seconds() 设置一个批次的时间间隔
//读取socket端口的数据
val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103",9999)
//对读取到的数据进行处理
val result: DStream[(String, Int)] = textStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//调用action算子
result.print() //默认打印10行
//Spark Streaming 程序的必备
ssc.start()
//阻塞程序,挂起
ssc.awaitTermination()
}
2.3 StreamingContext的cores配置
如果程序给定的cores 只有一个:
// master 需要至少 2 个核, 以防止饥饿情况(starvation scenario).
val conf = new SparkConf().setMaster("local[1]").setAppName(this.getClass.getSimpleName)
//如果给一个cores,会警告如下:
19/04/06 13:38:27 WARN StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
一个StreamingContext创建多个input Dstream,会创建多个Receiver,Spark会为每个Receiver 分配一个core用于其运行。
故若SparkStreaming 程序一共分配了k个core,运行n个Receiver,应保证k>n,这时会有n个core用于运行Receiver接收外部数据,k-n个core用于真正的计算。
一个Receiver 占用了一个core,这里两个Receiver占用了2个core,如果这个job的启动资源是 --master "local[4]" 那么真正能用于运算的core只有两个了。
val ssc: StreamingContext = new StreamingContext(sc,Seconds(2))
// 读取socket端口的数据, 需要一个cores
val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103",9999)
// 占用一个cores
val textStream2: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102",9999)
2.4 DStream中的transformation和action算子
2.4.1 transformation算子
lazy执行,生成新的DStream算子,一些常用的转换算子
| transform(func) | 通过对源 DStream 的每个 RDD 应用 RDD-to-RDD 函数 |

无状态转化:
比如:map(),flatMap(),filiter(),repartition()
有状态转化
updateStateByKey
作用:
- 为SparkStreaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是一个自定义的对象,更新函数也可以是自定义的。
- 通过更新函数对该key的状态不断更新,对于每个新的batch(时间片段)而言,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新。
使用到updateStateByKey要开启checkpoint机制和功能。
多久会将内存中的数据写入到磁盘一份?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StateFulWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)
val ssc = new StreamingContext(conf,Seconds(3))
//设置checkpoint路径(持久化)
ssc.checkpoint("spark_day01/WordCount")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103",9999)
val pairs = lines.flatMap(_.split(" ")).map((_,1))
//val result = pairs.reduceByKey(_+_)
//使用updateStateByKey替换reduceBykey来更新状态,统计从运行开始以来单词总的次数
val result: DStream[(String, Int)] = pairs.updateStateByKey(updateFunc)
result.print()
ssc.start()
ssc.awaitTermination()
}
//定义更新状态方法,参数values为当前批次单词频度,state为以往批次单词的频度
def updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
}
窗口操作
窗口操作理解图
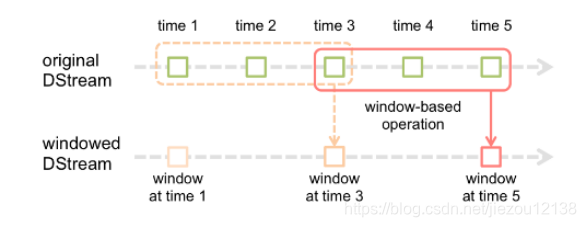
假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。(即每隔10s打印一次窗口内聚合的结果)
- 窗口长度和滑动间隔必须是batchInterval的整数倍。如果不是整数倍会检测报错。
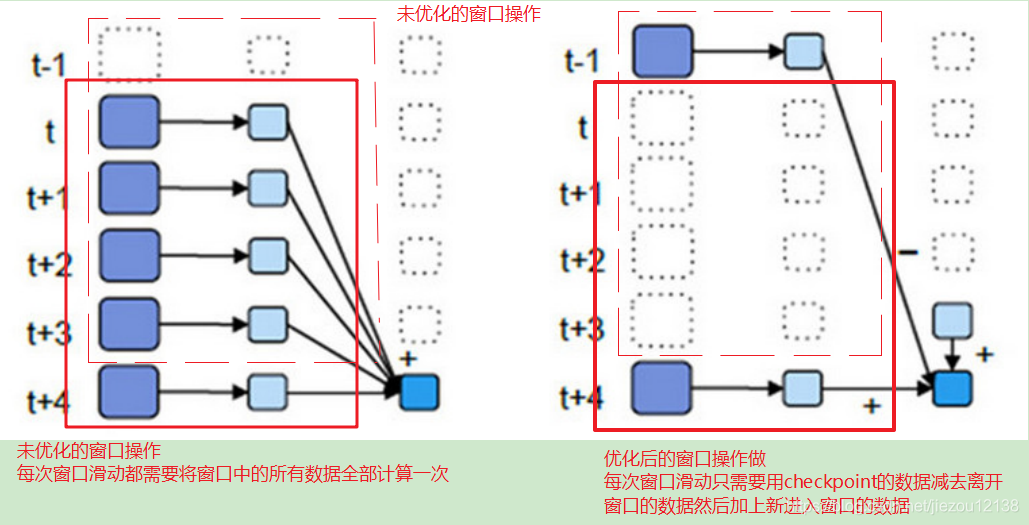
- 优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
- 优化后的window窗口操作示意图:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(3))
//设置持久化checkpoint的路径
ssc.checkpoint("spark_day01/WordCount1")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 9999)
val pairs: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
//窗口大小为9s,步长为6s
//无优化的窗口操作,当使用无优化的窗口操作可以不设置checkpoint
//val stateDStream: DStream[(String, Int)] = pairs.reduceByKeyAndWindow(
// (a: Int,b: Int) => a + b,Seconds(9),Seconds(6))
//使用窗口操作进行优化,把单词作为key,次数作为value,会把输入的所有单词当前窗口状态输出
val stateDStream: DStream[(String, Int)] = pairs.reduceByKeyAndWindow(
(a: Int, b: Int) => a + b, (a: Int, b: Int) => a - b, Seconds(9), Seconds(6))
stateDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
2.4.2 action算子
一些常用的action算子,只有当触发action算子后才会执行任务。

2.5 Driver HA(Standalone或者Mesos)
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要(如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式)。Yarn平台cluster模式提交任务,AM(AplicationMaster)相当于Driver,如果挂掉会自动启动AM。这里所说的DriverHA针对的是Spark standalone和Mesos资源调度的情况下。实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
Driver中元数据包括:
- 创建应用程序的配置信息。
- DStream的操作逻辑。
- job中没有完成的批次数据,也就是job的执行进度。
3.kafka
3.1 简介:
Apache Kafka是分布式发布-订阅消息系统(分布式消息队列)。特点是生产者消费者模式,先进先出(FIFO)保证顺序,自己不丢数据,默认每隔7天清理数据。消息列队常见场景:系统之间解耦合、峰值压力缓冲、异步通信。
MQ: message queue
传统消息中间件服务RabbitMQ、Apache ActiveMQ(免费)等。IBMMQ (收费)
Apache Kafka与传统消息系统相比,有以下不同:
- 它是分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
3.2 kafka中的术语
| 术语 | 解释 |
| Broker | Kafka集群包含一个或多个服务器,这种服务器被称为broker |
| Topic
| 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) |
| Partition | Partition是物理上的概念,每个Topic包含一个或多个Partition. |
| Producer | 负责发布消息到Kafka broker |
| Consumer | 消息消费者,向Kafka broker读取消息的客户端 |
| Consumer Group | 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group) |
| replica | partition 的副本,保障 partition 的高可用 |
| leader | replica 中的一个角色, producer 和 consumer 只跟 leader 交互 |
| follower | replica 中的一个角色,从 leader 中复制数据 |
| controller | Kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover |
3.3 kafka集群的部署
- 上传kafka_2.10-0.8.2.2.tgz包到三个不同节点上,解压。
- 配置../ kafka_2.10-0.8.2.2/config/server.properties文件
-
broker.id=1
delete.topic.enable=true
listeners=PLAINTEXT://hadoop101:9092
log.dirs=/opt/module/kafka_2.11-0.11.0.0/logs/
num.partitions=3
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181





-
- 分发安装包,然后修改broker.id以及listeners
- 启动zookeeper集群。
- 在三个节点上启动kafka
bin/kafka-server-start.sh config/server.properties
- kafka相关命令
创建topic:
./kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --create --topic first --partitions 3 --replication-factor 3
用一台节点控制台来当kafka的生产者:
./kafka-console-producer.sh --topic topic2017 --broker-list hadoop101:2181,hadoop102:2181,hadoop103:2181
用另一台节点控制台来当kafka的消费者:
./kafka-console-consumer.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic first
查看kafka中topic列表:
./kafka-topics.sh --list --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181
查看kafka中topic的描述:
./kafka-topics.sh --describe --zookeeper node3:2181,node4:2181,node5:2181 --topic first
查看zookeeper中topic相关信息:
启动zookeeper客户端:
./zkCli.sh
查看topic相关信息:
ls /brokers/topics/
查看消费者相关信息:
ls /consumers
删除kafka中的数据
./kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --delete --topic first
在每台broker节点上删除当前这个topic对应的真实数据。
进入zookeeper客户端,删除topic信息
rmr /brokers/topics/first
删除zookeeper中被标记为删除的topic信息
rmr /admin/delete_topics/first
4 SparkStreaming+kafka
4.1 streaming和kafka整合
官方文档:http://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
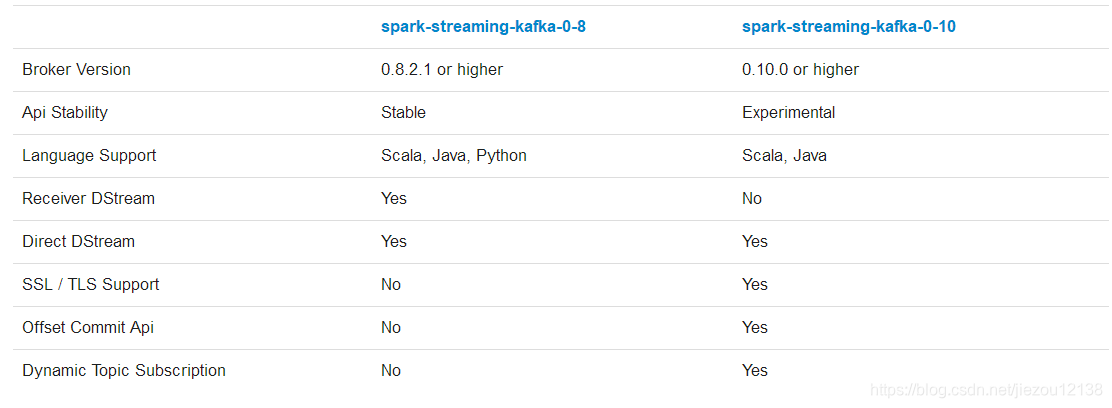
在kafka0-10版本已经不再支持receiver DStream模式
导入下面的依赖:
<!--streaming 集成 kafka的依赖jar包--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.2.0</version> </dependency>
val kafkaParams = Map[String, Object](
//要连接的 服务器:端口号
"bootstrap.servers" -> "Hadoop101:9092,hadoop102:9092,hadoop103:9092",//设置消费(k,v)格式的数据类型
//rdd中的数据类型是 ConsumerRecord[数据类型, 数据类型]
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],//消费者组
"group.id" -> "hello_topic_group",//可以设置从哪里读取数据
"auto.offset.reset" -> "earliest",// 是否可以自动提交偏移量 自定义
"enable.auto.commit" -> (false: java.lang.Boolean)
)
4.2 代码实现
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object SparkAndKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "hadoop101:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//可以设置读取多个主题
val topics = Array("first","second")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
//在可用的executors上均匀分区
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
rdd.foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}
groupId:
同一个组中,可以有多个consumer,但是多个consumer只能消费不同分区的数据,
也就是说一条数据,只能被一个consumer去消费。
还可以为每一个group中的consumer指定一个名称,即group.name
4.3 streaming-kafka-wordcount
在hadoop101节点启动kafka生产者,向topic second中写数据

在hadoop102节点上向主题first中写入数据

在IDEA中编写程序,主题first和second中的数据
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object SparkAndKafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
val ssc= new StreamingContext(conf,Seconds(2))
// kafka的参数配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "hadoop101:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "hello_topic_group",
// 从哪个位置开始读取数据
"auto.offset.reset" -> "earliest",
// 是否可以自动提交偏移量 自定义
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// streaming 支持 读取kafka的多个主题
val topics = Array("second")
// 指定泛型约定
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
// 我们的broker和executor在同一台机器上
// LocationStrategies.PreferBrokers
// 资源会平均分配
LocationStrategies.PreferConsistent,
// PreferConsistent,
// 消费者 订阅哪些主题
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd=>{
// rdd中的数据类型是 ConsumerRecord[String, String] 拿到这里的value
val result = rdd.flatMap(_.value().split(" ")).map((_,1)).reduceByKey(_+_)
result.foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









