



 本文探讨了mysql中加了索引却不被使用的情况,包括查询条件涉及函数、隐式类型转换、特殊修饰符如%和OR、以及索引优化器的选择。索引优化器根据区分度估算最佳执行方案,基数小可能导致不走索引。通过force index可强制使用特定索引。了解这些原理有助于避免查询性能问题。
本文探讨了mysql中加了索引却不被使用的情况,包括查询条件涉及函数、隐式类型转换、特殊修饰符如%和OR、以及索引优化器的选择。索引优化器根据区分度估算最佳执行方案,基数小可能导致不走索引。通过force index可强制使用特定索引。了解这些原理有助于避免查询性能问题。

小白白跑去鹅厂面试,面试官提出了一个很实际的问题: mysql增加索引,那些情况会失效呢?谈一下实际工作中遇到的情况。我们的小白白又抛出了白氏秘籍:用不用索引,找DBA小姐姐!啊?这是你面试哈,还是DBA小姐姐面试呀。(更多信息,请关注微信公众号: 白白家族)
一 概述
日常处理mysql问题中,往往通过增加索引来提高查询速度,但在有些情况下,执行过程中并没有按照我们的预期结果执行,也就是说,即使字段加了索引,但现实也没有使用到,到底是什么地方出了差错,以下我们将一探究竟。
二 实验表结构声明:
我们将对以下表结构进行实际案例分析
CREATETABLE `student` (`id` int(11) NOT NULL AUTO_INCREMENT,`age` int(11) DEFAULT 0,`name` varchar(16) DEFAULT "",key idx_age (`age`),key idx_name (`name`),PRIMARY KEY (`id`)) ENGINE=InnoDB;
三 Mysql不走索引归类以及详细解析
根据实验表做具体case分析,归纳为以下几点:
1. 查询条件在索引列上使用函数操作,或者运算的情况
例如以下case是不走索引的:
explain select * from student where abs(age) =18;explain select * from student where age + 1=18;
2. 查询条件字符串和数字之间的隐式转换
例如:name与age分别做字符串/数字(88)的隐式转换;
以下case走索引情况:
explain select * from student where name =’88’;explain select * from student where age='88';explain select * from student where age =88;
以下case不走索引情况:
explain select * from student where name=88;
3. 特殊修饰符 %%, Or 将不走索引
explain select * from student where name like'%name%' ;explain select * from student where name ='name' or age = 18;
4. 索引优化器选择最优的索引
这一点最重要,索引到底用不用,不是列加了索引就一定会用,而是根据索引优化器来决定。
索引优化器的存在,就是找到一个索引扫描行数最少的方案去执行语句。那么扫描行数怎么来判断的?是逐行统计数据表的数据吗?其实并不是,而是根据统计信息来估算的值。这个统计信息就是我们常说的索引的“区分度”。
显然,一个索引上不同的值越多,这个索引的区分度就越好。我们把一个索引上不同的值的个数,称之为“索引基数”。也就是说,基数越大,索引的区分度就越好,执行查询的行数就越少。如何查看索引基数呢?使用 show index from 表名,cardinality字段显示的就是索引的基数。
扩展:MySQL 是怎样得到索引基数的呢?不感兴趣的小伙伴可以飘过啦。
索引基数 = 采样统计*页数。采样统计就是避免把整张表取出来一行行统计做精准计算,以免消耗系统性能。在采样统计时,InnoDB默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。统计信息不是固定不变的,他会随着数据表的变化而变化。当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计。
索引优化器实例一:
经常听人说,执行<>语句时,不走索引,今天我们将看一看实际执行情况,还是那句话,到底走不走,我们说了不算,还是索引优化器说了算:
看截图 ,就会发现 <> 其实是走了索引。
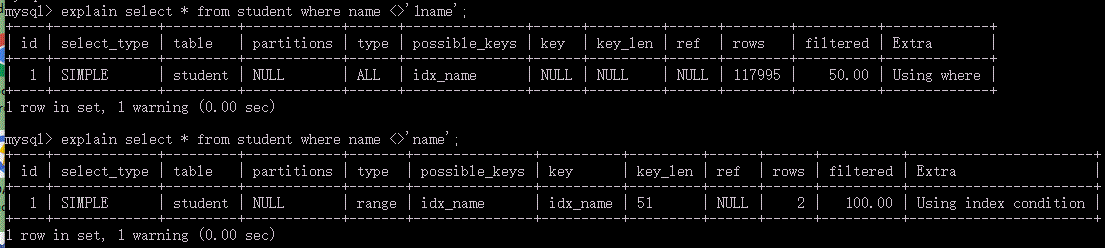
为什么会出现这样的情景呢?因为 student表中10W多条数据的值全都是'name',索引基数太小,所以在执行<>'1name'查询时,实际上要查询条数为10多W条,如果走了name字段索引,其实和全表查询没什么区别,况且,执行name字段索引,最终还是要转换为主键索引(二级索引查询都会转换为主键查询),所以索引优化器的优化结果是不走name索引。然而在执行<>'name'查询时,优化器优化结果是走name索引,因为,<>'name'的查询行数很小,大部分条数name字段的值都是'name'。
索引优化器实例二:
同理,前缀like匹配是走索引,但是,以下却展示了不一样的结果:
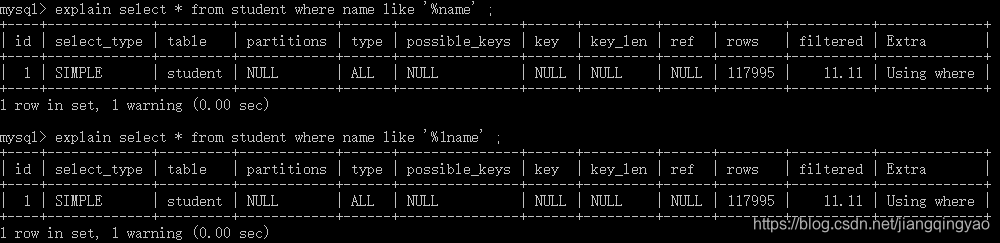
为什么会这样呢?请小伙伴们参考实例一仔细思考一下。
如何指定优化器执行固定的索引:
索引优化器的存在,我们就没办法指定强制走我们指定的索引?
答案就是通过 force index强制来实现,执行语句和分析结果如下图所示

四 总结以及实际应用
实际应用中,应该牢记上述索引优化的原则,比如在实际工作中,由于索引优化器选错索引,导致数据查询缓慢,阻塞线上业务,而当时的解决办法,就是上述文章的分析过程,以及采用force 强制索引才解决的,前车之鉴,希望广大读者避免踩坑。
更多信息请关注 微信公众号 : 白白家族
或扫描白白家族公众号二维码:

















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









