




垃圾邮件是指批量发送给用户的未经请求或不受欢迎的消息/电子邮件。在大多数消息/电子邮件服务中,消息会自动检测为垃圾邮件,这样这些消息就不会不必要地涌入用户的收件箱。这些消息通常是促销性的和奇特的。因此,我们可以构建可以检测垃圾邮件的 ML/DL 模型。
在 Python 中使用 Tensorflow 检测垃圾邮件
在本文中,我们将构建一个基于 TensorFlow 的垃圾邮件检测器;简单来说,我们将不得不将文本分类为 Spam 或 Ham。 这意味着 Spam detection 是 Text Classification 问题的一个例子。因此,我们将对数据集执行 EDA 并构建文本分类模型。
导入库
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
熊猫 – 该库有助于以 2D 数组格式加载数据帧,并具有多种功能可以一次性执行分析任务。
Numpy – Numpy 数组速度非常快,可以在很短的时间内执行大型计算。
Matplotlib/Seaborn/Wordcloud– 此库用于绘制可视化。
NLTK – Natural Language Tool Kit 提供了各种功能来处理原始文本数据。
- Python3 语言
# Importing necessary libraries for EDA
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import string
import nltk
from nltk.corpus import stopwords
from wordcloud import WordCloud
nltk.download('stopwords')
# Importing libraries necessary for Model Building and Training
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
import warnings
warnings.filterwarnings('ignore')
|
加载数据集
现在,让我们将数据集加载到 pandas 数据帧中,并查看数据集的前五行。数据集链接 – [电子邮件]
- Python3 语言
data = pd.read_csv('Emails.csv')
data.head()
|
输出:

数据集的前五行
为了检查我们拥有多少这样的推文数据,让我们打印数据框的形状。
- Python3 语言
data.shape
|
输出:
(5171, 2)
为了更好地理解,我们将绘制这些计数:
- Python3 语言
sns.countplot(x='spam', data=data)
plt.show()
|
输出:
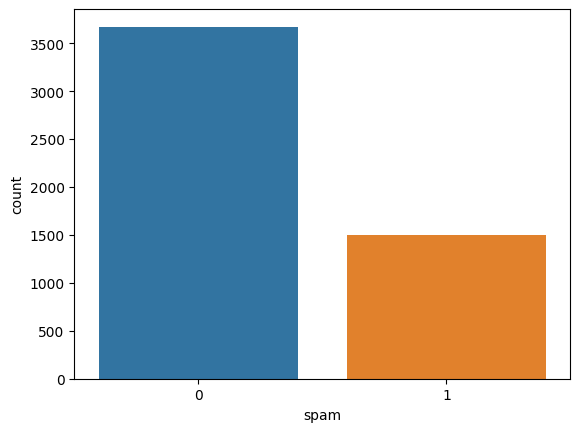
垃圾邮件标签的计数图
我们可以清楚地看到,Ham 的样本数量远多于 Spam 的样本数量,这意味着我们使用的数据集是不平衡的。
- Python3 语言
# Downsampling to balance the dataset
ham_msg = data[data.spam == 0]
spam_msg = data[data.spam == 1]
ham_msg = ham_msg.sample(n=len(spam_msg),
random_state=42)
# Plotting the counts of down sampled dataset
balanced_data = ham_msg.append(spam_msg)\</
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











