




 本文介绍Skip-gram模型的实现方式及如何利用负采样进行计算加速。通过负采样,我们可以将多分类任务转化为二分类任务,显著提高模型训练效率。
本文介绍Skip-gram模型的实现方式及如何利用负采样进行计算加速。通过负采样,我们可以将多分类任务转化为二分类任务,显著提高模型训练效率。
Skip-gram的算法实现
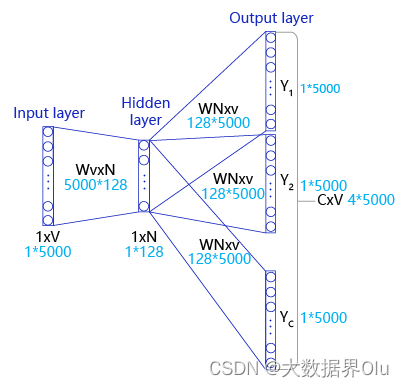
Skip-gram的实际实现
在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W非常大。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务。
假设有一个中心词c和一个上下文词正样本tp。在Skip-gram的理想实现里,需要最大化使用c推理tp的概率。在使用softmax学习时,需要最大化tp 的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
- 代表中心词的tensor:假设我们称之为center_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
- 代表目标词的tensor:假设我们称之为target_words TTT,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
- 代表目标词标签的tensor:假设我们称之为labels LLL,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
过程与使用CBOW类似,只有构造训练数据时的操作不同
笔记&实践 | 基于CBOW实现Word2Vec
#构造数据,准备模型训练
#max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
#negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
#一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3,
negative_sample_num =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









