




数组的定义(内容均可变)
1.定长数组(默认情况)
| // 定义定长数组, 长度不可变, 内容可变 var x :Array[String] = new Array[String](3) // 或者 var y = new Array[String](3) // 使用new的时候,小括弧中的3代表的是数组的长度,如果不加new,3就是数组中的元素 val z = Array (1,2,3) // 修改第 0 个元素的内容 z (0) = 100 |
//初始化一个长度为 8 的定长数组,其所有元素均为 0
val arr1 = new Array[Int](8)
//直接打印定长数组,内容为数组的 hashcode 值
println (arr1)
//将数组转换成数组缓冲,就可以看到原数组中的内容了
//toBuffer 会将数组转换长数组缓冲
println (arr1.toBuffer)
//定义一个长度为 3 的定长数组
val arr3 = Array ( "hadoop", "storm", "spark")
//使用()来访问元素
println (arr3(2))2.变长数组
import scala.collection.mutable.ArrayBuffer
object ArrayTest {
def main(args: Array[String]) {
//变长数组(数组缓冲)
//如果想使用数组缓冲,需要导入 import scala.collection.mutable.ArrayBuffer包
val ab = ArrayBuffer[Int]()
//向数组缓冲的尾部追加一个元素
//+=尾部追加元素
ab += 1
//追加多个元素
ab += (2, 3, 4, 5)
//追加一个数组++=
ab ++= Array (6, 7)
//追加一个数组缓冲
ab ++= ArrayBuffer(8,9)
//打印数组缓冲 ab
//在数组某个位置插入元素用 insert,第一个参数代表插入数据的索引位置,后面的参数都是要插入的数据
ab.insert(0, -1, 0)
//删除数组某个位置的元素用 remove,第一个参数代表删除动作从哪个索引位置开始,第二个参数代表要删除几个元素
ab.remove(8, 2)
println (ab)
}
}map|flatten|flatMap|foreach
// 定义一个数组
val array = Array [Int](2,4,6,9,3)
// map 方法是将 array 数组中的每个元素进行某种映射操作, (x: Int) => x * 2 为
//一个匿名函数, x 就是 array 中的每个元素
val y = array map((x: Int) => x * 2)
// 或者这样写, 编译器会自动推测 x 的数据类型
val z = array .map(x => x*2)
// 亦或者, _ 表示入参, 表示数组中的每个元素值
val x = array .map(_ * 2)
println ( x .toBuffer)
// 定义一个数组
val words = Array ("hello m tom o hello m jim o hello jerry", "hello Hatano")
// 将数组中的每个元素进行分割
// Array(Array(hello, tom, hello, jim, hello, jerry), Array(hello,Hatano))
val splitWords : Array[Array[String]] = words .map(wd => wd.split(" "))
// 此时数组中的每个元素进过 split 之后变成了 Array, flatten 是对 splitWords
//里面的元素进行扁平化操作
// Array(hello, tom, hello, jim, hello, jerry, hello, Hatano)
val flattenWords = splitWords .flatten
// 上述的 2 步操作, 可以等价于 flatMap, 意味先map 操作后进行 flatten 操作
val result : Array[String] = words .flatMap(wd => wd.split(" "))
// 遍历数组, 打印每个元素
result .foreach( println)WordCount案例:(重点理解)
val words = Array("hello scala", "hello spark", "hello java")
//将字符串切分
val arr1: Array[Array[String]] = words.map(_.split(" "))
//扁平化处理
val arr2: Array[String] = arr1.flatten
//根据单词分组
val arr3: Map[String, Array[String]] = arr2.groupBy(x => x)
//求出每个分组的长度并转化为List
val list: List[(String, Int)] = arr3.mapValues(_.length).toList
//根据每个元组的第二个元素降序输出
println(list.sortBy(x => -x._2))
//输出结果:List((hello,3), (spark,1), (scala,1), (java,1))集合的使用
Scala 的集合有三大类:序列 Seq(List)、集 Set、映射 Map,在 Scala 中集合有可变(mutable)和不可变(immutable)两种类型,immutable 类型的集合初始化后就不能改变了(注意与 val 修饰的变量进行区别)
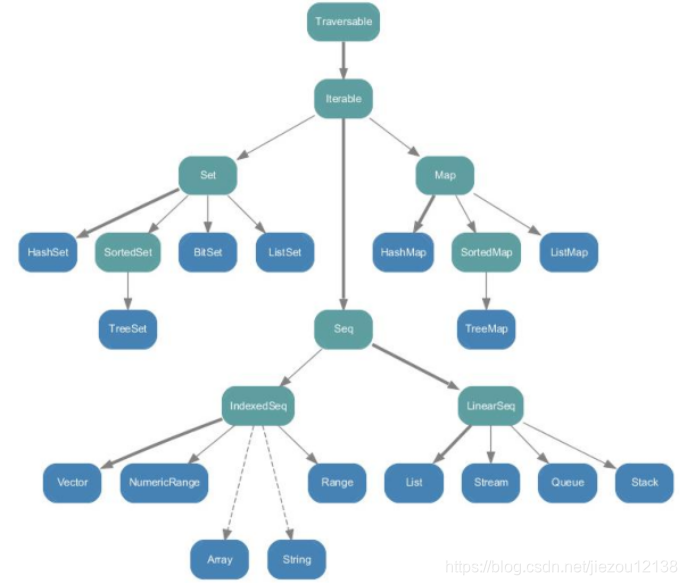 |
对于集合
可变集合:长度可变,内容可变;
不可变集合:长度不可变,内容也不可变;
在开始学习集合之前,先了解一下一些特殊的符号(方法)
详细的讲解看我另一篇文章:https://blog.youkuaiyun.com/jiezou12138/article/details/88703309
| (对两个集合/数组的操作) ++ ++: ::: 三个方法均为拼接作用 ::: 方法只能用于集合 (对列表追加元素) 在列表1头部插入元素 +: 在列表1的头部添加一个元素 :: 在列表1的头部添加一个元素 在列表1的尾部插入元素 :+ 在列表1的尾部添加一个元素 |
| (1) :: 该方法被称为cons,意为构造,向队列的头部追加数据,创造新的列表。用法为 x::list,其中x为加入到头部的元素,无论x是列表与否,它都只将成为新生成列表的第一个元素,也就是说新生成的列表长度为list的长度+1(btw, x::list等价于list.::(x)) (2) :+和+: 两者的区别在于:+方法用于在尾部追加元素,+:方法用于在头部追加元素,和::很类似,但是::可以用于pattern match ,而+:则不行. 关于+:和:+,只要记住冒号永远靠近集合类型就OK了。 (3) ++ 该方法用于连接两个集合,list1++list2 (4) ::: 该方法只能用于连接两个List类型的集合 |
1.Seq序列(List)
默认创建的序列(List)为immutable,创建可变数组需要导入scala.collection.mutable.*包
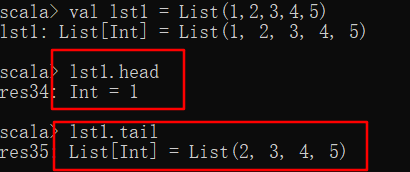
在Scala中序列要不为空(Nil表示空列表),要么就是一个head元素加上一个tail列表
不可变序列使用一些特殊的符号(方法)
object ImmutListTest {
def main(args: Array[String]) {
//创建一个不可变的集合
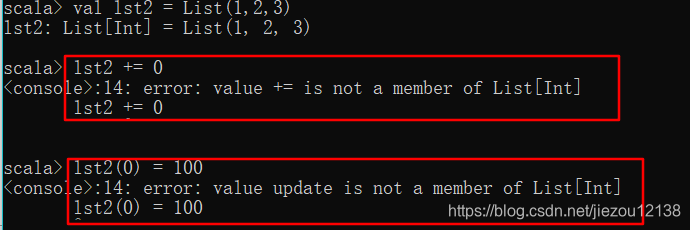
val lst1 = List (1,2,3)
//将 0 插入到 lst1 的前面生成一个新的 List
val lst2 = 0 :: lst1
val lst3 = lst1.::(0)
val lst4 = 0 +: lst1
val lst5 = lst1.+:(0)
//将一个元素添加到 lst1 的后面产生一个新的集合
val lst6 = lst1 :+ 3
val lst0 = List (4,5,6)
//将 2 个 list 合并成一个新的 List
val lst7 = lst1 ++ lst0
val lst8 = lst1 ++: lst0
val lst9 = lst1.:::(lst0)
println (lst9)
}
}注意::: 操作符是右结合的,如 9 :: 5 :: 2 :: Nil 相当于 9 :: (5 :: (2 :: Nil))
可变的序列:
import scala.collection.mutable.ListBuffer
object MutListTest extends App{
//构建一个可变列表,初始有 3 个元素 1,2,3
val lst0 = ListBuffer[Int](1,2,3)
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向 lst1 中追加元素,注意:没有生成新的集合
lst1 += 4
lst1 .append(5)
//将 lst1 中的元素最近到 lst0 中, 注意:没有生成新的集合
lst0 ++= lst1
//将 lst0 和 lst1 合并成一个新的 ListBuffer 注意:生成了一个集合
val lst2 = lst0 ++ lst1
//将元素追加到 lst0 的后面生成一个新的集合
val lst3 = lst0 :+ 5
}
2 Set集
特点:无序且没有重复
不可变的set
import scala.collection.immutable.HashSet
object ImmutSetTest extends App{
val set1 = new HashSet[Int]()
//set 中元素不能重复
val set3 = set1 ++ Set (5, 6, 7)
val set0 = Set (1,3,4) ++ set1
println ( set0 .getClass)
}可变的set
import scala.collection.mutable
object MutSetTest extends App{
//创建一个可变的 HashSet
val set1 = new mutable.HashSet[Int]()
//向 HashSet 中添加元素
set1 += 2
//add 等价于+=
set1 .add(4)
set1 ++= Set (1,3,5)
println ( set1 )
//删除一个元素
set1 -= 5
set1 .remove(2)
println ( set1 )
}
18.3Map映射
import scala.collection.mutable
object MutMapTest extends App {
val map1 = new mutable.HashMap[String, Int]()
//向 map 中添加数据
map1.put("storm", 3)
map1("spark") = 1
map1 += (("hadoop", 2))
println ( map1 )
// 取值 get getOrElse()
//从 map 中移除元素
map1 -= "spark"
map1 .remove( "hadoop")
println ( map1 )
}元组
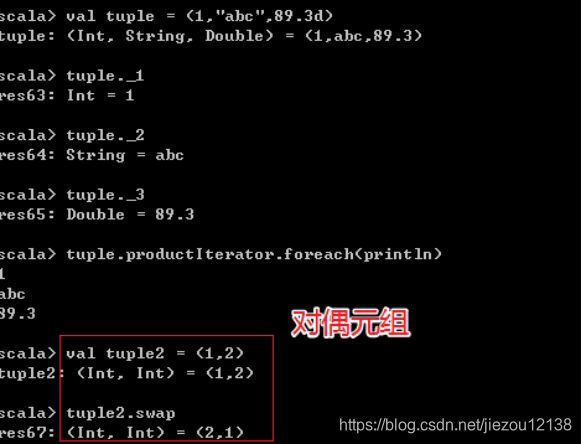
Scala 元组将固定数量的项目组合在一起,以便它们可以作为一个整体传递。与数组或列表不同,元组可以容纳不同类型的对象,但它们也是不可变的。
// 定义元组
var t = (1, "hello", true)
// 或者
val tuple3 = new Tuple3(1, "hello", true)
// 访问 tuple 中的元素
println ( t ._2) // 访问元组总的第二个元素 (注意:位置索引从1开始)
// 迭代元组
t .productIterator.foreach( println )
// 对偶元组(两个数据的元组)
val tuple2 = (1, 3)
// 交换元组的元素位置, tuple2 没有变化, 生成了新的元组
val swap = tuple2 .swap
集合中常用的方法
map,flatten,flatMap 之前介绍过就不再赘述
filter(过滤作用→闯入函数进行过滤)
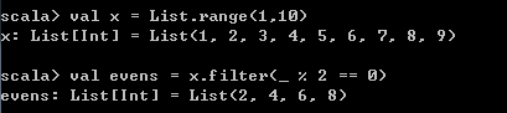
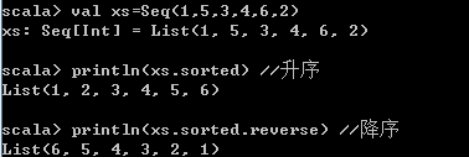
sorted(对一个集合进行自然排序)
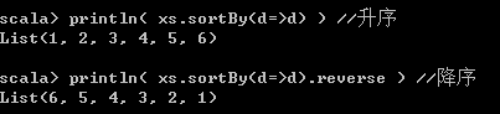
sortBy
fold(折叠), foldLeft, foldRight
|
|
定义两个list:
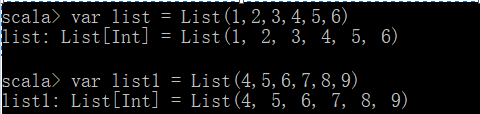
reduce(归约,根据传入的函数合并)
union(求并集)
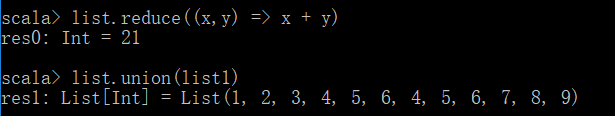
intersect(交集)

diff(差集,相对的)
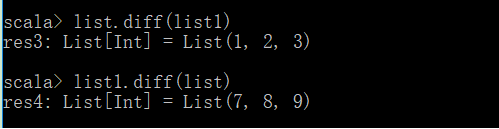
注意:diff是相对的,list.diff(list1)会打印出list集合中排除掉两者交集部分的数据
zip(拉链,对应角标配成元组)

mkString

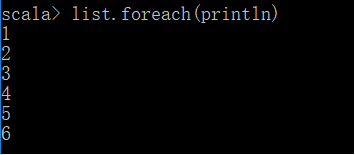
foreach
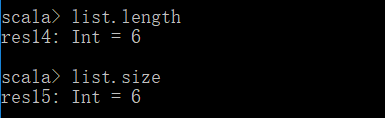
Length/size
Map和Option
在 Scala中Option 类型样例类用来表示可能存在或也可能不存在的值(Option 的子类有Some和None)。Some 包装了某个值,None 表示没有值
// Option 是 Some 和 None 的父类
// Some 代表有
// None 代表没有
val mp = Map ("a" -> 1, "b" -> 2, "c" -> 3)
val r: Int = mp("d")
// Map 的 get 方法返回的为 Option, 也就意味着 rv 可能取到也有可能没取到
val rv: Option[Int] = mp.get("d")
val r1 = rv.get
// 使用 getOrElse 方法,
// 第一个参数为要获取的 key,
// 第二个参数为默认值, 如果没有获取到 key 对应的值就返回默认值
val r2 = mp.getOrElse("d", -1)
println (r2)

















 10
10

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









